数据,如同蕴藏着无尽的信息和价值的洞穴,探索性数据分析(EDA:exploratory data analysis)是打开洞穴的关键之门。它不仅是一项准备工作,更是决定数据分析/数据科学/机器学习项目成败的关键一环。通过本文,我们将深入理解EDA的重要性,并探讨如何借助EDA解锁数据之门,揭示数据的真相和潜在价值。跟随我们一同踏上这段探索之旅,发现数据中的奥秘。

什么是探索性数据分析(EDA)?
探索性数据分析(EDA:exploratory data analysis)是数据应用、数据展现、数据建模之前,对数据进行深入了解和探索的过程。它涉及使用可视化、总结和发现数据中的模式、异常和离群值。
在这个过程中,我们通过各种可视化手段,如条形图、箱线图、密度图等,对数据进行审视。这样的深入探索有助于我们获得关于数据的直观感觉,为后续的机器学习选择和结果改进提供指导。
EDA的本质是了解数据的内在特征,而不是简单地对数据进行表面式的描述。通过EDA,我们能够发现数据集的结构、特征分布、潜在关系,从而为后续的分析和建模奠定坚实的基础。这种深入了解数据的过程,有时被比喻为打开数据之门的关键,揭示出数据背后的真相和价值。通过EDA,我们不再只是处理冰山一角,而是全面了解数据的本质,为解锁数据之门提供了重要的线索。
为什么需要探索性数据分析(EDA)?
正如医生在开具药物或治疗之前通过一系列望、闻、问、切等系列诊断动作深度了解患者状况一样,数据科学家在进行数据科学、机器学习或BI可视化项目之前执行探索性数据分析(EDA)。
在医学中,医生通过观察症状、了解病史、进行实验室检查等手段来深度了解患者的身体状况。同样,EDA为数据科学家提供了一系列工具和技术,以深入了解数据集的内在特征和结构。
通过数据可视化、统计摘要、图表等方法,数据科学家能够识别数据的分布、趋势、异常值和相关性,就像医生通过诊断手段深入了解患者的身体状况一样。
这种深入的数据诊断过程帮助数据科学家理解数据的“健康”状况,发现潜在问题,为后续的分析和建模提供基础。因此,探索性数据分析就像医学中的临床诊断一样,为数据科学项目的顺利进行提供了必要的前期了解。
探索性数据分析(EDA)在数据科学和机器学习中是至关重要的,它具有多方面的作用,为数据科学家和分析师提供了深入了解数据的途径。
识别和处理数据质量问题:EDA有助于发现和处理数据中的问题,如缺失值、错误标签、重复项等。解决这些问题有助于提高模型的性能和准确性。理解数据的分布和特征:通过可视化和统计方法,EDA帮助我们了解数据的分布、变化和特征,为后续建模选择提供基础。选择合适的机器学习技术和方法:对数据进行EDA可以帮助我们选择适当的机器学习技术,包括特征缩放、正则化、转换等,从而提高模型性能。选择最相关的特征:EDA揭示了变量之间的关系,有助于选择对模型最具信息价值的特征,避免多重共线性或冗余。生成新的特征:通过对数据的深入探索,EDA可以启发新的特征工程思路,创造或组合新的特征,提高模型的表现。检测和处理离群值和异常:EDA帮助我们发现可能影响模型性能的离群值和异常值,并决定如何处理它们。验证关于数据的假设:EDA提供了测试我们关于数据的假设和先验知识的方法,帮助调整建模过程。清晰而有力地传达发现和洞见:利用可视化技术,EDA有助于将复杂的数据信息以清晰而有力的方式传达给他人,促进团队合作和决策制定。
总的来说,EDA是一个深入理解数据、准备数据以进行进一步分析和建模的关键步骤,为数据科学家提供了洞察数据本质的手段。
常见的探索性数据分析EDA技术
在进行探索性数据分析(EDA)时,我们通常使用Seaborn和Matplotlib库,以IRIS数据集为例。以下是一些常用的绘图技术:
1.Bar Plot / Count Plot(直方图)
用于:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data=pd.read_csv('iris.csv')
sns.countplot(x='Species', data=data)
plt.title('Count of Species')
plt.show()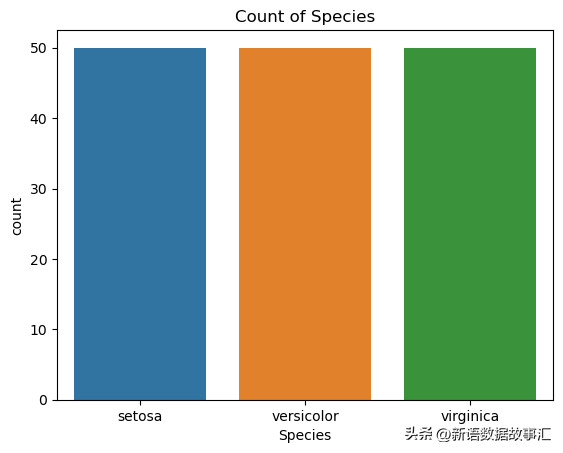
2.Box Plot(盒须图/箱线图)
用于:
sns.boxplot(x='Species', y='Petal.Length', data=data)
plt.title('Box Plot of Petal.Length by Species')
plt.show()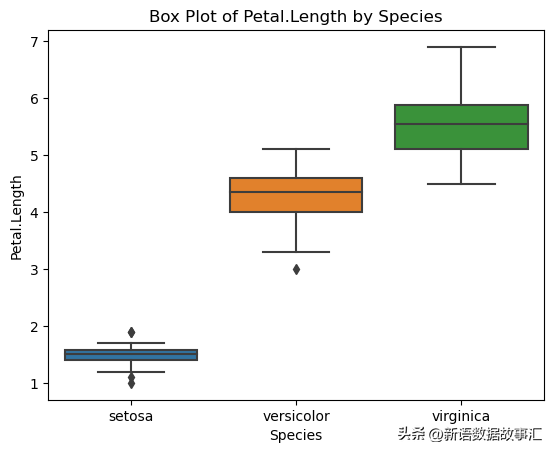
3.Density Plot(密度图)
用于:
sns.kdeplot(data['Petal.Length'], shade=True)
plt.title('Density Plot of Petal.Length')
plt.show()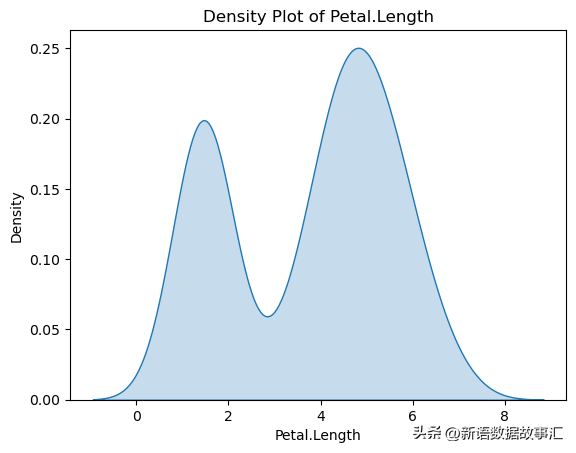
4. Scatter Plot(散点图)
用于:
sns.scatterplot(x='Sepal.Width', y='Sepal.Length', data=data)
plt.title('Scatter Plot of TSepal.Width vs. Sepal.Length')
plt.show()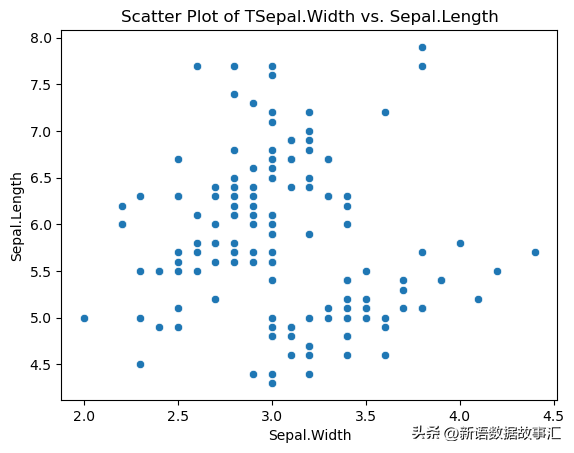
5.Heatmap(热力图)
用于:
correlation_matrix = data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap')
plt.show()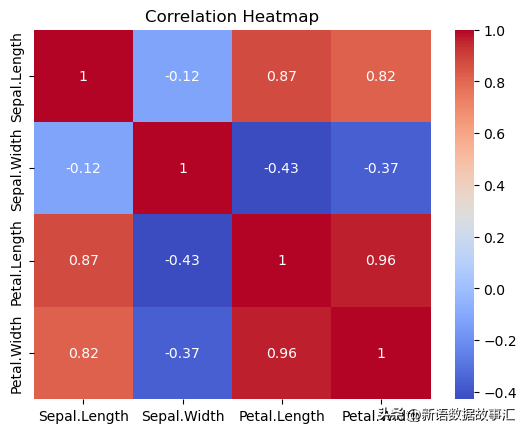
6.Subplot
用于:并排比较同一图中的多个图。
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
sns.scatterplot(x='Sepal.Length', y='Species', data=data)
plt.title('Scatter Plot of Sepal.Length vs Species')
plt.subplot(2, 2, 2)
sns.boxplot(x='Species', y='Sepal.Length', data=data)
plt.title('Box Plot of Sepal.Length by Species')
plt.subplot(2, 2, 3)
sns.barplot(x='Species', y='Sepal.Length', data=data)
plt.title('Bar Plot of Sepal.Length by Species')
plt.subplot(2, 2, 4)
sns.histplot(data['Sepal.Length'], kde=True)
plt.title('Histogram of Sepal.Length')
plt.tight_layout()
plt.show()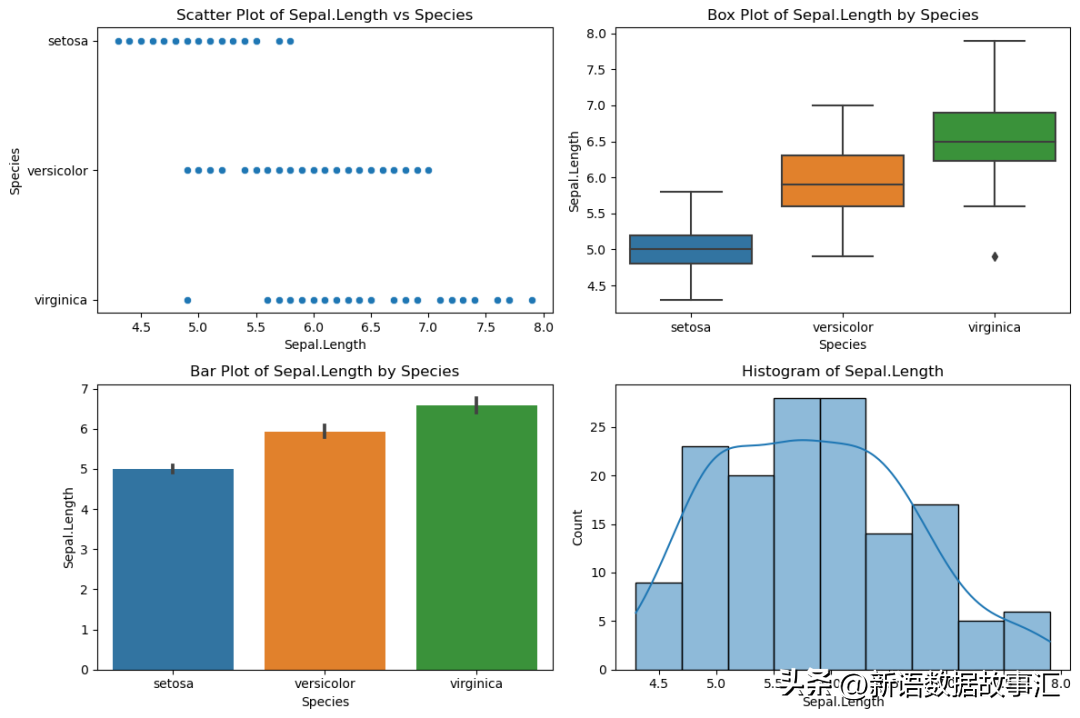
7.Pairplot(配对图)
用于:通过成对可视化来探索多个变量之间的相关性和趋势。
sns.pairplot(data, hue='Species')
plt.suptitle('Pairplot of Numerical Variables by Species', y=1.02)
plt.show()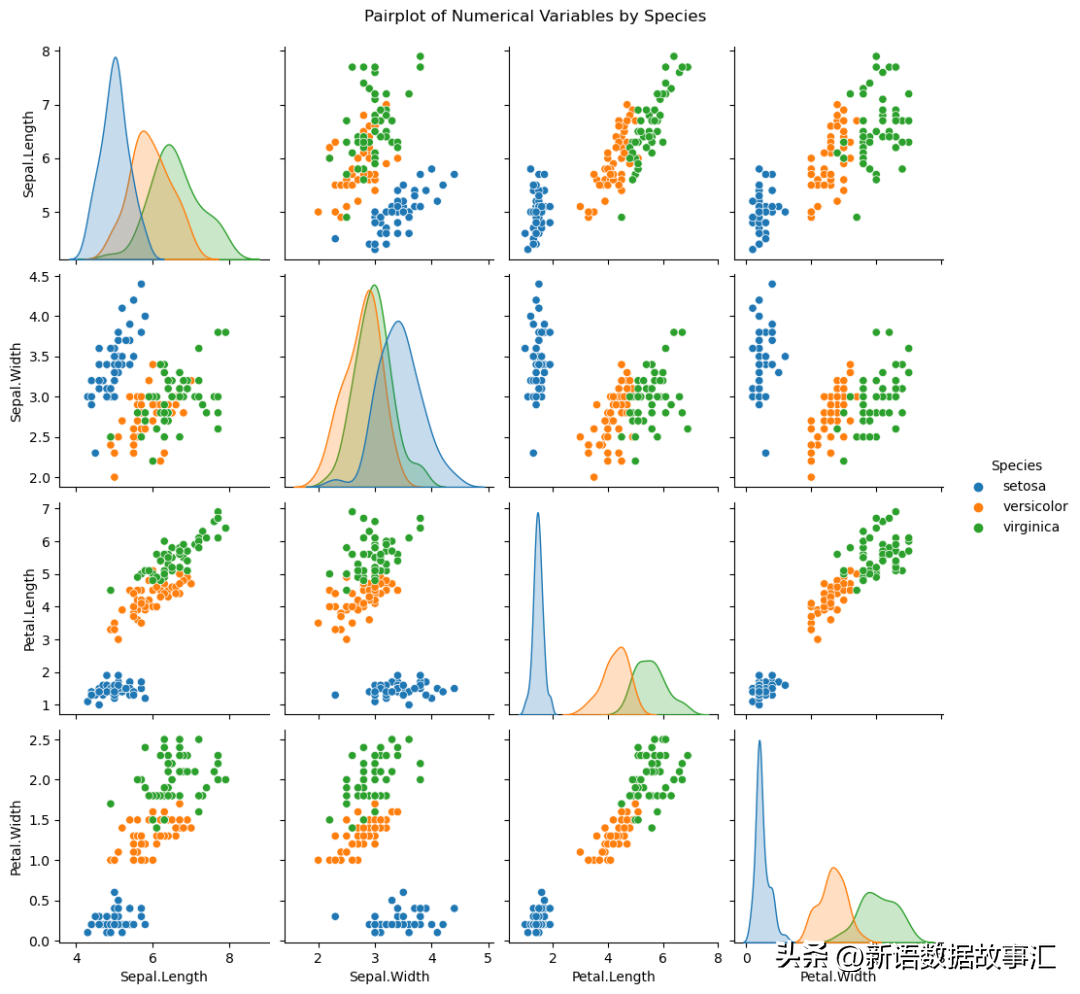
8.Violin Plot(小提琴图)
结合了箱线图和核密度图的特征。
用于:可视化数值变量在不同类别中的分布。
sns.violinplot(x='Species', y='Sepal.Length', data=data)
plt.title('Violin Plot of Sepal.Length by Species')
plt.show()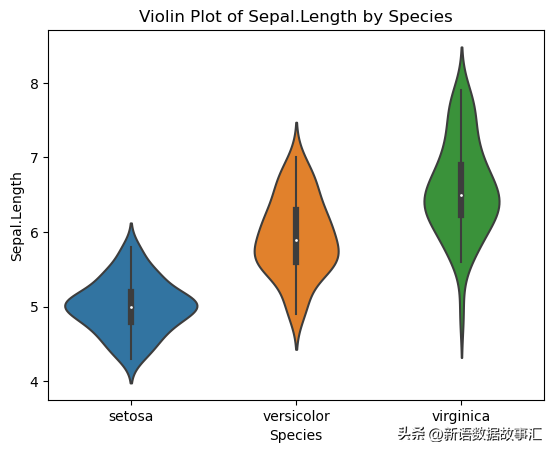
探索性数据分析(EDA)如同解锁数据之门的钥匙,揭示数据蕴藏的无尽信息。本文深入阐述EDA的重要性,将其比喻为数据科学世界的临床诊断,为项目成功打下基础。EDA通过可视化手段,如条形图、箱线图、密度图,使数据科学家深刻了解数据的内在特征,识别问题并提供指导。对于机器学习、数据分析、可视化等项目,EDA是理解数据、选择特征、优化模型的不可或缺步骤,为数据科学家提供了解数据本质的关键工具。

")




发表评论