Large Language Models are Edge-Case Generators:Crafting Unusual Programs for Fuzzing Deep Learning Libraries
Yinlin Deng1, Chunqiu Steven Xia1, Chenyuan Yang1, Shizhuo Dylan Zhang1, Shujing Yang1, Lingming Zhang1
1University of Illinois Urbana-Champaign
引用
Yinlin Deng, Chunqiu Steven Xia, Chenyuan Yang, Shizhuo Dylan Zhang, Shujing Yang, and Lingming Zhang. 2024. Large Language Models are EdgeCase Generators: Crafting Unusual Programs for Fuzzing Deep Learning Libraries. In 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE ’24)
论文:
摘要
深度学习库中存在的缺陷可能会波及到使用这些库的下游应用,因此确保这些库的质量至关重要。然而,为深度学习库生成有效的模糊测试输入程序具有挑战性,因为这些输入程序必须符合语法和语义要求,同时还要遵守张量与运算符的约束。近期研究显示,大语言模型能够直接被用来隐式学习这些要求和约束,从而为模糊测试生成有效的程序。但是,大语言模型倾向于生成常规程序,而在模糊测试中,我们更倾向于使用非寻常的输入,希望这些输入能够覆盖极端用例。
为了填补这一空白,本文提出了FuzzGPT,一种引导大模型生成非常规程序以进行模糊测试的方法。通过对两个主流深度学习库(PyTorch和TensorFlow)的实验研究,作者发现FuzzGPT的性能显著优于TitanFuzz(另一个利用大模型进行深度学习库模糊测试的工具),共检测到76个错误,其中49个已被确认为新的未知错误,包括11个高优先级错误或安全漏洞。
1 引言
深度学习(Deep Learning, DL)技术如今被广泛应用于众多领域,如科学研究、医疗保健、金融和交通运输。这些下游深度学习应用通常基于深度学习库(例如PyTorch和TensorFlow)构建,开发者通过调用库提供的API来创建、训练和部署深度学习模型。与其他复杂的软件系统一样,深度学习库也可能存在缺陷。更重要的是,深度学习库中的缺陷会对下游应用产生影响。因此,确保深度学习库的质量和可靠性是至关重要的。
模糊测试(Fuzzing)是一种通过生成随机输入来查找软件缺陷的测试方法,近年来在深度学习库的测试领域得到了广泛的应用。然而,生成适用于深度学习库的输入程序极具挑战,因为这些程序不仅要符合语言(如动态类型的Python)的语法和语义,还需满足张量和运算符的约束。为了简化这一问题,早期的深度学习库模糊测试技术主要集中在对模型层面或API层面的测试。模型层面的模糊测试通常会重用或变异现有的种子模型,或者从头开始生成新的深度学习模型。另一方面,API层面的模糊测试则专注于通过有效的输入生成或基于预言的推断来单独测试每个API。尽管API层面的模糊测试可以广泛覆盖多个API,但它无法发现不同API混合使用时产生的错误。
随着大语言模型(Large Language Models, LLMs)的飞速发展,TitanFuzz被提出作为一种直接利用大语言模型对深度学习库进行模糊测试的方法。大语言模型在开源代码库中数以亿计的代码片段上进行预训练,这些代码片段中可能包含了大量有效的深度学习程序;因此,大语言模型能够隐含地学习到语言的语法/语义以及有效计算所需的张量/运算符约束。然而,大语言模型倾向于生成常规程序,这些程序仅能涵盖有限的常见行为。相反,不寻常的程序往往表现出的是不常见的行为,更有可能覆盖那些没有充分测试的代码路径,从而更有可能发现深度学习库中潜在的缺陷。
本文提出了一种新方法----FuzzGPT,首次尝试引导大语言模型生成不寻常的输入程序,从而进行有效的模糊测试。FuzzGPT的核心在于利用历史缺陷触发程序中的关键代码。FuzzGPT利用大语言模型提供一个自然而通用的全自动化解决方案,这些大语言模型通过被提示或微调,能够理解这些历史程序,并生成更不寻常的程序。与利用历史信息的传统技术相比,FuzzGPT可以隐式学习生成约束,包括语言语法/语义、深度学习计算约束以及新的不寻常约束,而且是全自动化的。此外,尽管本文聚焦于深度学习库模糊测试这一具有挑战性的问题,但FuzzGPT的思想可以推广到其他应用领域或编程语言。
为了实现FuzzGPT,作者首先从目标深度学习库的开源仓库中挖掘缺陷报告,利用这些报告来构建一个缺陷触发代码片段的数据集。基于这个数据集,FuzzGPT使用了以下策略:1) 上下文学习:作者给大语言模型提供了一些历史缺陷触发程序的示例或部分缺陷触发程序,从而使大模型能够生成新的代码片段或自动完成部分代码。(2)微调:作者通过在提取的历史缺陷触发程序上训练来修改模型权重,从而获得专门生成类似缺陷触发代码片段的微调大语言模型。
本文的主要贡献可以总结如下:
2 本文方法
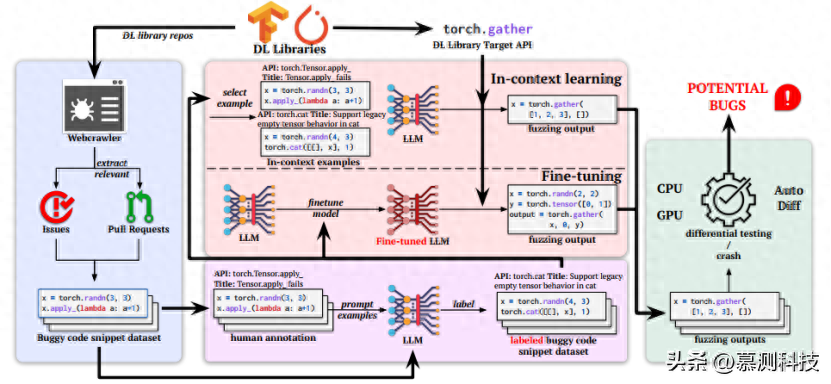
图1:FuzzGPT的总体框架
FuzzGPT的核心思想是利用大语言模型从历史报告的缺陷中学习,生成类似的缺陷触发代码片段,从而发现新的缺陷。以往的工作在生成类似的缺陷触发代码片段时需要大量的人力投入,并且难以推广到具有挑战性的深度学习库模糊测试领域。然而,最近在大语言模型领域的进展提供了一个自然而通用的全自动化解决方案——现代大语言模型可以轻松地被提示或微调,以理解消化这些历史程序,并通过有效地利用它们的代码来生成类似历史程序的新程序。
图1展示了FuzzGPT的总体框架。FuzzGPT首先系统地从目标深度学习库的存储库中挖掘缺陷报告,以收集历史缺陷触发代码片段。由于FuzzGPT旨在针对特定的深度学习库API,每个缺陷触发代码片段都需要相应的缺陷API标签。然而,大多数缺陷报告并未明确指出具体的缺陷API。为了解决这一问题,FuzzGPT采用了一种自我训练的方法,即通过使用大语言模型提示少量手动标记的示例,自动生成缺陷API标签。接下来,使用这些提取出的缺陷触发代码片段和缺陷API标签,FuzzGPT可以启动模糊测试过程,以生成边缘情况代码片段。在本研究中,作者探讨了两种学习方法:1) 上下文学习(In-Context Learning):直接提示预训练的大语言模型,使用缺陷触发代码和缺陷API示例(少量示例),或者一个部分/完整的缺陷触发代码(零样本)让模型为特定API生成/编辑程序;2) 微调(Finetuning):使用提取的数据集,作者微调大语言模型,从缺陷触发代码示例和模式中学习,以生成新的缺陷触发代码片段。最后,生成的程序配备上对应的测试预言(例如,CPU/GPU或者自动的差分测试预言)一起执行,从而检测缺陷。
尽管FuzzGPT适用于任何生成式的大语言模型,但在本论文中,作者专注于两种特定的大语言模型:Codex和 CodeGen。Codex是一种先进的生成式模型,它在开源代码仓库上进行了微调,这些开源代码仓库初始化自GPT-3模型权重。与Codex不同,CodeGen是一个开源的生成式模型,但是它的模型权重和训练数据并未公开。另外,作者在本论文中的研究针对的是Python中暴露的深度学习库API。在FuzzGPT中,作者直接使用Codex和CodeGen模型——较大的Codex模型使作者能够展示在使用大语言模型时模糊测试的全部潜力,而CodeGen模型可用于评估扩展效果并测试微调策略。
2.1 数据集构建
为了从历史缺陷中学习,FuzzGPT需要一个包含缺陷触发代码片段及其对应出现错误的深度学习库API的数据集。
从GitHub中挖掘历史缺陷。首先,作者实现了一个爬虫,用于收集目标库的GitHub问题追踪系统中所有的问题(Issues)和拉取请求(PRs)。然后,作者专注于从两个来源识别缺陷触发代码片段:1)与已接受或待处理的PR相关的问题。在这些错误报告中,作者搜索用于重现错误的代码片段,并将它们连接在一起;2)在提交消息中包含代码块的拉取请求。作者进一步考虑这些请求是因为它们可能修复了没有公开在问题页面中的缺陷。对于每个提取的问题或拉取请求,作者提取其标题,并将其包含在示例学习和微调的提示中。挖掘到缺陷触发代码片段之后,作者接下来将进行自动标注。
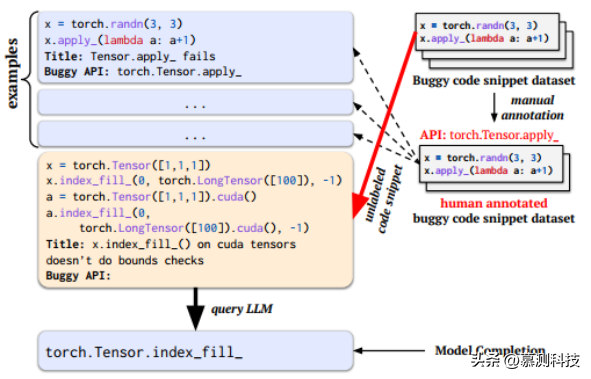
图2:标注缺陷API的提示
自动标注缺陷API。作者的数据集中的每个代码片段通常涉及多个深度学习API。因此,不可能直接从中提取到存在缺陷的API。为了给每个缺陷触发代码标注对应的存在缺陷的API,作者提出了一种自我训练的方法,即将几个示例提示(如图2所示)输入大语言模型,并让模型的完成缺陷API的标识。作者首先为几个随机选择的缺陷触发代码片段提供手动标注的缺陷API名称。这些手动标注的实例作为实例成为输入的一部分。在图2中,示例由选择的缺陷触发代码片段、相应的问题/拉取请求的提取标题以及手动标注的缺陷API名称三部分组成。然后,作者将这些示例与目标缺陷触发代码片段结合,创建一个提示,并查询大语言模型以获取给定代码片段的预测缺陷API名称。这种方法类似于自我训练,即首先在少量标记数据集上训练一个分类器,然后用它来标注大量未标记数据。在本论文中,作者直接利用大语言模型的能力通过少量示例的学习,为大量提取的缺陷触发代码片段提供标注。
2.2 上下文学习和微调
利用提取到的带有标注的缺陷代码片段数据集,FuzzGPT开始学习生成边缘情况的代码。目前基于大语言模型的学习方法可以分为两种主要方法:上下文学习和微调。上下文学习直接使用预训练的大语言模型而不调整任何模型参数。此种方法的输入提示将首先给出指令和相关示例,这些指令和示例展示了任务,然后再提供当前的输入。上下文学习允许大语言模型通过学习输入上下文来预热其输出,不仅可以学习到所需的输出格式,还能学习到相关的任务领域。微调则通过将模型在特定数据集上训练来修改模型的参数,从而创建一个解决特定任务的专门模型。在FuzzGPT中,作者设计了三种不同的学习策略:少量样本学习(few-shot learning)、零样本学习(zero-shot learning)和微调。图3详细说明了这三种策略。

图3:微调、少量样本学习和零样本学习
少量样本学习。作者通过在目标查询前添加标注的缺陷触发代码片段示例来实现基于少量样本的学习。图3 - 1展示了少量样本学习的提示词构造方法。提示中的示例包括API名称、缺陷描述以及最终的缺陷触发代码片段。这些示例的作用有两方面:首先,它们旨在引导大模型生成所需的输出格式;其次,它们使模型能够通过观察历史缺陷触发代码片段,学习生成类似的边缘情况代码片段,而无需修改模型参数。在少量样本学习中,每个提示包含k个示例(即为K-Shot)和实际的查询(目标API和缺陷描述头)。然后,大语言模型可以根据提示生成新的预测。
零样本学习。本文作者在FuzzGPT实现了基于零样本学习的两种变体:1)零样本补全(Zero-Shot Completion)。在此变体中,输入内容仅包含一个不完整的代码片段。这个不完整的代码片段是根据历史导致缺陷的代码片段数据集生成的,作者随机去掉了一部分后缀代码。图3 - 2展示了零样本补全输入的生成方式。作者首先添加一个自然语言注释揭示{target_api}中的一个bug。接着,作者随机从数据集中选取一个代码片段示例。随后,作者随机去掉所选取bug触发代码片段的后缀部分,仅保留前缀行作为大语言模型的输入。2)零样本编辑(Zero-Shot Editing)。在此变体中,输入是从历史触发缺陷的数据集中的完整代码片段创建来的。图3 - 2展示了零样本编辑的一个示例。首先,作者使用自然语言注释向大语言模型表明想要进行编辑。与零样本补全类似,作者随机选择一个缺陷触发代码并将其附加到输入的末尾。与零样本补全不同的是,在零样本补全中模型会自动补全代码片段的末尾,而编辑的目的是允许大语言模型重用历史触发缺陷代码片段的所有部分以产生新的模糊测试输出。
微调。除了利用上下文学习(少量样本和零样本)从历史缺陷中进行学习外,微调还通过将大模型在历史缺陷代码片段数据集上训练直接调整模型参数。图3 - 3展示了微调的过程以及对微调后模型的输入。每个训练样本的格式与少量样本示例相同,包括API名称、缺陷描述和缺陷触发代码片段三部分。作者从原始预训练过的大语言模型开始,通过再次在新的数据集上训练使模型能够自回归地预测每个训练样本,进而通过梯度下降法更新模型的权重。对于每个深度学习库,作者根据从该库收集的缺陷触发代码片段对模型进行单独微调。通过在这些历史缺陷触发代码片段上进行微调,大语言模型能够学习到目标库的不同缺陷触发模式或要素。微调模型的输入采用了与少量样本方法相同的模式,即基于特定目标API构建提示。
2.3 测试预言
利用生成的输出,作者采用通用的和深度学习特有的检验方法来测试深度学习库:
崩溃检测。作者通过执行模糊测试输出的程序并监控运行过程,在模糊测试过程中发生的意外崩溃可以用来识别缺陷,这些崩溃可能包括程序终止、段错误或者内部断言失败。这些崩溃所揭示的错误可能引发安全漏洞。
CPU/GPU检验方法。作者通过比较两个执行平台(CPU和GPU)的输出值之间的不一致性来检测计算错误。作者借鉴先前的研究使用显著性容忍阈值进行比较从而可以适应特定库API在不同执行平台上的非确定性。
自动差分(Automatic Differentiation,AD)检测方法。作者进一步在深度学习库的关键AD模块中检测梯度计算错误,这些模块对于深度学习模型的训练效率至关重要。作者采用先前研究提出的AD检验方法,对比反向AD(深度学习库中最常用的模式)、正向AD以及数值差分(Numerical Differentiation,ND)所计算的梯度。
3 实验评估
3.1 实验设置
研究问题。在本文中,作者研究以下研究问题:
RQ1:FuzzGPT使用不同的学习策略的效果对比如何?
RQ2:FuzzGPT对比现有的模糊测试工具表现如何?
RQ3:FuzzGPT中的关键组件对效果的影响如何?
目标深度学习库。作者将PyTorch(版本1.12)和TensorFlow(版本2.10)作为目标深度学习库,因为它们是两个最受欢迎的深度学习库,并且在之前的深度学习库测试工作中得到了广泛的研究。
基线。在本研究中,作者将FuzzGPT与目前最先进的深度学习库模糊测试工具进行了对比,包括API级别的FreeFuzz,DeepREL,∇Fuzz以及模型级别的Muffin,同时也包括了最新的TitanFuzz。作者在每个工具的默认配置下进行了测试,覆盖了两个库,但由于Muffin不支持PyTorch,因此只在TensorFlow上进行了测试。
模糊预算。默认设置下,作者为每个目标API生成了100个程序。在少量样本方法中,针对每个目标API,作者独立构建了10个提示,每个提示随机选取了6个样本,然后每个提示都被送入大语言模型中以生成10个样本。在零样本方法中,作者从数据集中随机选择了10个不同的示例,并使用部分/完整代码构建了10个提示以进行补全或编辑。在微调方法中,作者使用了固定的任务描述,并查询模型10次生成一个目标API的100个程序。
环境。作者使用了一个具有256GB RAM的64核工作站,运行Ubuntu 20.04.5 LTS系统,并配备了4个NVIDIA RTX A6000 GPU。
生成过程。所有的大语言模型进行生成时,作者的默认设置是采用top-p采样,参数设置为p = 0.95,temperature = 0.8,max_token=256。
3.2 度量指标
检测到的错误数量。遵循先前关于模糊测试深度学习库的研究,作者报告了检测到的错误数量。
独特的崩溃。除了统计所有错误之外,作者还统计了独特崩溃的数量,并且将其作为衡量模糊测试有效性的另一个指标。在以往的文献中,独特崩溃被广泛用于评估模糊技术的效果。在此研究中,作者对独特崩溃的定义更为严格:首先,作者对每个崩溃的根本原因进行了手动分析。如果不同的程序由于相同的原因崩溃,作者将它们视为一次独特的崩溃。其次,本研究中报告的所有独特崩溃都已被开发人员确认为独特且真实的崩溃错误。
覆盖的API数量。遵循先前的工作,作者报告了覆盖的API数量,作为深度学习库测试充分性的另一个重要指标,因为深度学习库通常包含成千上万的API。
生成的唯一有效程序数量。生成的程序被认为是有效的,如果该程序在没有异常的情况下成功执行,并且至少调用了一次目标API。作者移除了已经生成的代码片段,只考虑唯一的程序。
RQ1 不同学习策略的对比
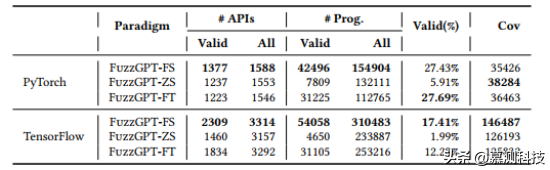
表1:学习策略对比
作者首先对三种FuzzGPT变体(少量样本、零样本、微调)进行了性能比较,以了解它们的表现。表1总结了实验结果。其中#APIs、#Prog.和Cov列分别表示API数量、独特程序数量和覆盖的代码行数。具体来说,Valid表示仅考虑没有运行时错误的独特程序,All表示所有生成的独特程序都被纳入考虑。此外,Valid(%)计算了有效程序在所有生成的独特程序中的比例。我们可以观察到,FuzzGPT-FS在PyTorch和TensorFlow上都有最高的API覆盖率和独特的(有效的)程序数量。这可能是因为它为大语言模型(即Codex)提供了丰富的上下文,使得大语言模型能够学习和组合多种bug模式。
FuzzGPT-ZS的有效率与其他变体相比要低得多。原因在于它需要完成现有的部分程序。这种方法与其它变体相比,搜索空间更受限制,任务更具挑战性,因为新生成的代码需要与现有代码兼容。同时,FuzzGPT-ZS可能会触发现有部分程序中的API与新生成的API之间更有趣的交互。此外,从bug历史中复用的部分代码也非常有价值,可能已经覆盖了一些我们感兴趣的程序路径/行为。因此,FuzzGPT-ZS在PyTorch上的覆盖率甚至达到了最高。FuzzGPT-ZS在TensorFlow上的表现相对较差,可能是因为用于TensorFlow的可重用片段(只有633个,几乎无法覆盖所有3316个TensorFlow API)较少。
FuzzGPT-FT在两个库上都达到了相当不错的代码覆盖率,并且在PyTorch上具有最高的有效率。这表明微调可以是一个非常有效的模糊测试特定库的方法,因为微调的模型通过更新模型参数学习了所有收集到的bug模式,并且在生成时可以“选择”或“混合”学习到的bug成分来针对特定的API。相反,少量样本方法消耗了有限的上下文示例,而零样本方法在每个推理步骤中仅依赖于一个部分示例。然而,微调需要收集一个(高质量的)微调数据集,并为每个不同的任务训练一个不同的LLM(这在计算资源和存储方面可能是昂贵的)。
RQ2 与现有模糊测试工具对比
作者比较了FuzzGPT-FS/-ZS/-FT与最先进的模糊器TitanFuzz及其他近期推出的深度学习库模糊测试工具。所有技术均在默认配置下应用。
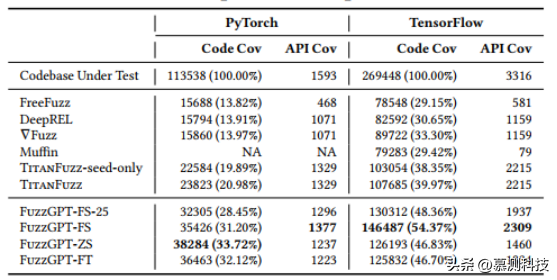
表2:与现有模糊测试工具对比
API和代码覆盖率。如表2所示,FuzzGPT的三个变体在代码覆盖率方面明显优于所有现有模糊测试工具,包括最先进的TitanFuzz。具体来说,表现最佳的变体FuzzGPT-FS/FuzzGPT-ZS在TensorFlow/PyTorch上实现了54.37%/33.72%的行覆盖率,比TitanFuzz提高了36.03%/60.70%。作者还观察到一个有趣的现象:尽管FuzzGPT与TitanFuzz在API覆盖率上相似,但其代码覆盖率却更高。这表明FuzzGPT能够覆盖深度学习库中更多有趣的行为/路径。FuzzGPT和TitanFuzz都依赖于大语言模型来完全自动生成(或变异)程序,并且在API覆盖率方面明显优于先前的技术(FreeFuzz,DeepREL,∇Fuzz,Muffin),这展示了大语言模型在模糊测试方面的优越性。
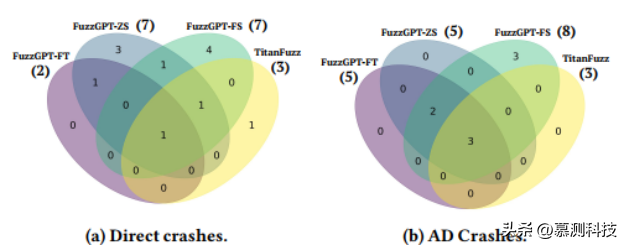
图4:独特缺陷的韦恩图
崩溃检测。作者对比了FuzzGPT和TitanFuzz在PyTorch示例库上的缺陷发现能力,并以独特崩溃的数量作为评价标准。不一致错误在本次比较中未被纳入,这是因为崩溃检测更为直观且能作为错误发现能力的近似衡量。作者按照默认设置运行了这两个工具,并通过直接执行程序来检测崩溃。此外,作者还使用AD或acles执行所有程序,以检测更多潜在的崩溃。图4展示了FuzzGPT-FS/-ZS/-FT和TitanFuzz的Venn图比较,括号中的数字代表每种技术检测到的总崩溃数量。作者发现三种技术在总崩溃数量上均优于TitanFuzz的基线。通过将FS/ZS/FT三种技术结合使用,FuzzGPT总共检测到19个独特的崩溃,其中14个是TitanFuzz无法检测到的,而TitanFuzz仅检测到1个独特的崩溃。
RQ3 消融实验
作者首先评估了随着模型大小增加的FuzzGPT-FS的性能。图5a显示了当增加模型大小时,5次运行的代码覆盖率和生成的有效程序数量(用线条表示平均值)。我们可以看到,更大的模型能够生成更多的语法和语义上正确的程序。另外,随着模型参数的增加,覆盖率明显提高。
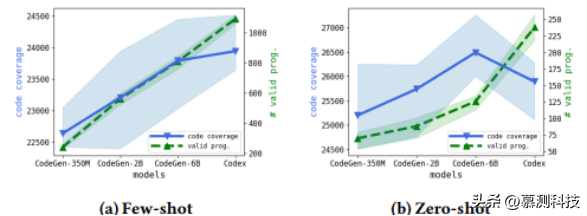
图5:模型大小比较
作者还检查了少量样本模板中的缺陷描述的有效性。如表3所示,包括错误描述的提示显著提高了代码覆盖率,表明向大语言模型提供一些上下文信息是有益的。表3还显示,在每个示例中包含自然语言描述能够促使模型生成更多的独特API,这意味着模型能够生成更多样化的自然语言描述,这影响了后来的代码生成。较低的有效率可能是因为生成的程序更有可能覆盖一些边缘情况并触发运行时异常。
表3:思维链提示
转述:杨鼎



发表评论