
徐老师2019文史哲系列之八
少壮派英语专家之邀
外语教学专家孙克瑞先生是将自然拼读教学引入国内的第一人。他是北京市的英语教研员,也是徐老师华东师范大学的校友。
《从AI革命洞察外语教学的世纪错误》一文刊发后,孙老师希望我就“超级生物神经算法”,对外语教师多做科普。
其实,徐老师合著的科普书里都扫盲过N遍了。
《中国人英语自学方法教程》外研社第二版22个月印了7刷,《亲子英语原著教育真人秀:原典双语大脑完胜AI》出版后1年已3刷,当当网还常常售罄。口碑相传者,多是家长。
有位学者对我说,喜欢原典法的家长越多,排斥原典法的外语教学专家就越多。
她说的未必对。孙克瑞先生就是例外,他痛感原典法的科普太必要了。
哈佛剑桥的主流外语教学体系故步自封四十年,整个行业思维化石化了。
思想家之问
十多年来鼎力支持原典法科普的李津逵教授提出一个问题:
“为什么100多年来华语世界没有任何一个大思想家或大教育家力主双语双文?”
此千钧之思,可命名为“李津逵之问”。
武夫之恋与胡适之哭
单语单文维度的1948年。
GMD兵败如山倒,老蒋一次就安排了3架次飞机去北京,企图“抢救”著名学者。
这位浙江武夫很萌,人生都输光了,还单相思文人。
胡适亲自随飞机去迎接民国学人,他们都是他多年的挚友。
结果,空无一人。
57岁的胡适,独自在机场,嚎啕大哭。
义和团精英
1948,胡适开启的白话文启蒙运动,已经30年了。启蒙没有解决义和团困境,甚至让学者群体自己沦为“义和团精英”。
学人,不仅自己的大脑都未开悟,最终,他们的肉身,也多被关进了牛棚。
灵魂在单语单文的笼中,肉身,绝无可能在人类文明的路上。
其实,和鲁迅一样,胡适直觉到,单语单文的大脑维度里,启蒙本身长期是死亡交叉。但他俩都未找到解决路径。
神经网络:春天也让路
多语多文维度的1948年。
人类文明的AI启蒙之年。诺伯特·维纳提出了“控制论”的概念,香农发表《通信的数学理论》……
AI现代家谱的70年中,数学逻辑学派曾掌门 60年,这60年是AI的寒冬。
忽如一夜夏风来。AI 从寒冬一日跃入盛夏,连春天都让路了。如今,AI倾国倾城,从主流媒体到各国政府,从少年学霸到垂老资本,人人追捧。
谷歌-微软-IBM-亚马逊-特斯拉-脸书-华为-腾讯-百度-阿里等等,都将AI 当做企业生死战,中美俄三大国,更将其奉为国家战略命脉。
AI 一夜爆红的诀窍何在?
答案就四个字:神经网络。
生物神经学派的AI,也就是神经网络AI,一战彻底“击败”了数学逻辑学派。
整个科学界猛醒后,AI的掌门人也换成神经网络了。
柯洁也哭泣
神经网络AI,顾名思义,是模拟幼儿大脑的神经网络。过去十年来,它的智慧力如核爆,无情碾压着人类各行业的智慧冠军。
我们都知道围棋天才柯洁的哭泣。
这里存在一个悖论:科学家确知,如今的神经网络AI算法,还远远比不上幼儿大脑的神经算法。
两条科学路径
数学逻辑学派的思路,顾名思义,就是凭借人类顶级的数学家大脑的数学逻辑,直接解决智慧难题——如图像识别,语言识别——实现高级人工智能。
然而,全球顶级数学家屈指可数,每一代不足30个人,迭代期又须 30年。30+30,正好契合60年AI 之寒冬。
生物神经学派认为,用显性的数学逻辑直接解决各个领域的智慧问题,这种思路本身就窄化了数学逻辑;应该把数学逻辑运用于模拟大脑神经元网络的工作,用人工神经元网络去解决各种高级智慧难题。
两条路径都走了60多年。
数学逻辑学派迄今没有走通。
生物神经学派突然走通了。
亿万年爱情法则
上苍创造两性,是人类必须敬畏的自然法则。
1.0版的智慧男神,自己生不出一个2.0版的智慧男神。他必须找一个1.0版的智慧女神,双方结合,才能创造出2.0版的牛顿或达尔文或居里夫人。
数学逻辑要开花结果,必须与生物神经,恋爱+通婚。
同胞可以瞬间自嗨,这不就是易经原理:一阴一阳,而已。
外语教学的死亡之路
AI的数学逻辑是博士后导师级别。
外语教学领域的“主谓宾-定状补”的语法逻辑是中学生级别——所以可以向中学生传授讲解。
前者烧脑的层次比后者高九个维度,但它奋斗60年,没有成功。
后者更无可能成功。
是阳谋不是阴谋
顶级数学家的数学逻辑体系,让超级电脑学语言识别都失败,那么用语法知识的准逻辑体系让学童学外语,必然失败。
数学逻辑学派60年的努力,是AI 漫长冬天。
语法知识理论学派60年的教学,是一茬茬聋哑英语。
不伦不类地说,它似乎是欧美专家给中国同胞高价定制版的外语能力的特效“避孕套”。
是阴谋吗?不是。是阳谋。
轻松掌握三五门外语
比较初级的神经元网络AI,已经能横扫人类冠军,那么被神经元网络AI 全力以赴模拟的每个儿童天赋的大脑神经元网络,如果其潜能充分发挥,掌握三五门外语易如反掌。
外语学习的正确路径,是诱导儿童大脑语言神经元网络的充分生长,而不是语法知识的死命灌输。
生物就是算法

简史三部曲《人类简史》《未来简史》《今日简史》中,历史学家和未来学家尤瓦尔有句纲领性的名言:Organisms are algorithms,生物就是算法。
举例:GPS让我们出行极其便利,无论天涯还是咫尺,永不迷路。
永不迷路的我们,却永远迷茫——因为同胞不追问。小小的追问:人的大脑中有没有天赋的GPS 神经算法。有的,就是通常说的方位感,等等。但人类的GPS 神经算法不发达。

有GPS 神经算法特别发达的动物吗?
当然有,比方说,候鸟。
候鸟的GPS 算法是学知识学来的吗?
不是,它是物种进化的基因预设;飞着飞着,候鸟的GPS 算法神经就长出来了。
俗语说的(生物)本能,就是神经算法。
语言学之父的思想
“生物就是算法”的思想原创,部分来自当代西方科学思想界的领袖乔大大:乔姆斯基Noam Chomsky。
科学和人文有硬指标:文献引用 / 影响力指标,citation / impact factor。以这项硬指标衡量,乔大大是“活人第一,古今第八”,即活着的科学家他排第一,古往今来排第八[1]。
乔大大享有语言学革命之父与认知科学之父的双桂冠,他还发展了著名的图灵机理论——同胞所熟悉的计算机科学家图灵的智慧“苹果”都被乔姆斯基发展了。
一句话概括乔姆斯基理论:语言的核心是大脑神经的超级生物算法。
换言之,语言的核心根本不是文字+语法知识!
这是被哈佛剑桥的外语教学专家弄反了一件事。[2]
语言是生物神经算法
既然是当代语言学革命之父的理论,外语学习体系的建设就必须重视再重视。现实是:欧美外语教学流派的大腕,包括被同胞推崇的克拉申(S. Krashen)在内,似无人真正明白乔氏理论。
要领悟乔氏理论,AI 是很好的高峰视角。
AI 算法是评估人类智能的客观且精准的量尺。由表1 可知,语言识别的算法智能高于围棋冠军的智能。
对比表1和表2,可以再次确证以下结论和推论。
结论
语言本能是人类物种的生物算法 + 它是难于奥数的超级算法 + 它源于基因定向的大脑神经生长。
推论
外语学习要解决的关键问题是如何令被基因定向的大脑语言超级算法神经正常生长→超常生长。
碾压AlphaGo 的ChinaGo
单有算法还不够,还需要大数据。
以战胜柯洁的AlphaGo算法为例,它学习了高段棋手的海量棋谱,还通过三千万局自我对弈训练(一种特殊的大数据学习)。
假设一个中国天才少年设计了ChinaGo 算法,它只学习了100个普通棋手的棋谱,就能打败AlphaGo,那么无疑,ChinaGo是比AlphaGo高端千百倍的超级算法。
每个儿童大脑里是语言生物算法,恰恰就是这种超级算法。
小数据悖论
乔姆斯基说,儿童语言习得的数据经常是庸劣数据:没有几个孩子的父母是莎士比亚或曹雪芹。他将此称为语言习得的小数据悖论:Poverty of the Stimulus[3]
“100 > 100万”
科学家用100万个男女老少的话语+100万部名著-电影-剧本-讲座的大数据和优数据,来训练AI 语言识别算法。
天下每个父母亲,用平均不超过100个亲友的小数据会话交流,来“训练”孩子的语言能力。每个普通儿童都由此掌握了足以媲美顶级AI的语言识别能力。
小数据和平庸数据训练的儿童语言能力,超越了顶级AI算法的大数据和优数据。
这再次凸显:语言的核心是生物超级算法,而不是语言知识的语法。
语言超级神经的大数据增强
每个儿童都具备的小数据超级神经算法,丝毫不妨碍-反而特别有助于大数据增强。
如果儿童的语言学习具备了大数据+优数据的有效输入,那么语言神经算法的生长就会令每一个儿童都成为天才,超越大师。
每一个儿童!
掌握100门外语的算法潜能
语言生物神经算法的潜能有多大?
靠谱的记录是德国语言学家,也是汉学家,EmilKrebs,口语娴熟掌握的语种 > 67,书面娴熟掌握的语种 >100。他用 120种 不同语言写作的手稿,被美国华盛顿 D.C. 国会图书馆收藏。

举例:2018年的视频网红,“经常逃学”的柬埔寨10岁小贩,娴熟掌握10多门外语。
被荒废的语言超级神经
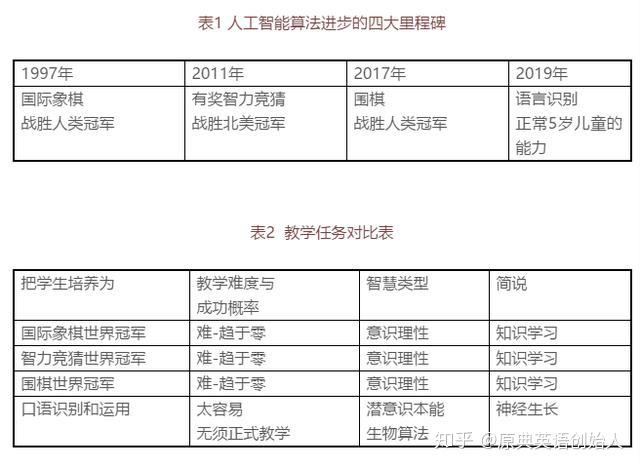
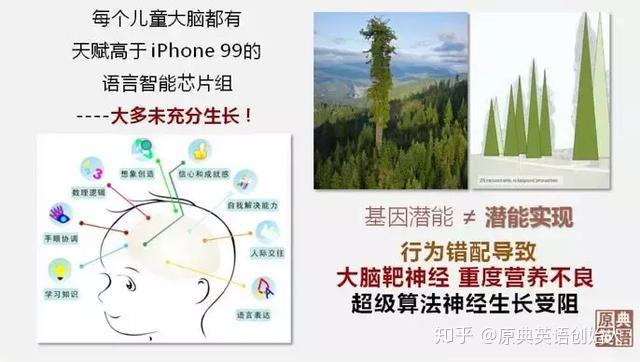
基因潜能 ≠ 潜能实现。
全世界最高的树是北美红杉,有记录的113米。也就是,它的基因潜能令它可生长到120米以上。但具体的一株北美红杉,如果后天条件,日照量,雨露,气温,土壤等等,不匹配,可能只有90米,甚至只有50米。
植物生长都有如此巨大的潜能实现差异,人类大脑的神经生长差异,更能千百倍地放大。
从这个角度看,99%的儿童大脑都被荒废了,尤其是语言超级神经的生长潜能。
什么是教育学
个个胎儿都是天才。
个个成人多是庸才。
为什么?
有一种诠释:教育学就是将天才变成蠢材的玄学和伪科学。
如今,教育专家努力再努力,播种和耕耘着家长们无所不在无时不在的焦虑,教育学从中丰收。
什么数据令神经生长
领悟了语言的核心是人类物种的生物神经算法,需要弄明白的就是,什么样的数据能令此生物神经算法充分生长。
AI 专家将此称作“数据训练”。
人类大脑天赋的语言超级神经算法生长的有效数据是优质语音流——或是甜美亲切且时而夸张有趣的嗓音,即慈母慈父的话语,或是有声故事大师的精彩咏诵对话——而根本不是文字阅读。
简言之,语言是声音的神经算法,而不是文字的知识文法。
主流外语教学体系两大谬误
第一是算法错误:意识理性的语法不是语言习得的有效算法。
第二是数据错误:文字(文本阅读)不是语言神经生长的有效数据。
阅读力也源于生物算法
最好的医学是预防医学:从不生病。
最好的教育是不用教育:天赋舒展。
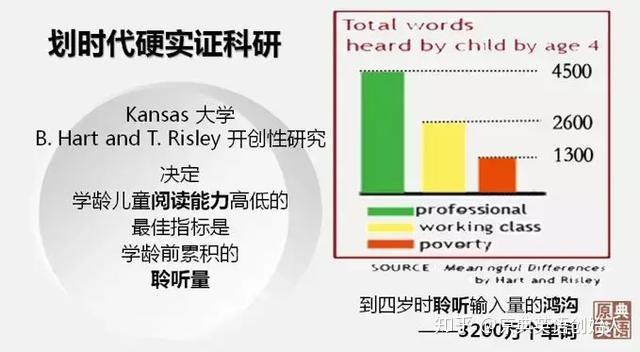
如何预测幼童未来的阅读能力?由堪萨斯大学 Betty Hart 和 Todd Risley在1990年代发起、被欧美学术界跟进的系列研究发现:最可靠的指标就是聆听量;学龄前累积的聆听量越大,学龄期阅读能力越强;学龄前累积的聆听量越少,入学后阅读能力越弱。到四岁时不同家庭幼童的语言聆听量差异就已经高达3200万个单词![4]聆听量不足被称为阅读教育的大灾难Catastrophe。
大脑科学界早在1980年代就发现,决定阅读能力高低的关键因素并非阅读教学自身,而恰恰是语音流加工,即聆听[5]。
为什么?
因为语音流输入是令大脑天赋语言超级神经生长的有效数据。
超级神经算法充分生长了,秒杀阅读。
超级神经算法生长不良,阅读是白辛苦。
可以秒胜冠军,就可以超越大师
用大数据和优数据训练的人工神经元网络AI,既秒杀用顶级数学家用数学逻辑规则直接设计的AI,又秒杀人类的有奖智力竞猜冠军和围棋冠军。
同理,用大数据和优数据“训练”的儿童大脑语言神经生长,既超越《新概念英语》的学生,又超越英语教材编写的冠军:语言教学专家。
什么是伪教育
无法实现“青出于蓝而胜于蓝”的教育,必定是伪教育。
单语单文不是大优数据
什么是儿童大脑语言神经生长的大数据和优数据?
单一语言的语音流,不可能是大数据和优数据。
常识中的常识:人类现存6000多种语言,每个婴幼儿都能不经正式教学毫不费力地学会任何一种和数种语言,包括根本没有文字的语种。
双语绝不仅仅是双科,它是用丰富化差异化的数据训练,训练大脑神经充分生长;没有系统级差异的数据,不可能是大数据,更不可能是优数据。
部分之和大于整体
什么是系统级差异的语音流数据?是多门外语而不是单门母语。
差异化数据训练——不同语种趣味故事的输入浸润——是人类天赋的超级算法神经生长的全营养。
部分之和大于整体,差异之和舒展天才。
AI人秒懂原典双语学习体系
用AI 人的术语总结:
“训练被人类物种基因预设的大脑语言神经元超级算法生长的优质数据是优质语音流——甜美亲切时而夸张或诙谐的嗓音——而根本不是阅读的文本和语法知识。哈佛剑桥的外语教学流派四十年没有多少长进,令人扼腕。”
原典法反复说过,外语教学体系,两句话足够了,其他都属多余:
聆听最大化,聆听最优化。

双语是大脑语言神经生长最低标准的数据“训练”。
嗜听和音痴
问世间声为何物,直教人生死相依。

体现在日常生活的行为,就是两个词,耐心培养儿童听趣味外语故事的好习惯而达到
嗜听+音痴
嗜听+音痴就恰恰对应大脑语言超级神经的优化生长和高速生长→就可以超越古往今来的语文大师→ 也不难超越剑桥哈佛。
儿童天赋的大脑超级神经生长了升级了,超越历史上的语文大师,毫无悬念。
他们成长的时代,既无大脑科学,也无有声书。
哈佛剑桥,没有任何一个主流外语教学理论以大脑科学为基础;他们甚至连漫山遍野的有声书都不置一词。
从来就没有什么救世主,更不靠剑桥哈佛。
本文已太啰嗦了。
操作要领另文谈。
可以关注微信公众号“原典之光”搜索徐老师文史哲系列文章:
一、我们终将沦为脑残
二、男神版林黛玉-教我如何不想他
三、伤害大脑生长的“五毒”
四、人脑如何完美碾压AI
五、哈佛教授人人抢读的一本书
六、巴黎圣母的烈焰与西方文明的末路
七、从AI革命洞察外语教学的世纪错误
添加微信18784635633 进群学习原典英语
")
发表评论