探索性数据分析(EDA:Exploratory Data Analysis)用于探索我们正在处理的数据的不同方面。在创建模型或通过数据集进行预测之前,应进行EDA以发现数据集具有的模式、视觉洞察等。EDA是通过可视化数据集来识别我们正在处理的数据特征的一般方法。在执行任何正式建模或创建假设检验模型之前,应进行EDA以可视化数据告诉我们的内容。
分析数据集是一项繁琐的任务,并且需要大量时间。根据一项研究,EDA需要机器学习项目的约40%的工作量,但它不能被消除。
Sweetviz是什么?
Sweetviz是一个开源的Python库,它可以通过一行代码生成美观、高密度的可视化图表,以快速启动探索性数据分析(EDA)。输出是一个完全自包含的HTML应用程序或在jupyter notebook 内使用,SmartNotebook 也十分方便安装和使用Sweetviz。
该系统围绕着快速可视化目标值和比较数据集而构建。其目标是帮助快速分析目标特征、训练数据与测试数据之间的差异,以及其他类似的数据表征任务。
Github 地址:
Sweetviz比Pandas Profiling更好
Sweetviz比Pandas Profiling更好的原因在于它具有更强大的功能;除了只需两行代码即可创建具有洞察力和美观的可视化图表之外,它还提供了一些手动生成需要更多时间的分析,包括其他库无法提供的一些分析,比如:
a) 比较两个数据集(例如,训练集与测试集)
b) 将目标值与所有其他变量进行可视化对比(例如,“男性与女性的生存率是多少”等)
c) 在大型数据集和包含许多分类特征的数据集上,Pandas Profiling往往会给出糟糕的错误。
因此,Sweetviz提供了更方便、更强大和更稳定的功能,可以更快速地完成探索性数据分析任务。
安装Sweetviz
pip install sweetviz
加载数据集
数据参考(House Prices: Advanced Regression Techniques):
import pandas as pd
train=pd.read_csv('/home/house_price/train.csv')
test=pd.read_csv('/home/house_price/test.csv')
print(train.head(2))
print(test.head(2))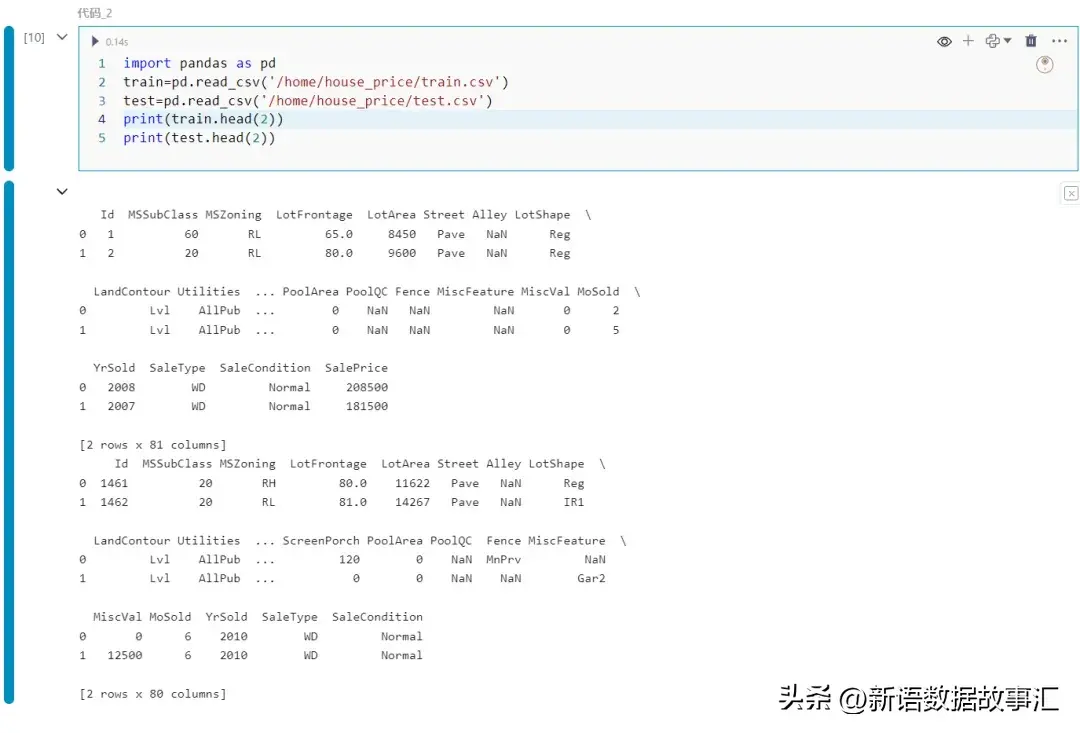
示例1:分析单个数据框架(训练集)
import sweetviz as sv
report = sv.analyze([train,"Train"],target_feat = 'SalePrice')
report.show_notebook()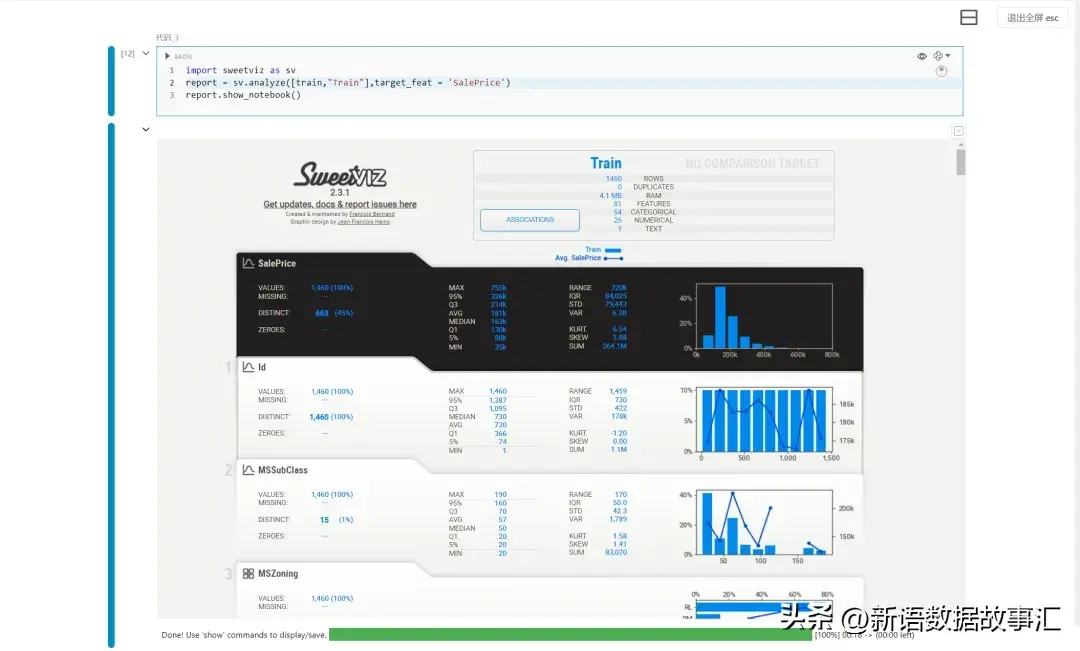
示例2:比较两个数据集进行高级分析(例如测试集与训练集的比较)
report1 = sv.compare([train,"Train"],[test,"Test"],"SalePrice")
report1.show_notebook()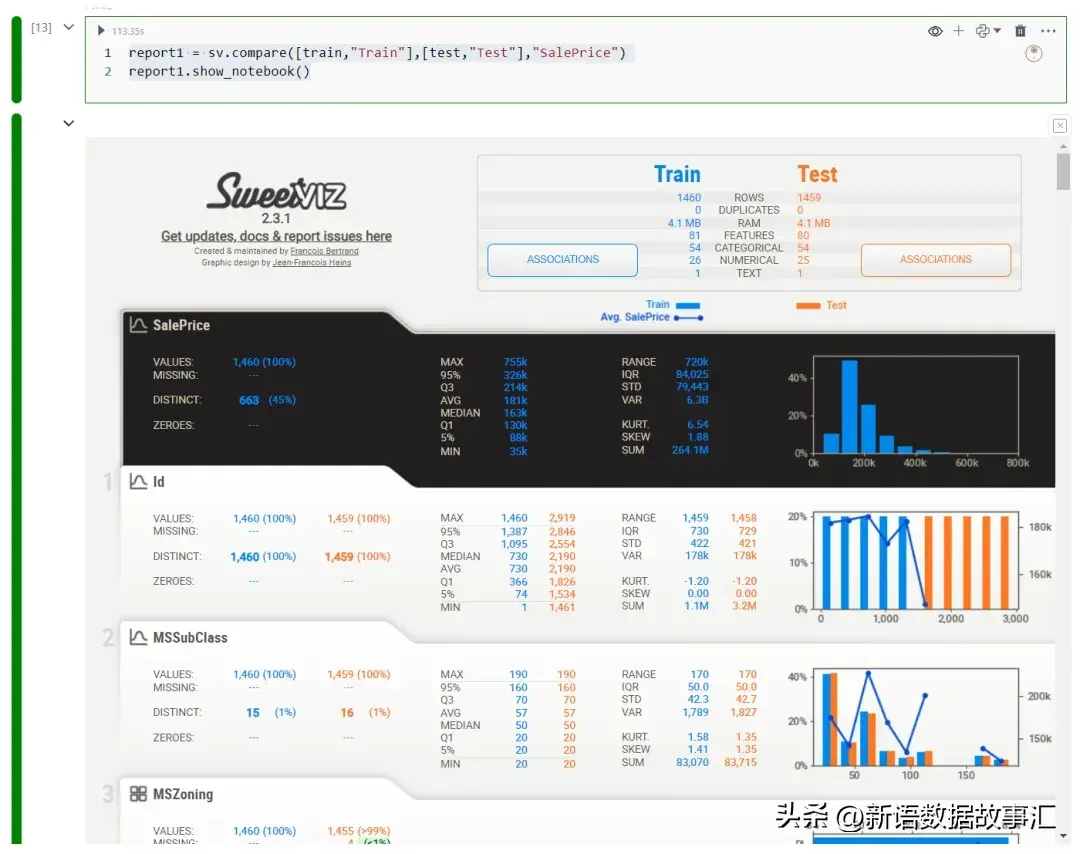
蓝色代表训练集,橙色代表测试集。现在让我们深入挖掘,看看从Sweetviz自动EDA中获得了哪些洞察!
总结显示(SUMMARY)
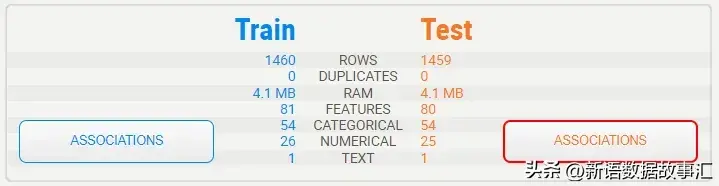
总结显示了训练集和测试集的特征,以并排的方式呈现。我们可以确定数据集中没有重复项。底部的图例显示,训练集包含“SalePrice”目标变量,而测试集不包含。
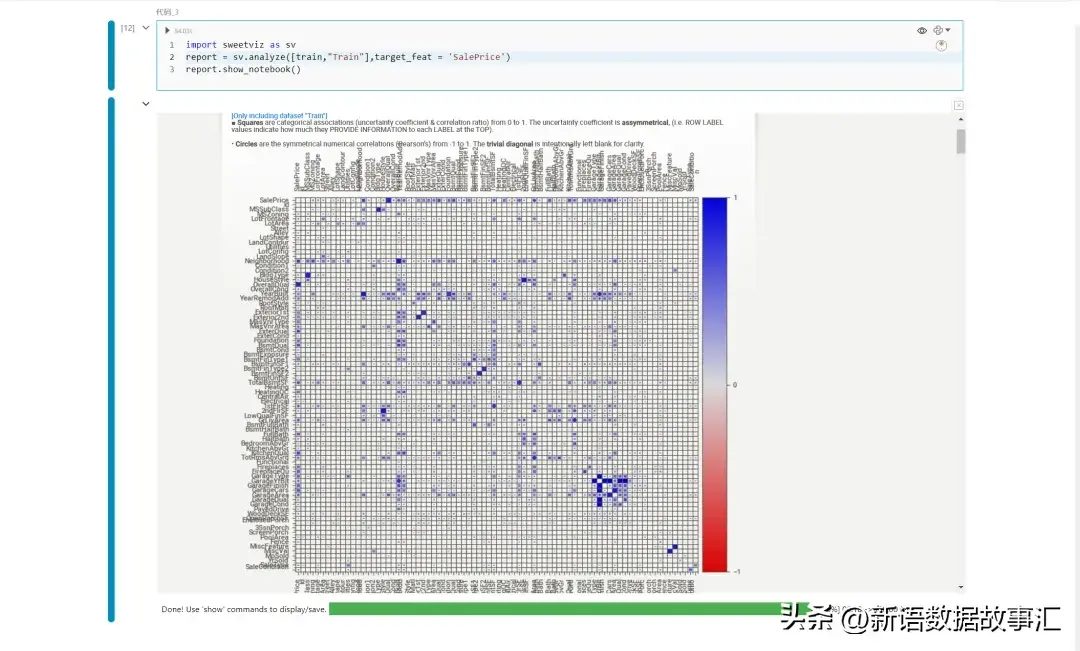
关联(ASSOCIATION )
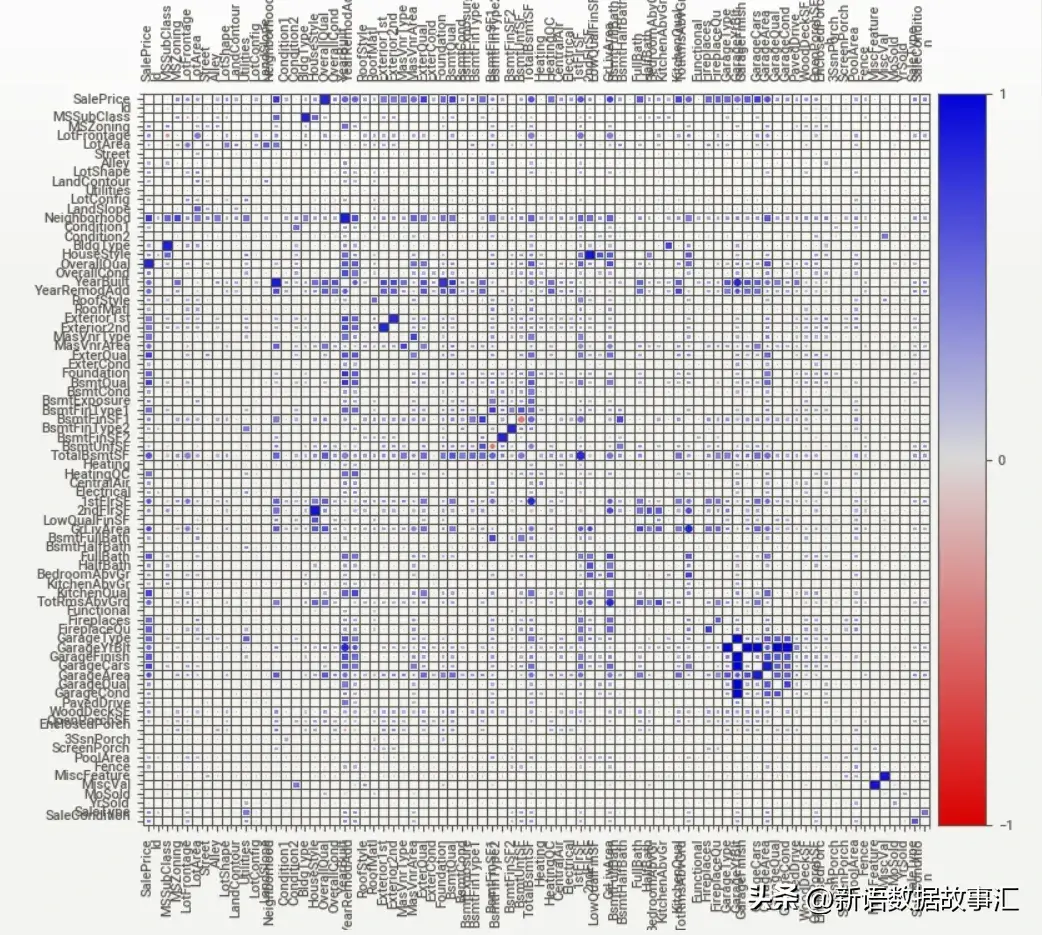
除了显示传统的数值相关性外,它还将数值相关性、不确定系数(对于分类-分类)和相关比率(对于分类-数值)统一在一个图表中。方块表示与分类特征相关的变量,圆圈表示数值-数值相关性。
最后,值得一提的是,这些相关性/关联方法不应被视为绝对,因为它们对特征数据的基础分布进行了一些假设。然而,它们对快速查看非常有用。
目标变量( TARGET VARIABLE )
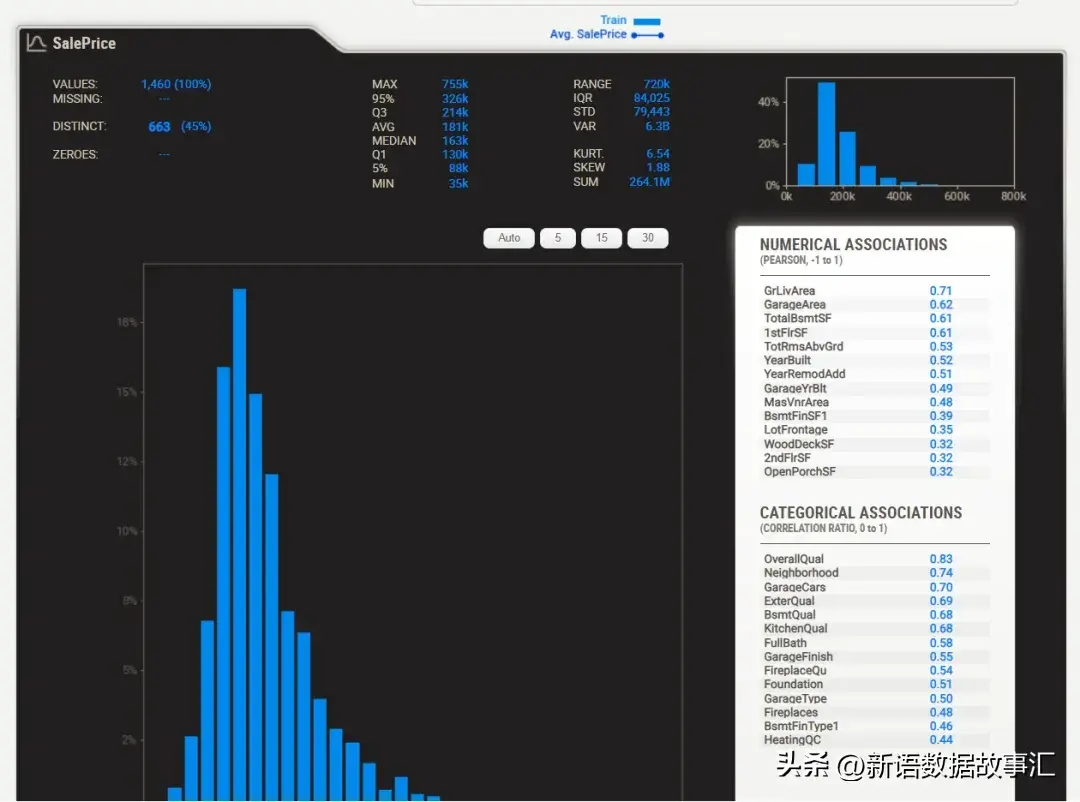
目标变量分析(SalePrice):当指定了目标变量时,它会出现在顶部,以黑色方框显示。
从这个总结中,我们可以得知“SalePrice”在训练集中没有缺失数据(1460,100%),有663个不同的可能值(占所有值的不到46%),从图表中可以估计大约40%-45%的SalePrice在20万左右。
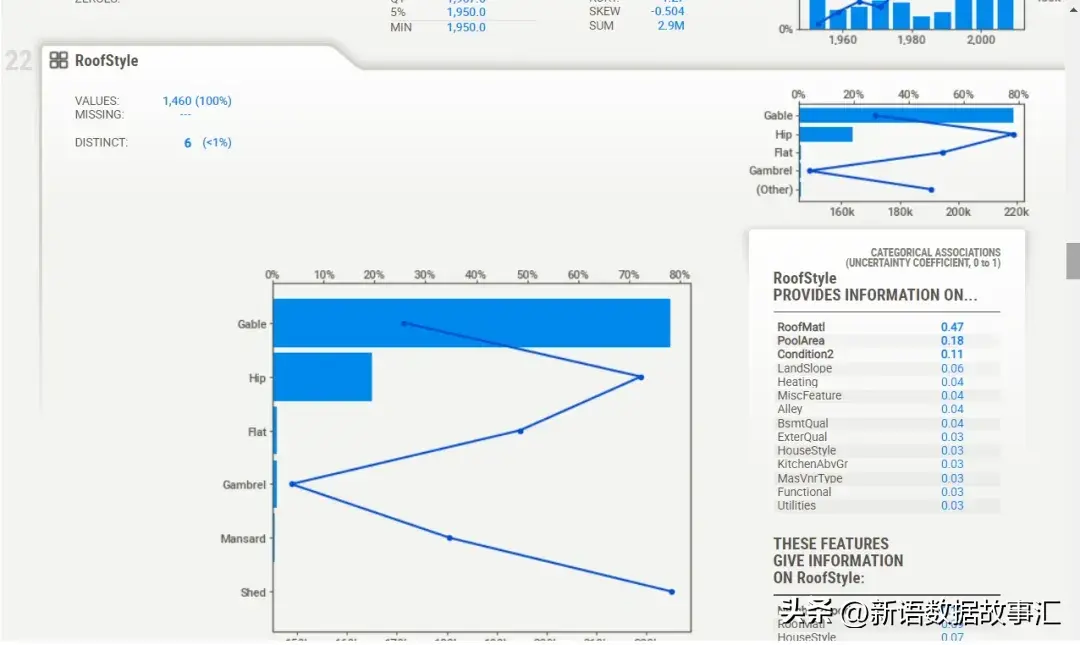
分类特征详细信息(CATEGORICAL FEATURES)
标记为分类特征的特征,可能是没有描述性统计报告的分类特征。
数值特征详细信息(NUMERICAL FEATURES)
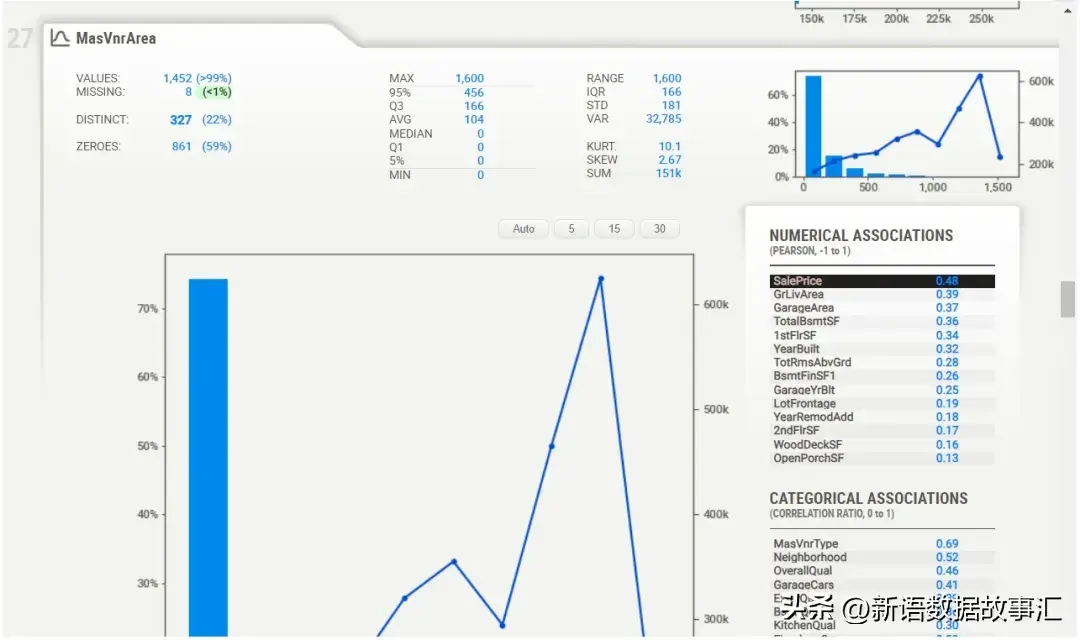
数值数据显示了更多的摘要信息。它可以提供描述性统计详情,而不像分类/布尔特征那样。
使用Sweetviz可以轻松地为我在开始查看新数据集时提供重要的起步。特别是在特征工程和特征选择阶段,可以快速了解各种特征的概况。希望您在自己的数据分析中也会提升效率。






发表评论