前言
SPSS中,探索分析是对变量进行深入和详尽的描述性统计分析,它在一般描述性统计指标的基础上,增加关于数据其他特征的文字与图形描述,分析结果更加细致与全面,有助于对数据做进一步分析。
探索分析,能够生成关于所有个案、或不同分组个案的综合统计量及图形;可以进行数据筛选工作,例如检测异常值、极端值、数据缺口等;还可以进行假设检验。通过探索性分析,能够帮助我们决定选择何种统计方法进行数据建模,判断是否需要把数据转换成正态分布,以及是否需要做非参数统计。
探索分析适用于对数值型的变量(连续型或比率型)进行分析,因素变量应该是取有限个离散值的分类变量(用于对数据进行分组)。
实操
下面我们就来看具体实例。案例:“班级数学语文成绩.sav”,数据反映不同班级的学生性别、数学、语文成绩情况。
Step1:依次单击菜单“分析-描述统计-探索”执行探索性分析的过程,其主设置界面如图1.1。在“因变量列表”中选择数学,在 “因子变量列表”中选择性别,在“标注个案”中选择班级。
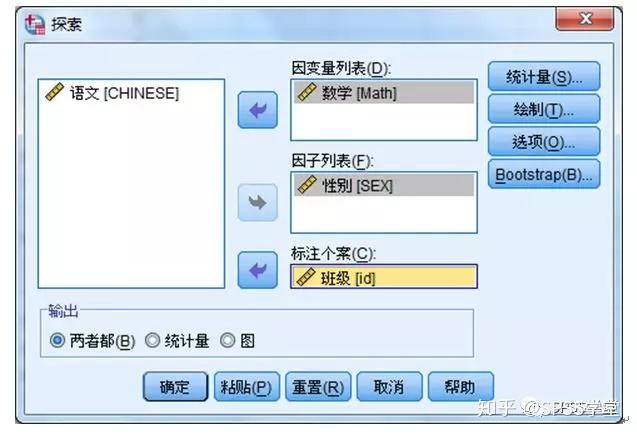
图1.1
因变量列表,用于从变量列表中选入因变量,一般为连续变量。
因子列表,用于从变量列表选入因素变量,一般为分类变量。
如果同时选入了多个因变量和多个因素变量,将对他们之间的两两组合分别进行分析,对于每对因变量和因素变量的搭配,输出结果都是类似的;选入的变量较多时,可能会耗费较长时间并产生很多输出。
标注个案,用于从变量列表选入标签变量,在结果里标识观测量。
Step2:单击“统计量”按钮,弹出统计量设置对话框,根据需要选择统计量,如图1.2。
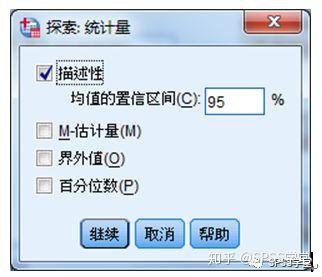
图1.2
描述性复选框,选中此项会输出包含以下内容的表格:均值、中位数、众数、5%修正均数、标准误、方差、标准差、最小值、最大值、全距、峰度系数、峰度系数的标准误、偏度系数、偏度系数的标准误等。
M-估计值复选框,计算并输出比均值和中位数更稳定的数据中心估计值,包括如下四个:“Huber’s”、“Andrews”、“Hampel’s”、“Tukey’s”。M-估计值可以用来判断数据有无明显异常值,如果M-估计值离平均数和中数比较远,那么可能存在异常值。
界外值复选框,输出5个最大值与5个最小值,包括观测量的标签。
百分位数复选框,输出5%、10%、25%、50%、75%、90%、95%的百分位数。
Step3:单击“绘制”按钮,弹出作图设置对话框,根据需要进行作图设置,如图1.3。
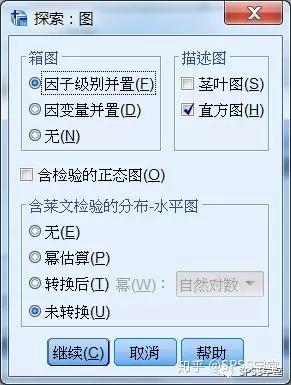
图1.3
箱图,设置关于箱图的参数。
按因子水平分组选项,对每个因素变量,每图只显示一个因变量,该项为默认选项。
不分组选项,对每个因素变量,每图显示所有的因变量。
无选项,不绘制箱图。
描述性,设置关于数据描述性质的图形输出,茎叶图与直方图两个选项,其中茎叶图为默认设置。
带检验的正态图,作正态概率图和去趋势后的正态概率图,并输出检验正态性的Kolmogorov-Smirnov统计量及其Lilliefors置信水平。
伸展及级别Levene检验,设置控制数据转换的散步对水平图。同时显示回归曲线的斜率和方差齐性检验的Levene统计里;如果选择了数据转换,将对转换后的数据进行levene检验。
无选项,不输出散步对水平图。
幂估计选项,产生四分位数的自然对数,对单元格中位数的自然对数的散布图,以及达到方差齐性要求的幂估计;根据此散布对水平图,可以估计将各组方差转换成同方差所需的幂次。
已转换选项,在其后的下拉列表选择具体的变换方法,其中自然对数变换为默认设置。
未转换选项,不做任何数据变换,将输出产生原始的数据散布图,相当于幂次为1的转换。
Step4:单击“选项”按钮,弹出选项设置对话框,根据需要对缺失值的处理方式进行设置,如图1.4。

图1.4
按列表排除个案选项,为默认选项,对每个观测记录,只要分析所用到的变量中有1个含缺失值,就将该观测记录从所有分析中剔除。
按对排除个案选项,只有分析中用到的变量含缺失值时,才将相应的观测记录从当前分析中剔除,此方法可以最大限度地利用原始数据。
报告值选项,将因素变量中含有缺失值的观测作为一个单独的类别进行统计,所有输出结果都将包含这个被标识为缺失的类别。
结果分析
回到主界面,点击确定,就可以得到探索分析的分析结果,如图1.5-1.13。
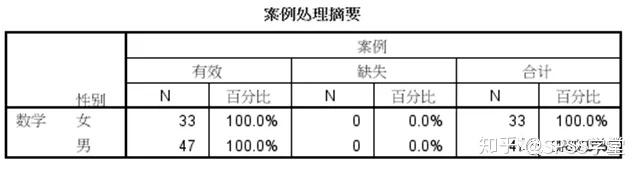
图1.5
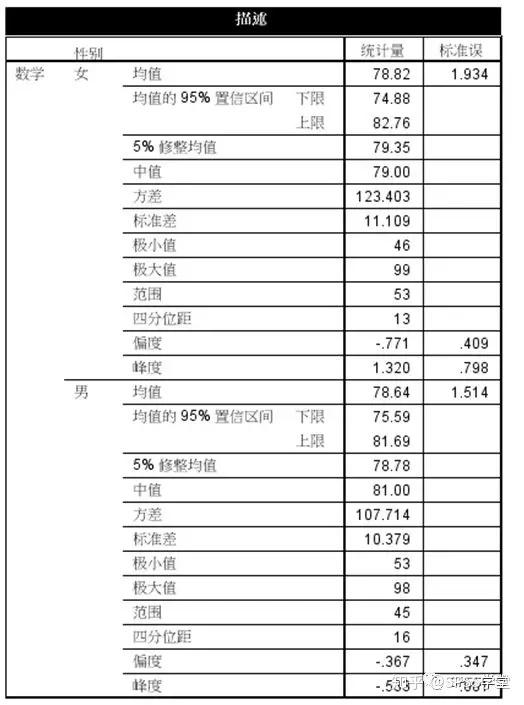
图1.6
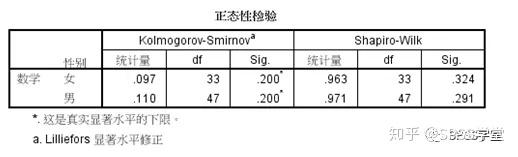
图1.7
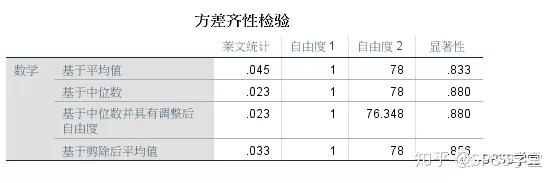
图1.8
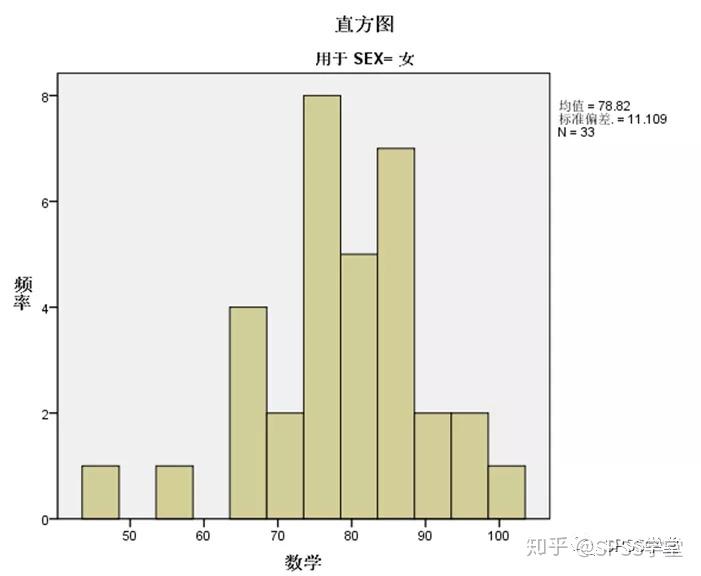
图1.9
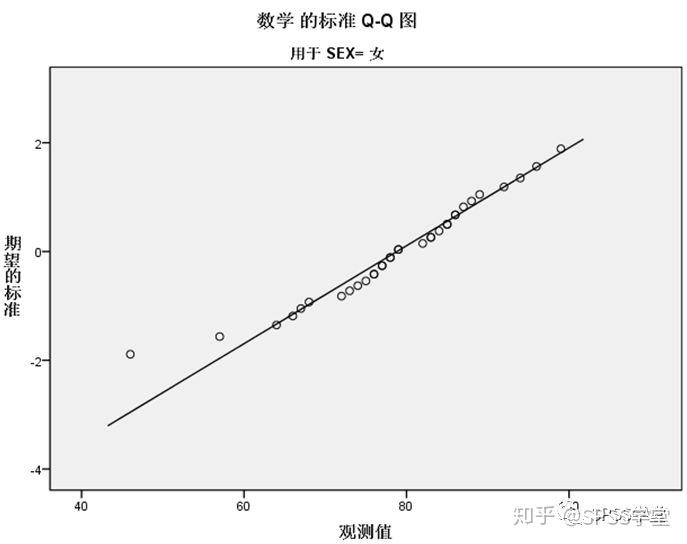
图1.10
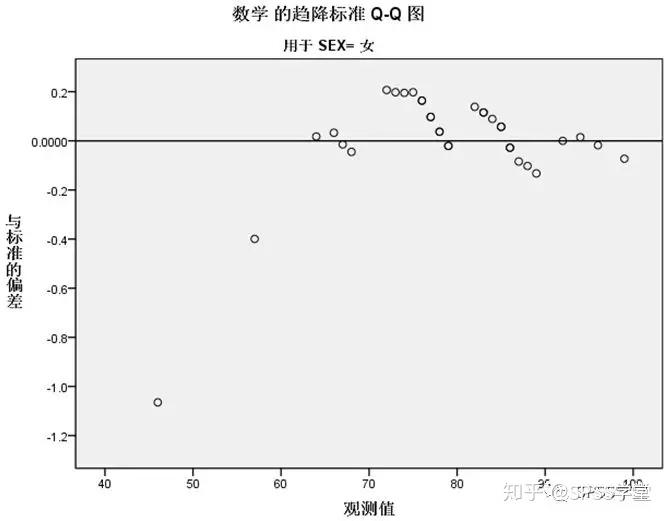
图1.11
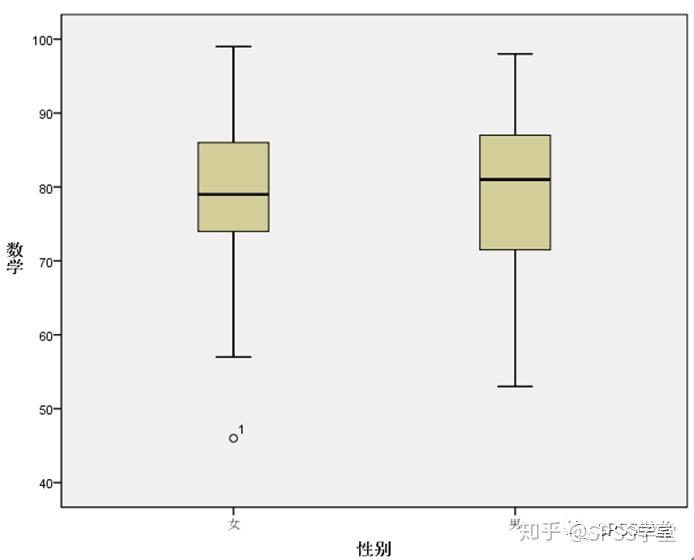
图1.12
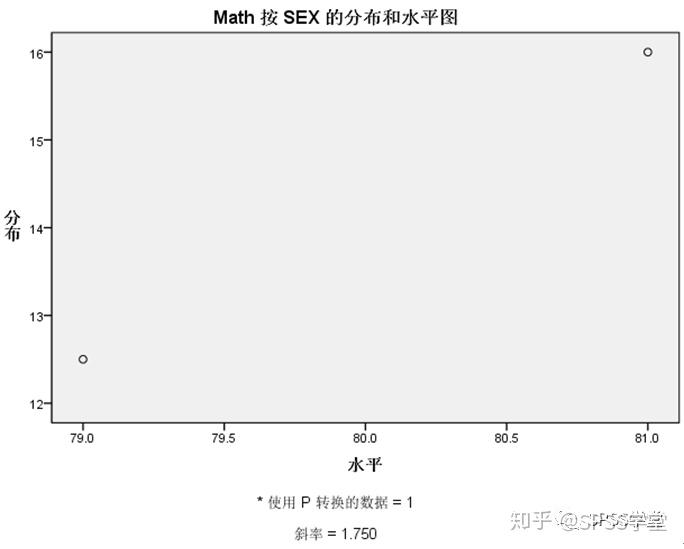
图1.13
1. 案例处理摘要和描述性表格输出,如图1.5-1.6。
摘要表格给出了不同性别的有效个数和缺失个数,本例没有缺失数据;描述表给出了不同性别的描述性统计量输出,包括均值及其95%的置信区间、中位数、方差等,其他年龄的输出与此类似。
2. 正态性检验结果,如图1.7。
正态性检验的显著性水平sig值都大于0.05,所以认为不同性别的数学成绩分布基本都为正态的。
3. 方差齐性检验结果,如图1.8。
4种Levene检验的sig值都大于0.5,故不能否定方差齐性的假设。
4. 直方图和QQ图输出,选取了性别为女的输出图,如图1.9-1.11。
从频率直方图看,女学生的数学成绩在七十多以及八十多居多;从去除趋势的QQ图看,除了有两个不及格的点偏差较大外,其他都分布在横轴附近。
5. 箱图以及分布和水平图,如图1.12-1.13。
在数学成绩对性别的箱图中,女学生的数学成绩,有一个异常数据(偏小)。而在Math按SEX的分布和水平图中,女学生的数学成绩较多地分布在79左右,男学生的数学成绩则较多地分布在81左右。
在 SPSS学堂 中输入“20180207”即可获得操作数据。

发表评论