集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。
Complexity Express 一周论文精选
以下是2022年7月4日-7月10日来自Complexity Express的复杂性科学论文精选。如果Complexity Express列表中有你感兴趣的论文,欢迎点赞推荐,我们会优先组织解读~
目录:
1. 自适应网络中的记忆形成
2. 具有 DNA 调节回路的分子卷积神经网络
3. 民主人工智能帮助实现以人为中心的机制设计
4. 对系统发育的深度学习揭示疾病爆发的流行病动力学
5. 视听适应表现在空间编码和决策编码中
6. 200 年来谷歌图书的词嵌入反映社会群体的历史表征
7. 未来城市变暖的不平等劳动力流失风险及适应对策
8. 2020-2021年新冠疫情相关论文对整体科研引文的影响
9. 科学的公共使用和公共资助
1. 自适应网络中的记忆形成

论文题目:Memory Formation in Adaptive Networks 论文来源:Physical Review Letters 论文链接:
网络的持续自适应,确保了在面对不断变化的负载时依旧保持最佳性能,例如我们的血管分布网络。本文作者展示了自适应动力学允许网络在其网络结构中记住应用负载的位置。作者发现,消失的网络连接的不可逆的动力学编码了记忆。作者的分析理论成功地预测了所有系统参数在记忆形成过程中的作用,包括阻止记忆形成的参数的值。基于此,作者为无序系统中的记忆形成理论提供了分析见解。
作者想要探究在一个固定结构的持续自适应网络中存储过去信息的能力和表现形式。该持续自适应网络类似于一个流动网络,每对节点都有流量值 Qij(t) 且大于 0,中心点流量值为各个点流量值之和的负值以表明它是网络唯一的流出点。各个节点的电导率 Cij(t),同时每个节点还会受到负载 qi(t),对这三个参数的数学描述构成了整个网络的自适应动力学表达。施加的刺激在网络结构上形成了一个树状结构,如图(a)。然而,当刺激负载被移除时,系统很快恢复到一个看似各向同性的结构,如图(b)。图c中刺激节点周围的损失函数(Power loss)是最小的,这表明由于刺激的记忆,这个配置是更优化的。图(d)表明输出信号受到两部分的影响,一是和训练时间 ttrain 相关的,表明网络记住了在训练期间的信息并对输出产生影响,另一部分是和等待时间 twait 有关。
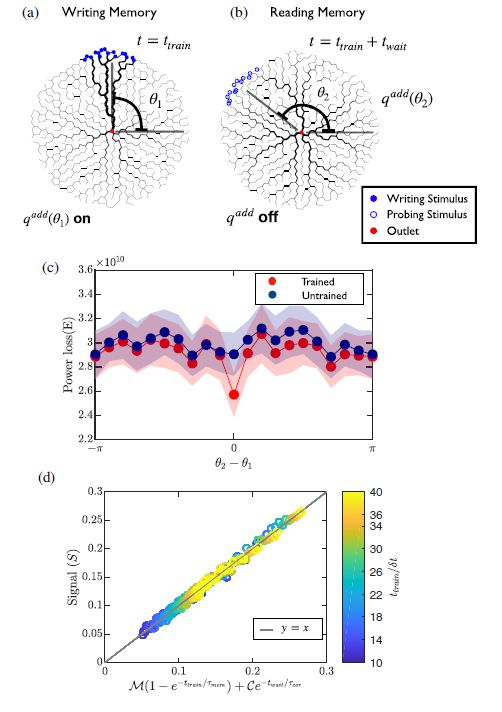
图:(a)图是作者使用的自适应网络标准模型,由 N 个节点和连边构成,是一个固定结构的网络,作者在外界随机选择一个接点施加负载,中心红点表示网络的唯一出口点,在训练期间网络表现以及等待一段时间之后网络表现如图(a, b)所示。(c)展示在施加负载的节点的周围(-π,π)范围内,损失函数的表现。(d)表明输出信号值和训练时间 ttrain 以及等待时间 twait 的线性关系。
2. 具有DNA调节回路的
分子卷积神经网络

论文题目:Molecular convolutional neural networks with DNA regulatory circuits 论文来源:Nature Machine Intelligence 论文链接:
复杂的生物分子回路使具有智能行为的细胞在神经大脑进化之前得以存活。自 20 世纪 90 年代中期首次展示 DNA 计算以来,液相合成 DNA 电路就已被开发为计算硬件,利用复杂生化系统的集体特性来执行类似神经网络的计算。然而,扩大基于 DNA 的神经网络进行更强大的计算仍是一个挑战。在这里,作者提出了一个基于简单的开关门架构的合成 DNA 调控电路,来进行卷积神经网络算法的系统分子实现。作者设计的基于 DNA 的权重共享卷积神经网络可以同时对 144 位输入执行并行的乘法累加操作,并自主识别多达 8 个类别的模式。此外,该系统还可以与其他 DNA 电路连接,构建层次网络,来识别多达 32 个类别的模式,这里需要两个步骤:先对语言进行粗分类(阿拉伯数字、中国甲骨文、英语字母和希腊字母),然后再分类到具体的手写符号。作者还使用简单的循环冻融方法将计算时间从几小时减少到几分钟。作者设计的基于 DNA 的调控电路是朝着实现高计算能力和分类复杂和噪声信息的分子计算机的目标前进的一步。
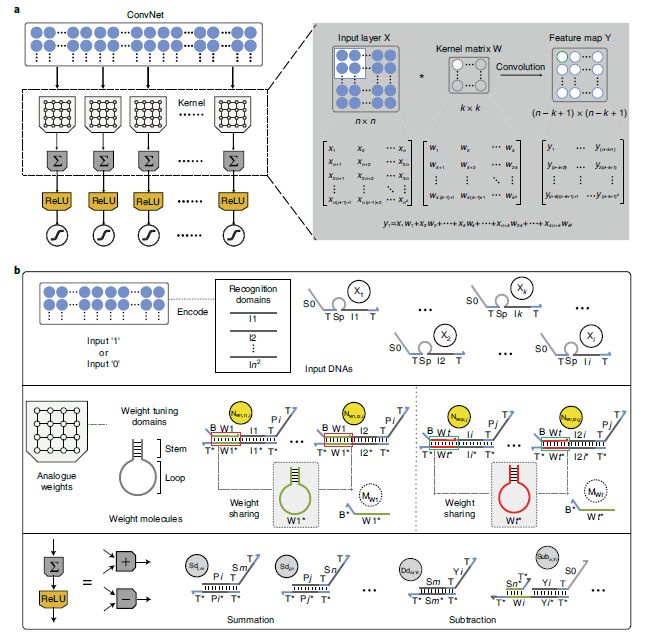
图:ConvNet 及其利用 DNA 调控回路系统的分子实现。(a)是ConvNet的架构以及ConvNet执行识别任务的工作原理示意图。b图是 ConvNet 利用 DNA 调控回路系统的实现示意图。(b)上方表示的是输入可以用一组单链编码 X1~Xi,其中1或0表示输入链的存在或不存在,(b)中间表示权重矩阵可以通过编写一组具有简单开关门结构的权重分子来存储。权重调优域的序列来对共享权重进行分配。(b)下方表示求和和减法的 DNA 实现。
3. 民主人工智能
帮助实现以人为中心的机制设计

论文题目:Human-centred mechanism design with Democratic AI 论文来源:Nature Human Behaviour 论文链接:
构建符合人类价值观的人工智能是一个未解决的问题。在这里,我们开发了一个名为“民主人工智能(Democratic AI)”的人在环路(human-in-the-loop )研究流程框架,其中使用强化学习来设计一种大多数人都喜欢的社会机制。一大群人玩一个在线投资游戏,其中包括决定是保留一个货币捐赠还是与其他人分享以获得集体利益。共享收入通过两种不同的再分配机制返还给玩家,一种由人工智能设计,另一种由人类设计。人工智能发现了一种机制,可以纠正最初的财富不平衡,制裁搭便车者并成功赢得多数票。通过针对人类偏好进行优化,民主人工智能为价值导向的政策创新提供了概念验证。
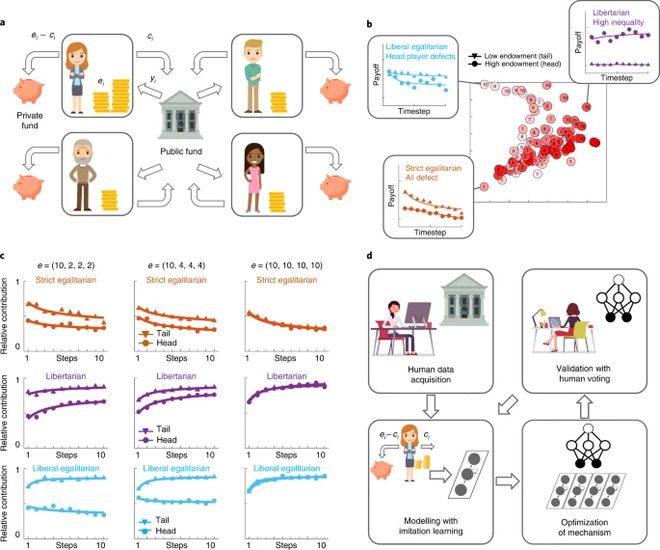
图 :游戏和实验说明。(a)投资游戏设置说明。(b)该图显示了由参数 w 和 v 定义的二维再分配机制空间的可视化。每个红点是一个机制,点与点之间的距离保留了对虚拟参与者的相对报酬的差异。(c)在实验中,三种不同的初始捐赠条件下,10 轮的平均相对贡献(作为捐赠的一部分,X 轴)。在严格的平等主义再分配下,当初始禀赋较低时,尾部玩家(三角形)的贡献较高,但头部玩家(圆圈)的贡献没有区别。在自由主义下,头部玩家的贡献随着平等而增加,但尾部玩家的贡献保持不变。在自由平等主义下,头部玩家的贡献随着禀赋的增加而强烈增加。
4. 对系统发育的深度学习
揭示疾病爆发的流行病动力学

论文题目:Deep learning from phylogenies to uncover the epidemiological dynamics of outbreaks 论文来源:Nature Communications 论文链接:
为了充分利用丰富的遗传数据来揭示流行病动力学特征,我们需要广泛适用、准确且快速的系统动力学推理方法。包括最大似然法(maximum-likelihood approach)和贝叶斯方法(Bayesian approach)在内的的标准方法通常依赖于复杂的数学公式和近似值,且不随数据集大小而扩展。本研究开发了一种无似然的、基于模拟的方法,它将深度学习与系统发育的大量汇总统计数据集或完整而紧凑的树的表示法相结合,避免了汇总统计数据的潜在限制并能够适用于任何系统动力学模型。该方法能够从非常大的系统发育中选择模型并估计流行病学参数。研究者在模拟数据上证明了其速度和准确度超越了目前最先进的方法。为了说明其适用性,研究者用其评估了苏黎世地区男性同性性关系群体 HIV 数据集中超级传播个体引起的流行病动力学。本研究的工具 PhyloDeep链接:github.com/evolbioinfo/phylodeep
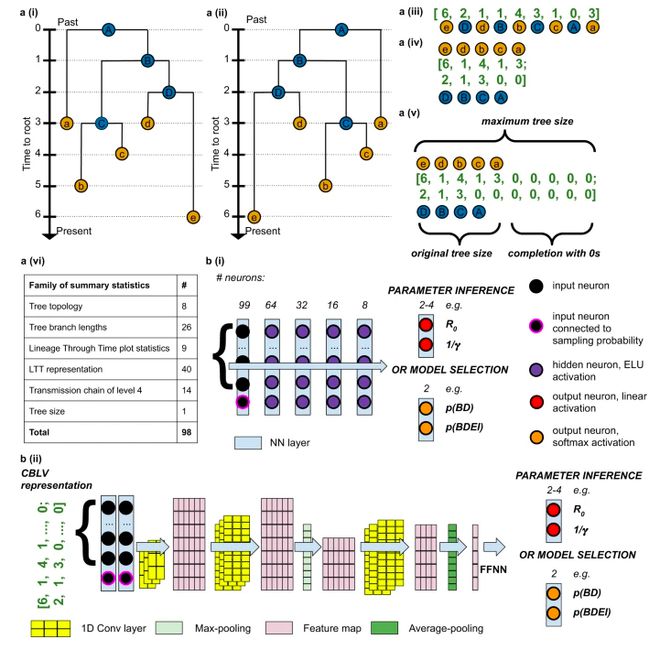
图:根据系统发育训练神经网络的示意图。(a)树表示形式;(b)根据这些表示训练神经网络来估计参数值或选择底层模型。
5. 视听适应
表现在空间编码和决策编码中

论文题目:Audiovisual adaptation is expressed in spatial and decisional codes 论文来源:Nature Communications 论文链接:#Fig1
面对环境所带来的动态感官输入,大脑总是不断适应这些变化。最近的一项研究尝试对支持这种跨感官可塑性的神经回路和表征进行描述。结合精神物理学和基于模型的具象功能磁共振成像和脑电图,研究者发现了成人大脑如何适应失调的视听信号。这种视听适应与从颞横回到背外侧前额叶皮质广泛网络中的区域性BOLD反应(一种空间和决策线性混合模型)以及精细活动模式的变化有关:视听重新校准依赖于以相反的梯度和时间进程表示的不同空间和决策编码。听觉皮层的早期活动模式在连续空间中编码声音以灵活适应错位的视觉输入,而后脑额顶叶皮层的活动模式编码了与这些空间转换相一致的决策不确定性。研究结果表明,听觉处理区域的层次、多重空间和决策编码可以灵活地适应环境中变化的感觉统计量。
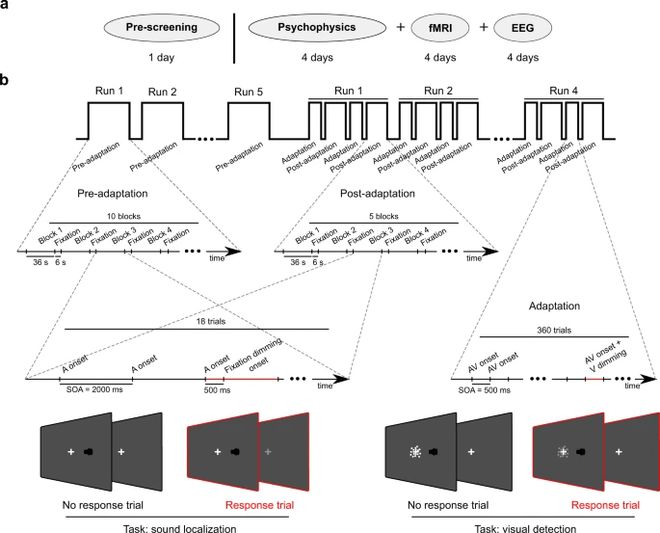
图:研究与实验设计。(a)表示研究设计包括了1天预检查、4天神经物理学测试、4天功能磁共振呈现和4天脑电图。(b)则具体地展示了视听适应前后不同阶段的刺激及相应任务。
6. 200年来谷歌图书的词嵌入
反应社会群体的历史表征

论文题目:Historical representations of social groups across 200 years of word embeddings from Google Books 论文来源:PNAS 论文链接:
使用谷歌英语图书中 8500 亿个单词的词嵌入,我们针对大量社会群体目标,对社会群体表征(刻板印象)在很长一段时间内(1800-1999 年)的历史变化和稳定性进行了广泛分析(黑人、白人、亚洲人、爱尔兰人、西班牙裔、美洲原住民、男人、女人、老、年轻、胖、瘦、富、穷),以及它们与 14,000 个单词和 600 个特征子集的自下而上的涌现关联。结果提供了 200 年来刻板印象的变化和持久性的细致入微的画面。在最相关的词和特征中观察到了变化:无论是分析前 10 个还是前 50 个相关词,至少 50% 的顶级相关词在连续几十年中发生了变化。尽管顶级相关词的内容不断变化,但这些顶级刻板印象的平均效价(积极/消极)通常是持久的。最终,通过历史词嵌入可用性的进步,本研究全面描述了社会群体表征的变化和持久性,正如从 1800 年到 1999 年英语世界的书籍所揭示的那样。
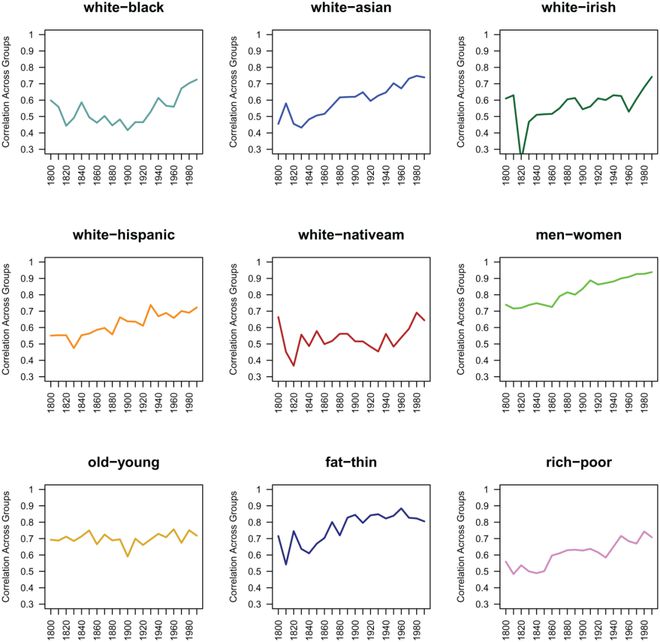
图:200 年(1800 年至 1999 年)历史英语文本中两组特征表征的跨组相关性。更高的相关性表明在每个相关性上面列出的两个比较组之间有更大的重叠。
7. 未来城市变暖的
不平等劳动力流失风险及适应对策

论文题目:The inequality labor loss risk from future urban warming and adaptation strategies 论文来源:Nature Communications 论文链接:
高温引起的劳动损失是与气候变化有关的主要经济成本。在此,我们使用区域气候模型模拟的每小时热应激(heat stress)数据来研究 231 个中国城市的高温导致的劳动力损失。结果表明, 与 2010 年相比,2050 年的城市热应激预计将导致劳动力损失增加,超过每年国内生产总值(GDP) 总额的0.20%。在这个过程中,某些收入较低的部门可能会受到不成比例的影响。实施各种城市适应战略可以抵消每年 10% 的额外经济损失,并有助于减少与不平等有关的对低薪部门的影响。因此,未来的城市变暖不仅会损害整个城市,也会造成收入不平等。适应战略的影响不仅应考虑到降温要求,而且应考虑到环境正义。
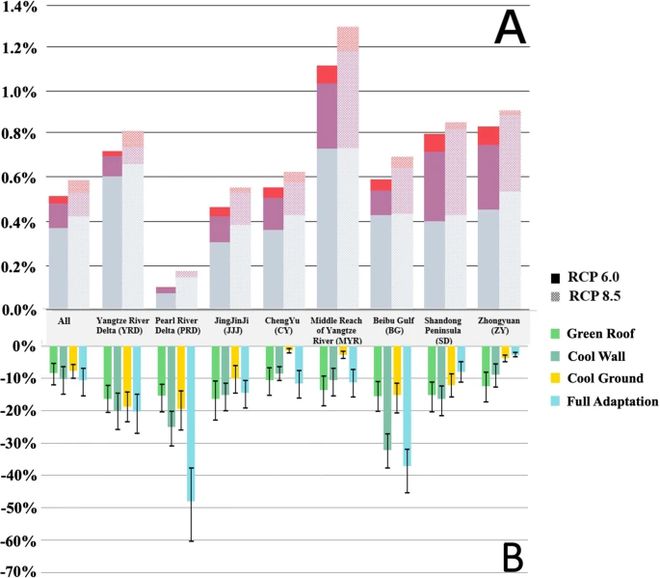
图 :与基线情景相比,GDP 总损失的变化以及通过在所有城市电网中实施适应战略可以防止的经济损失比例。(A)百分比表示在 RCP 6.0 和 RCP 8.5 情景下,与 SSP2 相比,到 2050 年代城市变暖造成的经济损失增加的百分比,三种颜色表示三个部门的总贡献。(B)百分比表示在 RCP 6.0 下不同的城市适应战略(2050-2060年)与未来相对于基线水平的经济损失的额外增加相比,每年减少的百分比。
8. 2020-2021年新冠疫情
相关论文对整体科研引文的影响

论文题目:Massive covidization of research citations and the citation elite 论文来源:PNAS 论文链接:
伴随着新冠大流行的是大规模的科研产出。我们评估了新冠相关论文相对于 2020- 2021 年出版的所有科学著作产生的引用影响,并评估了对科学家引用情况产生的影响。使用 Scopus 数据,发现直到 2021 年 8 月 1 日,新冠项目占发表论文总数的 4% ,这些 2020-2021 年发表的论文收到的引用占全部引用的 20% ,174 个科学学科中的 36 个(医学及内科中引用占比高达 79.3% )收到的引文占 30% 以上。在整个科学界,2020-2021 年发表的 100 篇被引用次数最多的论文中,有 98 篇与新冠有关;110 位科学家的新冠论文被引用次数 ≥10000 次,但 2020-2021 年发表的非新冠论文没有一篇被引用次数 ≥10000 次。对于许多科学家来说,他们的新冠相关工作被引用的次数已经占到了职业生涯总被引用次数的一半以上。总的来说,这些数据显示了引文网络中强大的自我强化趋势,对那些处于精英位置的引文的影响更明显。
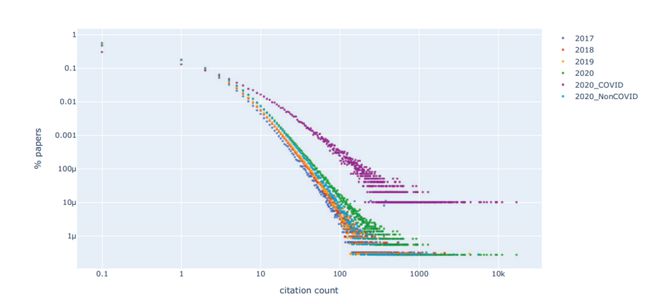
图:2020-2021 年间,不同年份论文及 2020 年之后的新冠相关和非相关论文的引用数目和比例散点图。
9. 科学的公共使用和公共资助

论文题目:Public use and public funding of science 论文来源:PNAS 论文链接:
了解公共科学资金的使用情况对于理解科学在人类社会中的作用至关重要。在这里,我们将来自所有科学领域的数以千万计的科学出版物与它们的上游资金支持和下游公共用途——政府文件、新闻媒体和市场发明这三个公共领域——联系起来,审查公共科学资金的使用情况。我们发现,不同科学领域以不同的方式从不同的科学领域获取资金,获取和使用过程表现出不同的模式。然而,在这些差异中,我们发现了两种重要的一致形式。首先,公众消费的东西和和科学领域具有高度影响力的东西之间存在着普遍的一致性。其次,一个学科的公共资金与该领域的集体公共支出使用惊人地一致。总体而言,公众资助的科学资金使用,呈现出具有专业化的丰富景观,然而,总体而言,科学与社会之间在科学的用途、公共用途和资助之间存在惊人的一致。

图:不同学科在新闻报道、应用于政府和专利上的程度存在显著多样性。
关于Complexity Express
Complex World, Simple Rules. 复杂世界,简单规则。
由于学科交叉融合,大量针对复杂系统的研究成果散落在人工智能、统计物理、网络科学、数据科学、计算社会科学、生命科学、认知科学等等不同领域的期刊会议中,缺乏整合。
为了让大家能及时把握复杂系统领域重要的研究进展,我们隆重推出「Complexity Express」服务,汇总复杂系统相关的最新顶刊论文。
Complexity Express 是什么?
Complexity Express 每天爬取复杂系统领域最新发表的顶刊论文,每周通过“集智斑图”服务号汇总推送。
进入 Complexity Express 页面即可随时查看顶刊论文更新,你也可以通过微信接收研究更新推送和一周汇总。
Complexity Express 为谁服务?
Complexity Express 栏目也是集智俱乐部公众号的主要选题来源,诚挚邀请你订阅,与我们信息同步。
Complexity Express 论文从哪里来?
考虑复杂系统研究往往属于跨学科工作,我们主要抓取综合类和泛物理类/计算机类的顶级期刊,从每周新发表的数百篇论文中精选出与复杂系统相关的论文。
Complexity Express 参考影响因子和学者口碑,选择了如下期刊,每日爬取其论文更新:
如果你在 Complexity Express 中发现了感兴趣的论文,请立刻“点赞”!每周最高赞的论文,集智编辑部将组织专业解读~
Complexity Express 追踪哪些领域?
我们力求兼顾热点追踪与领域覆盖,目前筛选的论文主要集中在如下与复杂性关系密切的领域:
由于复杂性研究领域横跨多个学科,研究论文散落在不同的期刊上,很难不重不漏地把握最新工作。针对复杂性领域的论文筛选,我们专门设计了算法。经过数月的训练迭代优化,目前对上述领域爬取准确率达到90%以上。
将来我们还会根据你的具体研究领域,推出研究分类与个性化的订阅服务,敬请期待!
由于复杂性领域涉及的论文关键词和研究问题纷繁复杂,所以算法难免有不成熟的地方,如果你发现我们有漏掉的重要论文,或者爬到了领域有偏差的论文,欢迎联系我们 (小助手微信:swarmaAI) ,帮助我们持续优化算法。
如果你对科学学、计算术语学等感兴趣并有代码能力,欢迎报名成为集智算法志愿者/实习生 (具体请邮件联系算法组负责人huqiao@swarma.org) 。
如果你对复杂科学及相关跨学科研究有长期兴趣,并乐于解读分享,欢迎加入集智作者团队 (具体请邮件联系编辑部负责人liupeiyuan@swarma.org)。

发表评论