作者 l 萝卜
正式开始建模与处理数据前,对数据进行探索并有一个初步的认识非常重要,本文将围绕变量探索,展示分类、连续变量,以及两种类型变量结合的探索方法,并展示 Python Pandas数据处理与可视化中的一些快捷常用骚操作~
注:本文数据与源代码可私聊我获取
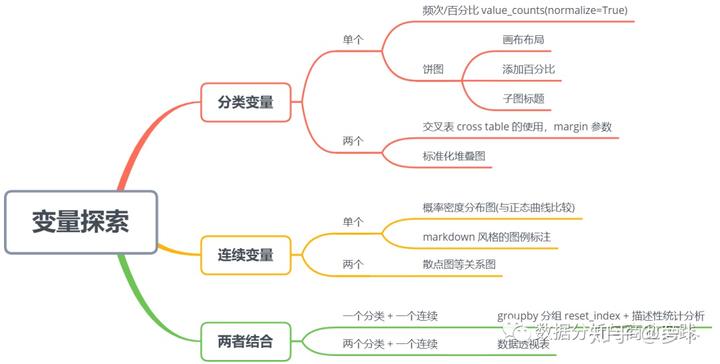
分类变量
01 一个分类变量
一个分类变量的分析方法可考虑频次和百分比,用饼图或者柱状图表示都可以
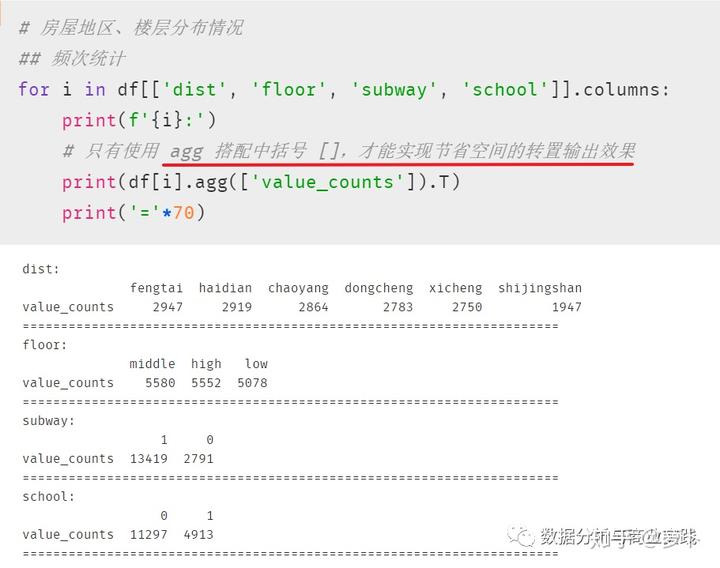
我们也可以通过设置画布布局来同时显示两个连续变量的各自探索情况

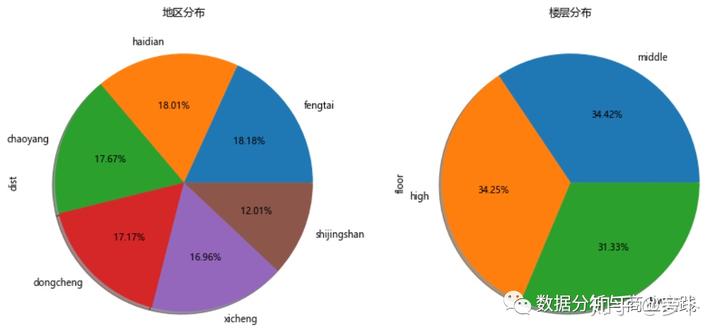
02 两个分类变量
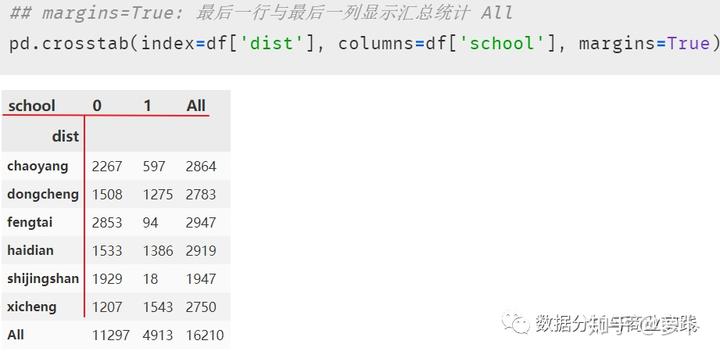
结合两个分类变量考量的分布情况可考虑使用交叉表cross table
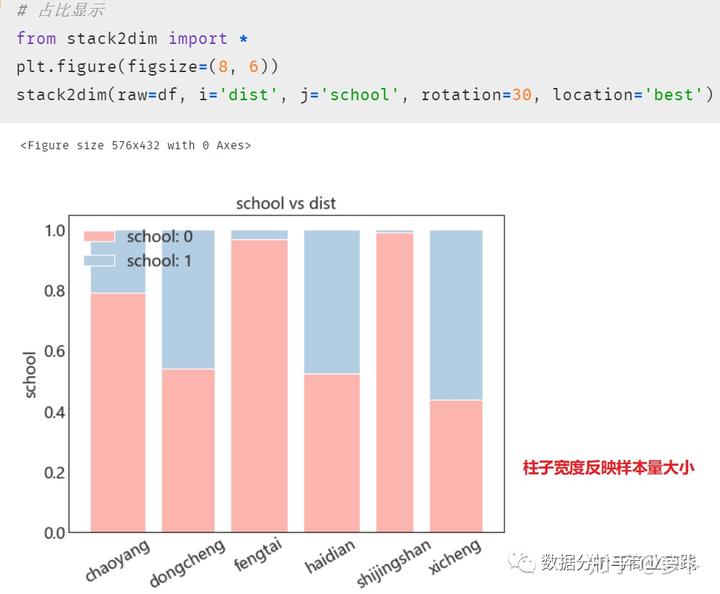
这里我们将探究每个地区的学区房分布情况:参数 margins 设置为 True 表示在最后一行与最后一列显示汇总统计 ALL
如果要将上述交叉表可视化,可考虑使用前人的轮子:一行代码快速绘制标准化的堆叠图,反映占比的同时还能看出每一类的数据量大小
连续变量
01 一个连续变量
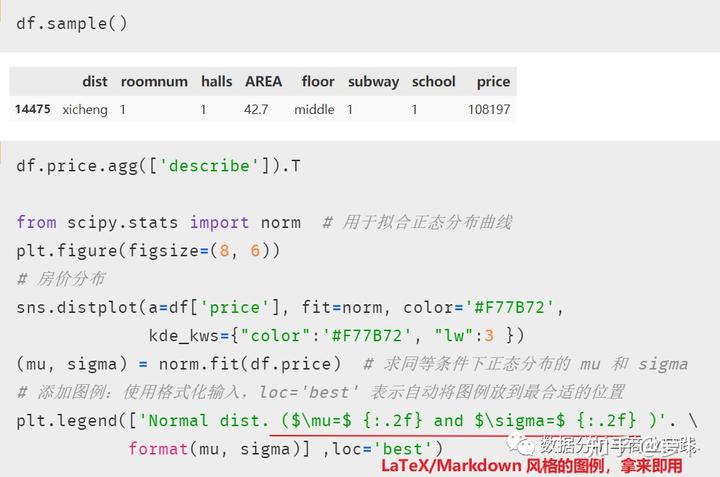
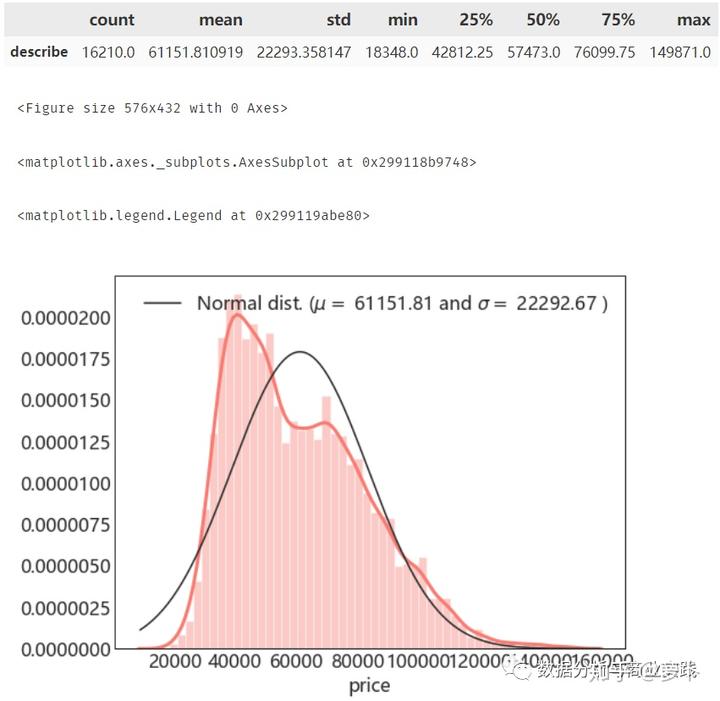
直接进行描述性统计分析,以房价分布为例
02 两个连续变量
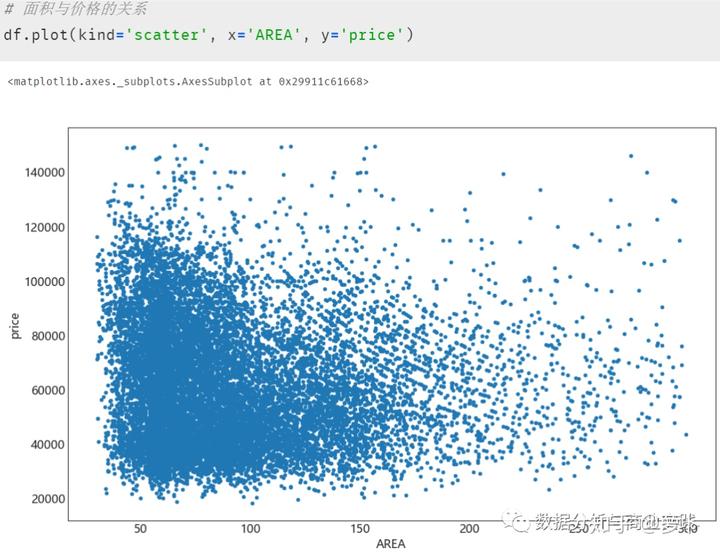
绘制散点图等关系图进行探索,以探寻房屋面积与价格的关系为例
连续变量 + 分类变量
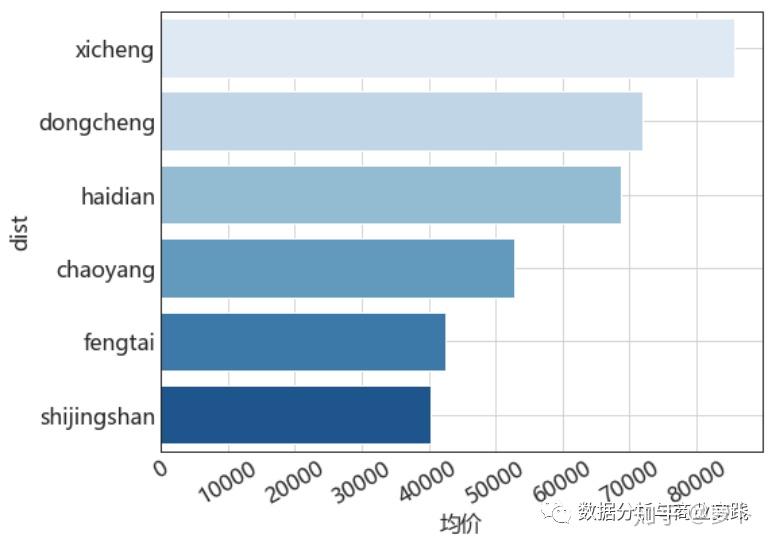
01 一个分类 + 一个连续
统计量是样本的数值概要,用来描述样本;参数则是总体的数值概要
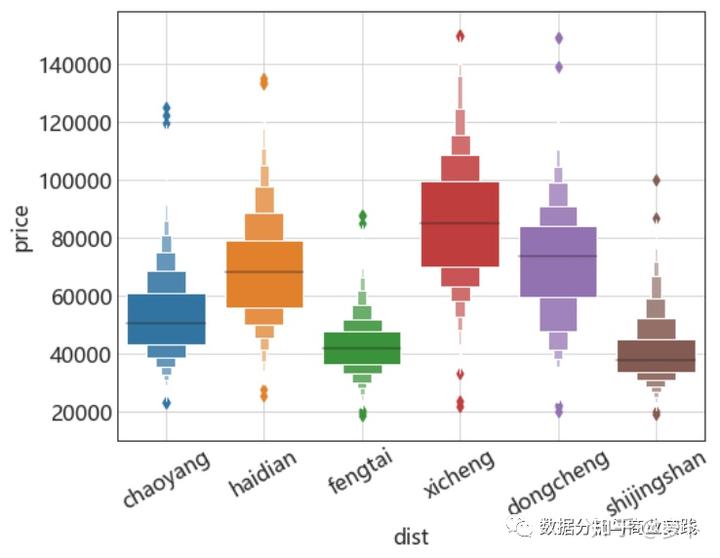
同理,也可绘制箱线图
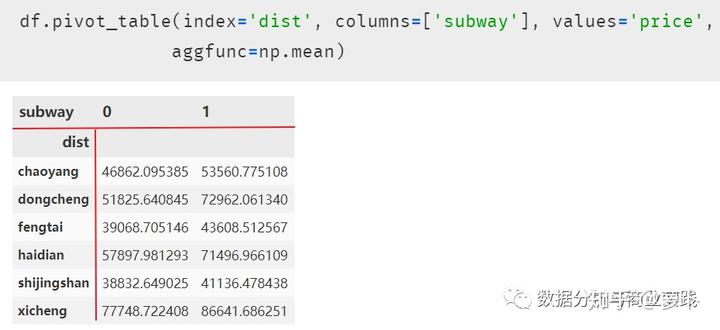
02 两个分类 + 一个连续
使用数据透视表,即在两个分类变量探索时使用的交叉表的升级
先整体确定由两个分类变量构成的行索引 index 与列索引 columns,然后再将连续变量的统计量如 mean,medium 等放入数据框内部。透视表函数中的部分参数与交叉表一样,只是多了处理连续变量的参数。
以求每个区域有无地铁时的房屋均价,发现无论在哪个区,有地铁的房屋价格均高于无地铁的。
当然,我们也可以尝试 “三个分类变量 + 一个连续变量 ”:
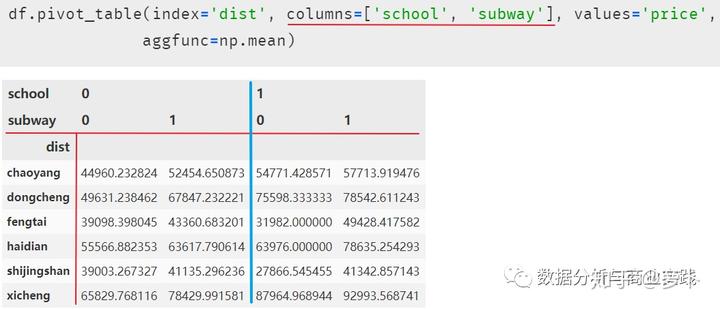
上透视表的理解步骤如下:
参数 index 在 columns 前,表示行索引 index 将会根据地区 dist 来划分。参数 columns 中的列表顺序,school 在 subway 前,表示 index 分完后,列索引先根据学区房的有无来划分,而后再添加有无地铁这个划分标准。
即划分好地区后,求在有无学区房的前提情况下,是否有地铁时的房屋均价。如朝阳区的房子在无学区房的情况下,有地铁和没有地铁时的房屋均价分别是多少。
小结
本文以常见的房价数据集为例,展示了探索分类变量与连续变量的方法,涉及了一些细节数据可视化操作;交叉表,数据透视表,频数统计,分组统计等 Pandas 数据处理操作。这些都是探索数据过程中不可或缺的基础操作,熟练掌握很有必要
注:相关数据源和代码(python,Jupyter Notebook 版本 + 详细注释)已经整理好,可私聊我获取。


来更快更好地理解数据")

:Sweetviz初探")
发表评论