
当开始一个新的机器学习项目时,获得机器学习数据集之后的第一步就是要了解它。我们可以通过执行探索性数据分析(EDA)来实现这一点。这包括找出每个变量的数据类型、目标变量的分布、每个预测变量的不同值的数量、数据集中是否有重复值或缺失值等。进行EDA探索机器学习数据集的过程往往是非常耗时的。
什么是Pandas-Profiling?
Pandas-profiling是一个开源Python库,它只需一行代码即可为任何机器学习数据集生成漂亮的交互式报告。
pandas_profiling使用df.profile_report()扩展了DataFrame,以便进行快速数据分析。
每一列的以下统计数据(如果与列类型相关)都显示在交互式HTML报告中:
安装Pandas-profiling
您可以使用pip软件包管理器通过以下命令进行安装:
pip install pandas-profiling[notebook,html]您也可以直接从Github安装最新版本()。
生成报告
在本文中,我将使用的机器学习数据集是Titanic。
加载Python库
import pandas as pd
import pandas_profiling
from pandas_profiling import ProfileReport
from pandas_profiling.utils.cache import cache_file导入机器学习数据集
file = cache_file("titanic.csv","https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
data = pd.read_csv(file)
data.head()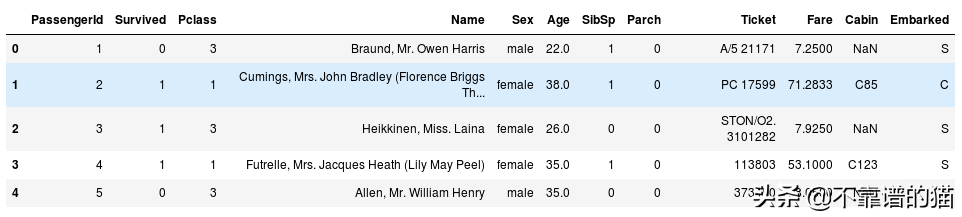
要生成报告,请运行以下Python代码。
profile = ProfileReport(data, title="Titanic Dataset", html={'style': {'full_width': True}}, sort="None")
将报告作为IFrame包含在Notebook中
profile.to_notebook_iframe()使用以下代码将报告另存为HTML文件:
profile.to_file(output_file="your_report.html")使用以下方式将数据保存为JSON:
# As a string
json_data = profile.to_json()
# As a file
profile.to_file(output_file="your_report.json")结果
现在我们知道了如何使用pandas-profiling生成报告,让我们看一下结果。
概要:
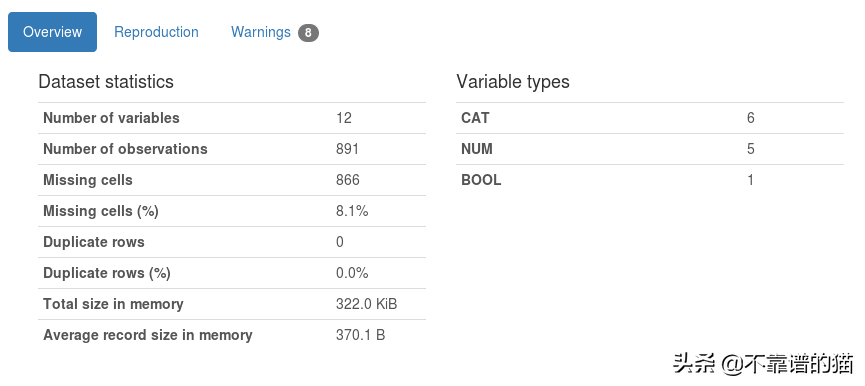
Pandas_profiling通过计算预测变量的总缺失单元格、重复行、不同值的数量、缺失值、zeros来创建预测变量的描述性概述。它还在警告部分标记具有高基数或缺失值的变量,如上图所示。
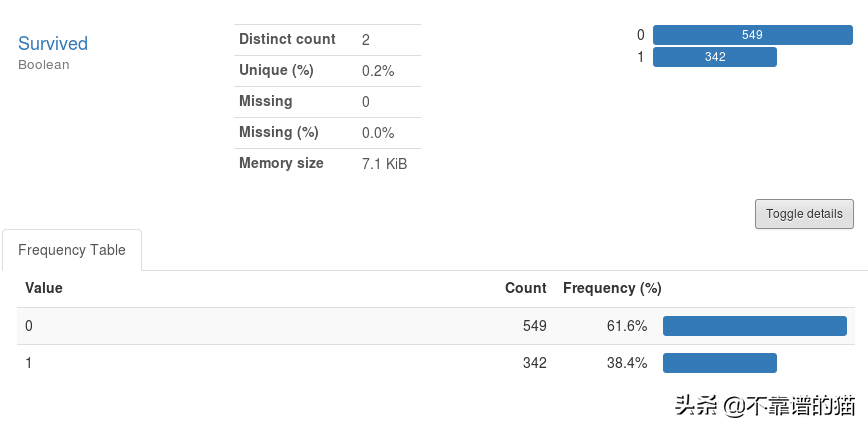
类分布
数值特征:
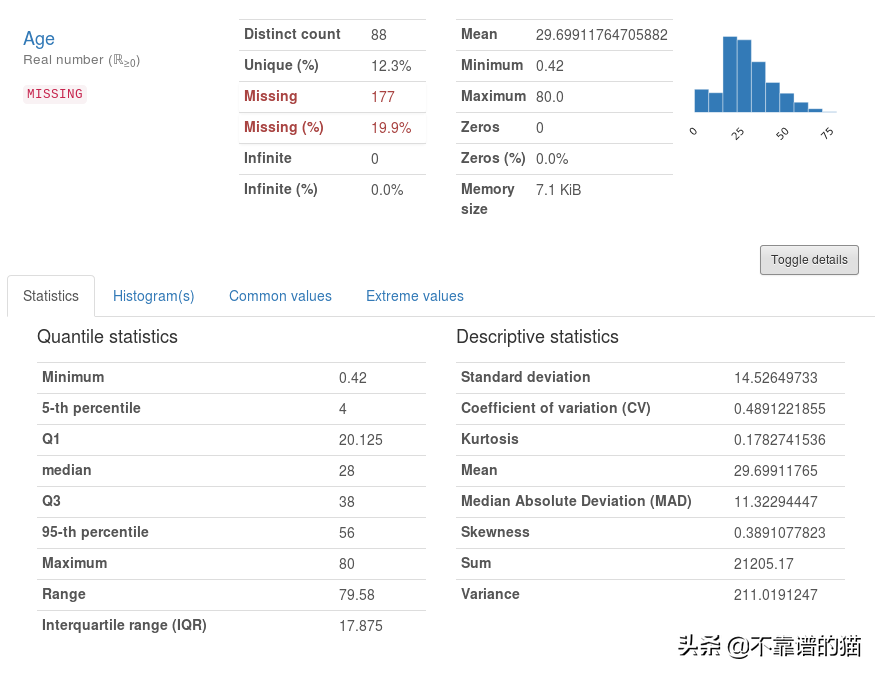
对于数值特征,除了有均值、标准差、最小值、最大值、四分位距(IQR)等详细统计外,还绘制了直方图,给出了常用值和极值的列表。
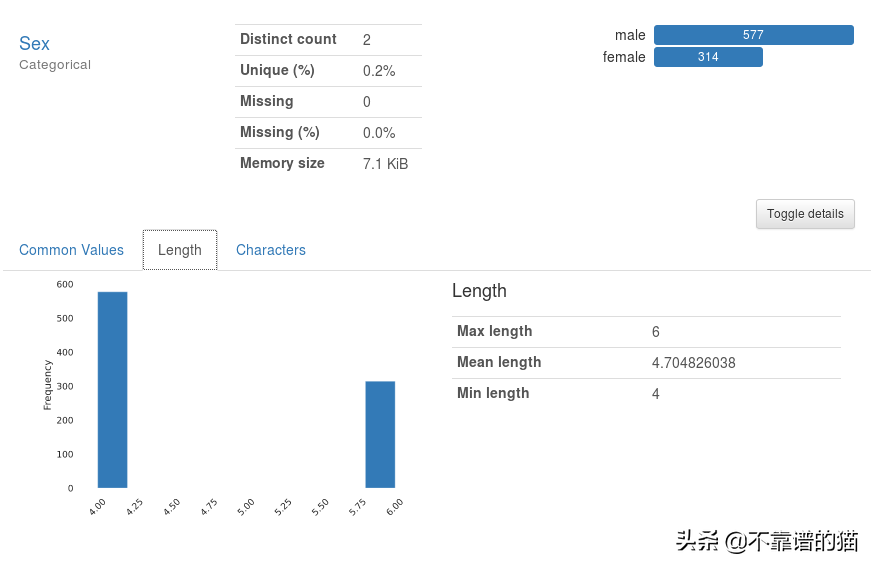
分类特征:
与数字特征类似,对于分类特征,它会计算通用值,长度,字符等。
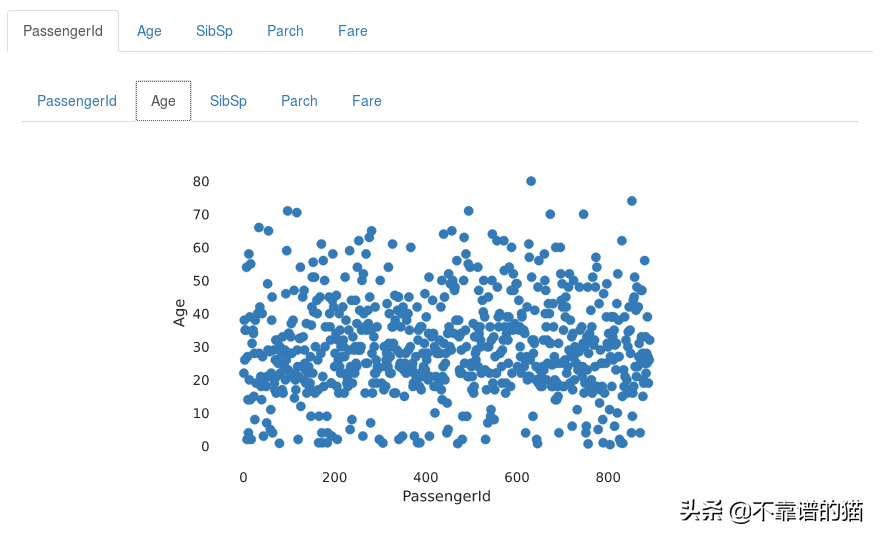
交互
在交互部分,pandas_profiling库自动为每一对变量生成交互图。您可以通过从两个标题中选择特定的变量来获取任何一对的交互关系图。
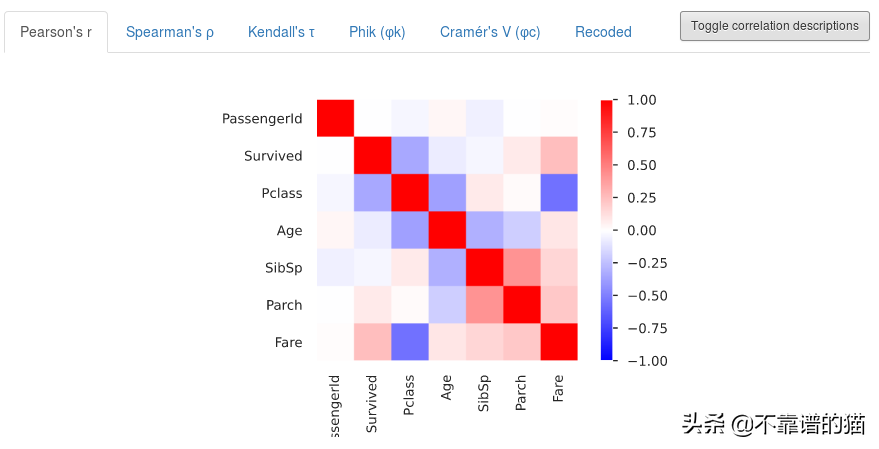
相关矩阵:
相关性是一种统计技术,它可以显示变量对之间是否相关以及如何相关。
相关的主要结果称为相关系数(或“r”)。它的范围是从-1.0到+1.0。r越接近+1(或-1),这两个变量的关系就越密切。如果r接近0,这意味着变量之间不相关。如果r是正的,这意味着一个变量变大,另一个变大。如果r是负的,这意味着随着一个变大,另一个变小(通常称为“逆相关”)。
在生成所有数值特征的相关矩阵时,pandas_profiling库为我们提供了所有流行的选项,包括Pearson的r,Spearman的ρ等。
缺点
pandas-profiling的主要缺点是针对大型机器学习数据集。随着数据量的增加,生成报告的时间也增加了很多。
解决此问题的一种方法是为数据集的一部分生成概要报告。但是在执行此操作时,确保对数据进行随机采样非常重要,这样它才能代表我们拥有的所有数据。我们可以这样做:
from pandas_profiling import ProfileReport
# Generate report for 10000 data points
profile = ProfileReport(data.sample(n = 10000), title="Titanic Data set", html={'style': {'full_width': True}}, sort="None")
# save to file
profile.to_file(output_file='10000datapoints.html')如果您坚持要获得关于整个数据集的报告,您可以使用最小模式来实现这一点。在最小模式下,生成的简化报告比完整报告的信息要少,但对于大型数据集,生成的速度相对较快。简化报告的代码如下:
profile = ProfileReport(large_dataset, minimal=True)
profile.to_file(output_file="output.html")




发表评论