
通过实例探索数据。
导言
每个数据科学家必须掌握的最重要的技能之一是正确地探索数据的能力。彻底的探索性数据分析(EDA)对于确保收集到的数据和执行的分析的完整性至关重要。本教程中使用的示例是对SAT和ACT历史数据的探索性分析,以比较SAT和ACT考试在不同国家的参与情况和表现。到本教程结束时,我们将获得数据驱动的洞察力,了解美国标准化测试的潜在问题。本教程的重点是演示探索性数据分析过程,并为希望使用数据的Python程序员提供一个示例。为了进行这一分析,我在一本木星笔记本中检查和操作了现有的CSV数据文件,其中包含了2017年和2018年SAT和ACT的数据。通过构造良好的可视化和描述性统计来探索数据是一种很好的方法,可以熟悉您正在使用的数据,并根据您的观察结果制定假设。
关注,转发,私信小编“01”获取Python学习资料+数据分析学习资料!

探索性数据分析(EDA)目标
1)快速描述数据集;行/列数、缺少的数据、数据类型、预览。
2)清除损坏的数据;处理丢失的数据、无效的数据类型、不正确的值。
3)可视化数据分布;条形图、直方图、方格图。
4)计算和可视化变量间的关联(关系);热图。
数据驱动方法的好处
标准化测试程序多年来一直是一个有争议的话题,这已经不是什么秘密了。通过自己的初步研究,我很快发现了SAT和ACT考试中的一些明显问题。例如,有些州只要求SAT考试,只要求ACT考试,这两种考试都是标准考试,或者要求每个学生参加他们自己选择的一次标准化考试。每个州设定的标准化测试期望之间的这种差异应该被认为是州间考试记录偏差的一个重要来源,例如参与率和平均性能。研究可能很重要,但采取数据驱动的方法来支持基于定性研究的索赔(假设)是至关重要的。采用数据驱动的方法可以验证先前提出的主张/假设,以及在对数据进行彻底检查和操作的基础上发展新的洞察力。
开始
请随意下载我的代码和/或数据,以便在本教程中下载到我的GitHub:https:/github.com/cbratkovics/sat_act_Analysis
使用Python探索数据的第一步是确保导入适当的库。
对于这个介绍,我们需要的库是NumPy、Pandas、Matplotlib和Seborn。导入库时,可以为其分配别名,以减少使用每个库属性所需的键入量。下面的代码显示了必要的导入语句:
使用Pandas库,可以将数据文件加载到容器对象(称为数据帧)中。顾名思义,这种类型的容器是一个框架,它使用Pandas方法pd.read_csv()保存读取的数据,该方法特定于CSV文件。将每个CSV文件转换为PADAS数据帧对象如下所示:
对数据的探索&对损坏数据的清理
在执行探索性分析时,了解您正在使用的数据是非常重要的。幸运的是,数据框架对象有许多有用的属性,这使得这很容易。在多个数据集之间比较数据时的一个标准做法是使用该属性检查每个数据帧中的行和列数,.形状,就像这样:
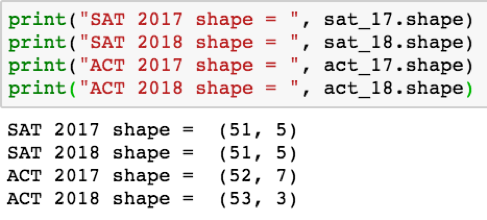
注意,左边是行数,右边是列数;(行,列)。
我们在数据方面的第一个问题是,2017年ACT和2018年ACT数据帧之间的维度不一致。让我们更好地使用.头()方法,该方法显示Pandas数据框架对象中每列的前五行(前五个索引值)。我将以2018年ACT为例:

在预览了其他数据帧的前五行之后,我们可以推断,Sates如何被输入到数据集中可能存在问题。由于有51个美国,2017年ACT和2018年ACT‘State’栏中很可能有不正确和/或重复的值。然而,在处理数据时,我们无法确定这种推断。我们需要检查有关的数据,以确定确切的问题。首先,让我们使用.value_count()方法检查2018年ACT数据中“State”列的值,该方法按降序显示数据帧中每个特定值的出现次数:

注意,2018年ACT数据中的值“缅因州”被表示了两次。下一步是确定这些值是重复的还是数据输入错误。我们将使用一种称为掩蔽的技术来实现这一点,该技术允许我们检查符合指定标准的数据帧中的行。例如,让我们使用掩蔽来查看2018年ACT数据中“State”值为“Maine”的所有行:
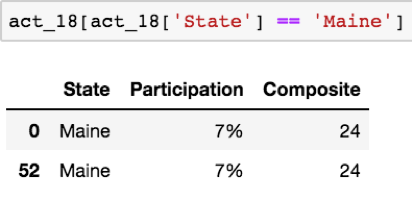
现在,已损坏的值已确认为重复项。因此,我们可以使用.Drop()方法,并使用.Reset_index()方法,解决以下问题:

注意:act_18索引[52]指定要删除的索引,inplace=True保存对原始数据帧对象的更改,而不将其重新分配到原始数据框架对象(Act_18)。
既然我们已经解决了ACT数据帧之间不一致的行数问题,那么SAT和ACT数据帧之间仍然存在不一致行的问题(ACT为52行,SAT为51行)。为了比较状态间的SAT和ACT数据,我们需要确保每个状态在每个数据帧中的表示是相等的。这是您获得创造性的机会,并想出一种方法来检索数据帧之间的“State”列值,比较这些值,并显示结果。我的解决方案如下所示:

功能,比较值(),从两个不同的数据框架中获取一个列,临时存储这些值,并显示仅出现在其中一个数据集中的任何值。让我们看看在比较2017年和2018年SAT/ACT“State”列值时,它是如何工作的:

好的!现在我们知道,需要删除两个ACT数据帧中“State”列中的“National”值。这可以使用我们用来定位和删除ACT 2018数据帧中重复的“缅因”值的代码来实现:

然而,关于“华盛顿特区”这个值,还有另一个错误。以及2018年SAT和ACT 2018年数据中的“哥伦比亚特区”。我们需要确定一个一致的值来代表华盛顿特区/哥伦比亚特区的四个数据框架。您所做的选择在这两个选项之间并没有什么关系,但是选择在数据帧中存在最高的名称是很好的做法。由于SAT 2017和ACT 2017“State”数据之间唯一的区别是“国家”值,所以我们可以假设“华盛顿特区”。在这两个数据帧中,“哥伦比亚特区”在“州立”栏中是一致的。让我们使用掩蔽技术来检查“华盛顿特区”中的哪个值。“哥伦比亚特区”列在2017年“州”栏目中:

现在我们有足够的证据来取代“华盛顿特区”在2018年ACT数据框架中使用“哥伦比亚特区”的值。使用Pandas数据帧.替换()方法,我们可以这样做。然后,我们可以使用Compare_VALUES函数确认我们的更改是成功的:

成功!现在,每个数据帧中的状态之间的值是一致的。现在,我们可以解决ACT数据集之间列数不一致的问题。让我们使用.栏属性:

请注意,添加“\n”表达式会在print()的输出显示后打印新行。
由于这一分析的目的是比较SAT和ACT数据,我们越能表示每个数据集的值,我们的分析就越有帮助。因此,我将在每个数据帧中保留的唯一列是“State”、“参与度”、“Total”(仅SAT)和“Composed”(仅ACT)。请注意,如果您的分析目标是不同的,例如比较2017年至2018年之间的SAT性能,则必须保留每个绩效类别(例如数学)的具体数据。与手头的任务保持一致,我们可以使用.Drop()方法,如下所示:
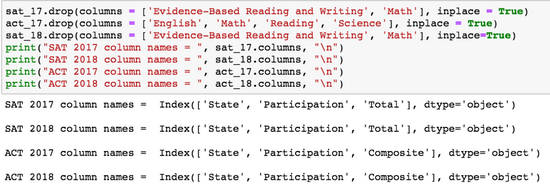
现在数据帧都有相同的维度!不幸的是,仍有许多工作要做。让我们看看是否缺少任何数据,并查看所有数据帧的数据类型:
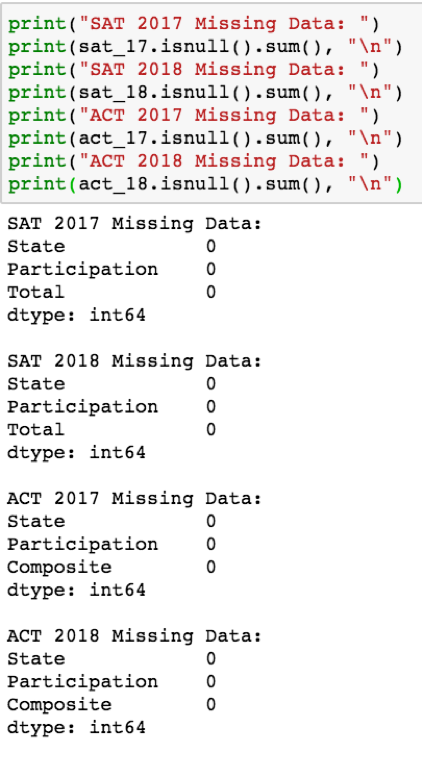
使用.isnull().sum()检查丢失的数据
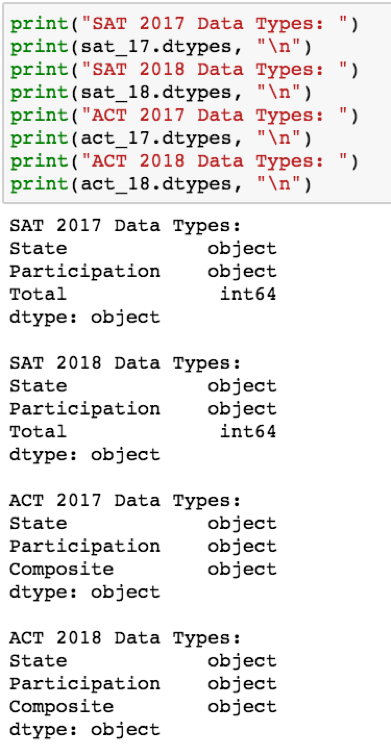
用.dtype检查数据类型
好消息是数据中没有不存在的值。坏消息是数据类型中的错误,特别是每个数据框架中的“参与式”列都是对象类型,这意味着它被认为是一个字符串。这是有问题的,因为在探索数据时要观察的许多有用的可视化需要数值类型变量才能发挥作用,例如相关热图、方框图和直方图。在两个ACT数据帧中的“复合”列中也出现了同样的问题。让我们看一下2018年SAT和ACT 2018年数据的前五行:

2018年沙特德士古公司的前5行数据。
前5行ACT 2018年数据。
您可以看到,“复合”和“参与”应该是浮动类型的。良好的实践是保持您想要比较的数字数据类型的一致性,因此可以将“Total”转换为浮动类型,而不会损害数据的完整性(整数=1166,浮点数=1166.0)。这种类型转换的第一步是从每个“参与式”列中移除‘%’字符,以便将它们转换为浮点数。下一步是将所有数据转换为浮动,但每个数据帧中的“State”列除外。这可能是乏味的,给我们另一个伟大的机会,创造一个功能,以节省时间!我的解决方案如下所示:

注:https:/stackabuse.com/lambda-Funcs-in-python/是学习如何在Python 3中使用lambda函数的一个很好的资源。
是时候让这些功能发挥作用了。首先,让我们使用FIX参与()职能:
现在,我们可以使用转换为浮动()职能:

但是等等!运行转换为浮动()函数应该引发错误。根据您正在使用的IDE,错误消息可能非常有用。在木星笔记本中,这一错误明确地指向了ACT 2017数据框架中的“复合”列。若要更仔细地查看这些值,请使用。值计数()方法:

看起来,我们的罪魁祸首是数据中的“x”字符,很可能是由于将数据输入到原始文件时输入错误的结果。若要删除它,请使用.条子()方法中的.申请()方法,如下所示:
太棒了!现在,尝试再次运行此代码,所有数据都将具有正确的类型:
在我们开始可视化数据之前的最后一步是将数据合并到一个数据框架中。为了实现这一点,我们需要重命名每个数据帧中的列,以描述它们各自所代表的内容。例如,2018年SAT中“参与”一栏的一个好名称是“sat_参与权_17”。当数据被合并时,这个名称更具描述性。另一个注意事项是下划线表示法,以消除访问值时冗长的间距错误,以及用于加快键入速度的小写约定。数据命名约定由开发人员决定,但许多人认为这些都是很好的实践。您可以将列重命名如下:

为了在没有错误的情况下合并数据,我们需要对齐“state”列的索引,使其在数据帧之间保持一致。我们通过对每个数据帧中的“state”列进行排序,然后按照从零开始的顺序重置索引值:

最后,我们可以合并数据。我不是一次合并所有四个数据帧,而是一年一次合并两个数据帧,并确认每个合并都没有出现错误。下面是每个合并的代码:

2017年SAT和ACT合并了数据框架。
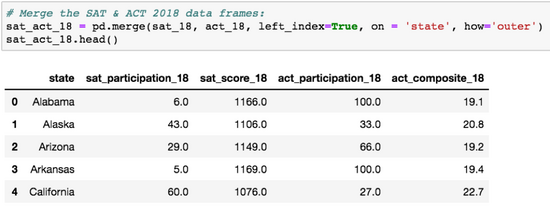
2018年SAT和ACT合并了数据帧。
数据帧的最终合并。
一旦您清理了数据,保存它是一个好主意,这样您就不必再经历清理它的过程了。使用Pandas中的pd.to_csv()方法:
设置index=false保存数据时没有索引值。
是时候把数据可视化了!现在,我们可以使用Matplotlib和Seborn来更仔细地查看我们的干净和组合的数据框架。在查看直方图和方框图时,我将把重点放在可视化参与率的分布上。在检查热图时,将考虑所有数据之间的关系。
可视化数据分布-海运直方图

直方图表示数值出现在数据集中特定范围内的频率(例如,数据中有多少值在40%-50%的范围内)。从直方图中,我们可以注意到,2017年和2018年,更多国家的ACT参与率为90%至100%。相反,2017年和2018年参加SAT的国家较多,参与率为0%至10%。我们可以推断,90%-100%ACT参与率的国家的更高频率可能是由于某些要求接受ACT的规定所致。
可视化数据分配-Matplotlib框图
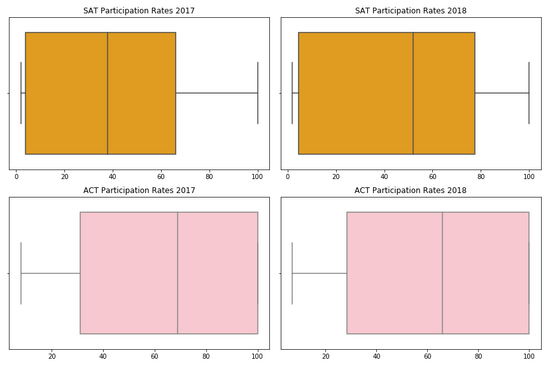
方框图表示数据的传播,包括最小、最大和四分位数范围(IQR)。四分位数范围由第一个分位数、中位数和第三个分位数组成。根据上面的方框图,我们可以看到,从2017年到2018年,SAT参与率总体上有所提高。我们可以注意到的另一件事是,2017年至2018年,ACT参与率保持一致。这就提出了为什么SAT参与率总体上有所增加的问题,尽管ACT参与率并没有显著变化。
计算和可视化关联-海热图
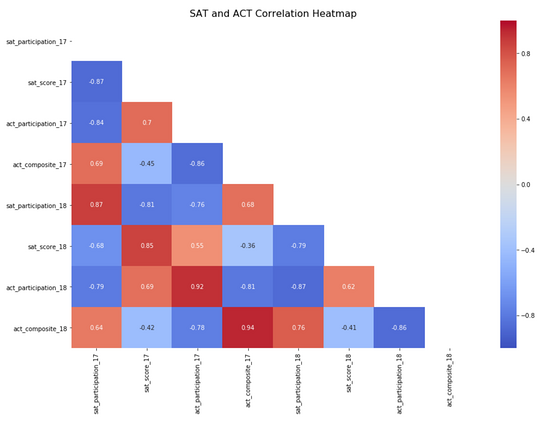
更强的关系用热图中接近负值或正值的值来表示。较弱的关系由接近于零的值表示。正相关变量,即零变量和正变量之间的相关值,表明一个变量随着另一个变量的增加而增加。负相关变量,即负1和零之间的相关值,表明一个变量随着另一个变量的增加而减少。应进一步审查关系密切的变量包括2017年参加SAT和2018年参加SAT,2017年ACT综合评分至2017年ACT参与,2018年ACT参与和2018年SAT参与。还有更多的关系需要进一步研究,但这些都是指导研究这些关系存在的良好起点。
结论
彻底的探索性数据分析确保您的数据是干净的,可用的,一致的,直观的可视化。请记住,没有干净的数据,所以在您开始使用数据之前研究数据是一个很好的方法,可以在数据分析过程开始之前为其添加完整性和价值。通过对你的数据进行强有力的探索来指导外部研究,你将能够有效和高效地获得可证明的洞察力。






发表评论