如果只是想查阅的话,可以使用我最近搞的一个查阅工具。
Demo
在做介绍之前,先展示一下我做出来的二十四史搜索主页。这个网站貌似不支持手机登录。如果能看到登录页面的话,用户名是guest,密码是guestguest。
项目是开源的,github地址是:
我们看一下这个网站界面:
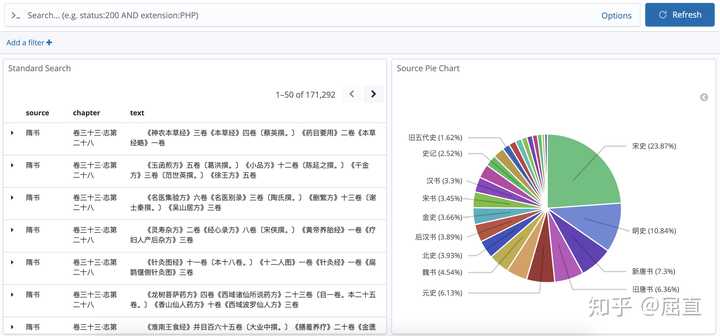
在搜索栏输入任何关键词,都会显示相关史料。我们试一下。
首先搜索”项羽“,我们看到,左边就是含有“项羽”两个字的史料段落,一共有267段。右边是“项羽”两个字在二十四史中出现的次数分布。《史记》里出现最多,占比46.44%。其次是《汉书》,占比29.96%。其他史书也多多少少提到过项羽,比如《晋书》、《南史》和《魏书》。

含有“项羽”两个字的史料段落
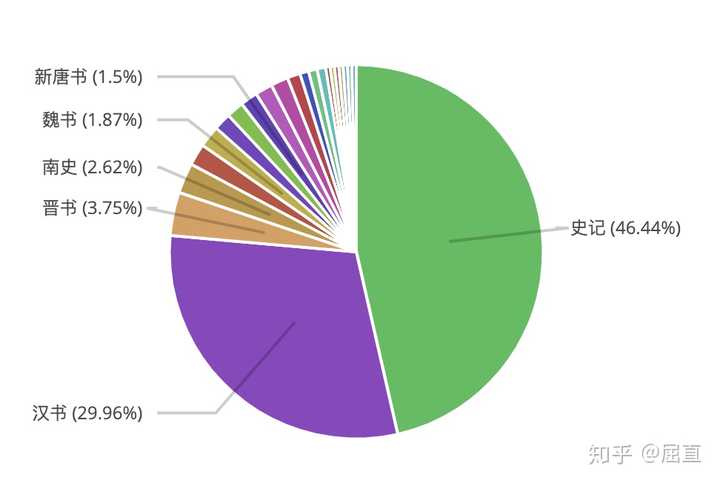
含有“项羽”两个字的史料分布
项羽出现在《史记》和《汉书》并不奇怪,因为两者都记录了项羽生活的年代。可为什么其他的史书也会提到项羽呢?
为了回答这个问题,我们加两个筛选器,把史记和汉书排除出去。
于是就得到了下面的结果。

含有“项羽”两个字的史料段落(除去史记和汉书)
第一条是《后汉书》的舆服志,提到了有一种帽子叫做“樊哙冠”。我不太懂史料,但看起来是刘邦手下大将樊哙戴的帽子。在鸿门宴上,樊哙听说项羽想要杀刘邦,于是樊哙把下衣撕下来,裹在盾牌上,用头顶着进入宴席。后来就有了这么一种造型的帽子,叫做“樊哙冠”。原来项羽对东汉的时尚产业也有贡献。

樊哙冠(《汉代服饰参考资料》)
第二条也是《后汉书》,但是是郡国志里的。易阳和襄国这两个地方过去叫做邢国,在秦朝叫做信都,后来被项羽给改了。看来项羽在地名上也留下了自己的痕迹。
第三条是《魏书》,“志第六”写的是北魏时期的地形、行政区划和人口统计。里面提到高昌这个地方有个项羽祠。
就不一个一个说了。如果你是一个研究项羽的历史学家,这些史料让你能够很方便地查到和项羽有关的史料。
我们再试试搜索一下别的东西。
我们都知道洛阳是N朝古都。这个N,有人说是九,有人说是十三。不管是几朝古都,洛阳肯定在史料中出现次数很多吧!

含有洛阳的史料条目
果然,含有洛阳的段落数有2311段。
写到洛阳最多的竟然是《晋书》,竟然占二十四史的11.99%。看来,洛阳在晋朝的存在感很高。想想也挺合理,八王之乱争夺的焦点就是洛阳,司马ABCD们主要在这儿打仗,史官肯定得好好写写。
《北史》提到洛阳第二多,占二十四史的11.64%。我对北魏的历史非常不熟,看来北魏历史上,洛阳也是新闻最多的地方。

游戏“全面战争·三国”的扩展包“八王之乱”
能不能搜一些奇奇怪怪的东西呢?
前几天看了一个关于世界纹身史的视频,二十四史对纹身有没有记载呢?
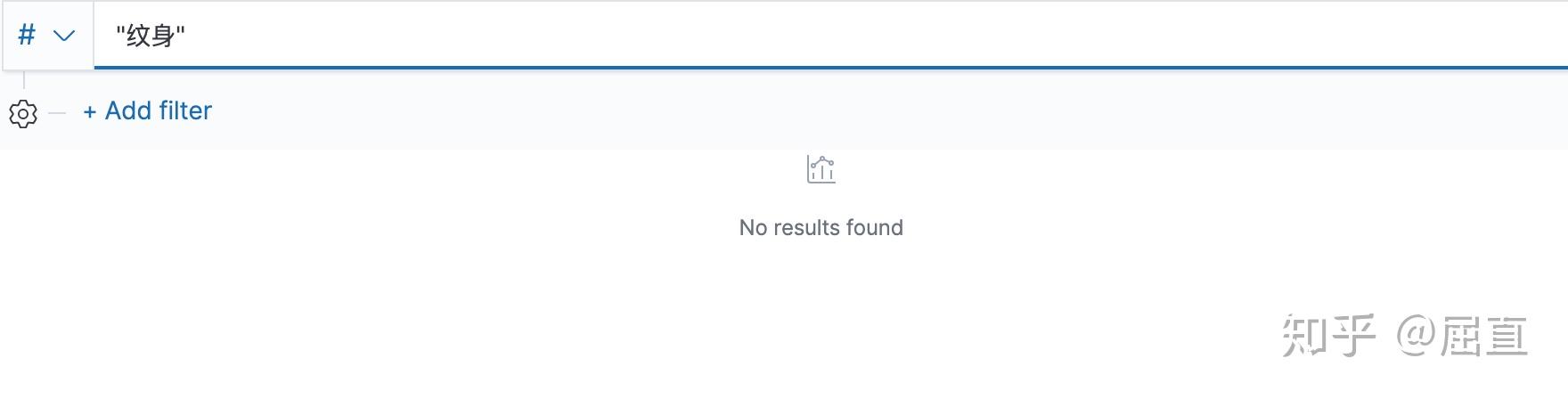
果然没有。
为什么呢?因为古代基本不用“纹”这个字,而是用“文”。《礼记·王制》里面写:“东方曰夷,被发文身,有不火食者矣。” 所以正确的做法是搜索“文身”。果然,提到“文身”的史料有54段。
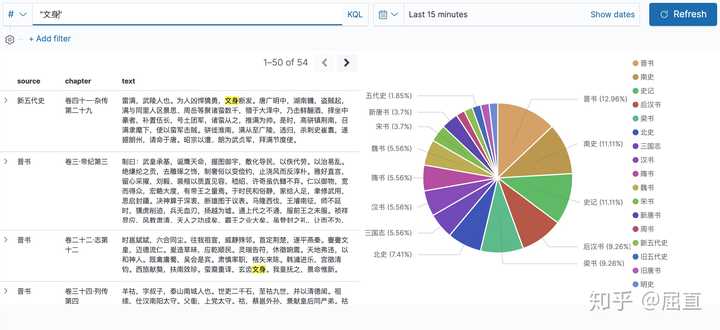
“文身”在史料的搜索结果
《五代史》里面有一个人叫做雷满。雷满是武陵人,剃发纹身,很有黑社会大哥的感觉。雷满这个人在唐朝末期天下大乱的时候,带着一群同乡,搞了一个几千人的创业土匪团队。后来他的团队竟然被唐朝中央政府收编,成了一方节度使。从这个人的身世,能看出唐朝末期已经是盗匪猖獗了。这条史料也说明,纹身这种行为在唐朝就有帮派盗匪的色彩。
《南史》里记载了一个“文身国”。这个国家在日本东北七千多里的地方,老百姓身上有动物纹身。文身国没有城市,上到国王下到平民都住差不多的房子。国王的“宫殿”就是房子外面挖一圈沟,然后沟里灌上水银。这个国家物产丰富,人民欢乐。如果有人犯罪,轻者用鞭子抽,重的扔到给狮子老虎吃。如果狮子老虎看这个人看了一晚上都不吃,那就赦免。吕思勉在《两晋南北朝史》里认为,文身国就是千岛群岛(日本称北方四岛)的得抚岛。
最有意思的是《史记》“鲁周公世家”的记载。吴王夫差有一次攻打齐国,经过了鲁国。夫差顺便跟鲁国打个劫,说要牛、羊、猪各一百头。鲁国无奈,派孔子的徒弟子贡去找夫差和宰相伯嚭,让子贡“以礼诎之”。结果吴王夫差这人混不吝,直接怼回来一句:“我纹身,跟我讲什么礼?” 吴王这个态度跟楚王的“我蛮夷也”有异曲同工之妙。春秋时期吴国是今天的江苏和安徽这一带。这个记载,暗示春秋时代长江下游的人民有纹身的风俗。
网站展示就这么多。想必这三个例子也可以说明这个网站的使用方法了。下面我讲讲为什么要做这么一个搜索工具。
为什么做这个
我以前读历史的时候,往往会在史料查询上浪费很多时间。二十四史很长,一般人也不会在家备上这么大的一堆。维基文库倒是有二十四史的电子版,甚至有搜索功能,但这个功能只能搜索单独史料,而且界面也不是很好用,没有饼状图分布之类的东西。
维基文库的史料搜索
那么有没有专门为历史资料查询设计的搜索系统呢?
我发现社科院有这么一个文章“信息时代的文献阅读和史料检索”,作者是河北师范大学的教授王文涛。
我不是史学专业的学生,所以看这篇论文有些困难,但大概归结了这么几个要点:
“检索式阅读”是一种电子化时代的特有需求。虽然代替不了阅读史料,但可以和阅读史料相辅相成。史料很难标准化。数字都是文字(1234写成一二三四),不好做统计。年份是年号,不能直接搜索公元年。史料比较零散,同一件事会在不同史书和不同章节记载。可以用Word这样的工具检索史料,但是实在不方便。不少大学已经推出了史料查询系统。
我按图索骥地去找了找这些史料查询系统,发现真的不是很好用。有的只支持繁体,有的不公开,有的需要注册登录等待审核,甚至有的网站需要像借书一样“借阅”史料数据库。
或许历史学家们对服务器和数据库技术不太熟悉。正巧,我的日常工作就是服务器和数据库。那么,能不能做一个简单易用的史料查询网站呢?
软件工程和史料分析
如果你问一个软件工程师:“怎样才能实现全文检索呢?” 答案八成是ElasticSearch。ElasticSearch是一个开源项目,虽然一般大家不把它称为一个数据库,但毋庸置疑的是它可以用来很快的存储和检索数据。关于ElasticSearch的更多介绍在此不多说,有兴趣的读者可以去官网直接看说明。
ElasticSearch官方有一个前端界面叫做Kibana,在这个界面上你可以搜索,可以做各种图,甚至还可以做权限管理、机器学习、数据实时分析。Kibana满足了我对历史搜索工具的要求:轻量易用,而且不需要培训,基本上一试就会用了。
Kibana的官方展示
看来搜索系统和界面都搞定了,现在就需要往里面放史料了。
首先是要把数据标准化。这是我设计的一个简单的数据模型:
{
"source": "史记",
"chapter": "陈涉世家",
"text": "陈胜者,阳城人也,字涉。吴广者,阳夏人也,字叔。陈涉少时,尝与人佣耕,辍耕之垄上,怅恨久之,曰“苟富贵,无相忘”庸者笑而应曰“若为庸耕,何富贵也”陈涉太息曰“嗟乎,燕雀安知鸿鹄之志哉”"
}注意每一段话都是这么一个json。史料条目是以段为单位的。
接下来我们的工作就是把史料解析成上面这个格式。这个工作耗费了我大量的时间,因为我早期犯了一些错误。
我一开始的工作方法是:
找到史料的电子版txt写一段程序把它标准化成上面的json格式把json喂到ElasticSearch里面
这个工作方式简直是个灾难。
我先四处寻找史料的电子版。网上的电子版很乱,不同史书格式不统一,编码也不一样,有的不全,有的有错别字,有的甚至还有乱码。
我当时尽量去修改校对,补充完全,统一格式,结果花了几个月的时间,才从《史记》整理到《陈书》。这样太慢了,而且最后史料的质量无法保证。乱码多如牛毛,我的手工修正简直是杯水车薪。
后来我发现了“国学网”,这个网站在“信息时代的文献阅读和史料检索”那篇论文里也有提及,而且作者认为“国学网”的质量不低,可以用来做检索。
我写了一个爬虫脚本,把二十四史给爬了下来,然后整理成json。
接下来该把史料喂到ElasticSearch里了。一条一条喂实在太慢了,所以我用了多线程。但多线程很容易被ElasticSearch限流了,所以需要用一个thread pool。
为了保证没有一段话缺失,我还写了一个integration test。如果本地json文件的段落数和ElasticSearch上搜到的段落数一致,那么史料就被录入完整了。
在我把二十四史尽数注入到ElasticSearch后,该考虑如何Host这个网站了。
我需要一个服务器,最好放在云上。AWS只能免费一年,Google Cloud Platform虽然有个免费版,但内存和存储量实在不够运行ElasticSearch,Heroku的ElasticSearch也不是免费的。国内的阿里云腾讯云没有一个免费。可以说免费的云服务这个问题到今天也没有解决。我暂且只能自己Host。
我自己Host也有问题,就是带宽有限,而且每次搬家这个网站估计都得下线一阵子。最好的办法还是放在云上。如果哪个学校有经费搞云服务的话,我把网站的设置方法都写在GitHub上了,直接一步一步来就行了。
最后就是一个锦上添花的东西了。我发现oss版本的Kibana不支持只读模式,这就意味着任何人都能修改Kibana的页面。这个太危险了。我后来把Kibana升级成了7.4.2,这个版本内置了X-Pack插件,可以进行权限管理。我新建了一个只读权限,如果你用文章开头的那个用户名和密码,就可以进入只读权限了。
另外,7.4.2版本的ElasticSearch和Kibana需要Java的JVM,而且版本不支持7和13。我觉得调环境实在太累了,于是写了个docker-compose文件。如果想用docker安装,直接docker-compose up就行了。



发表评论