探索性数据分析(EDA)是一种分析机器学习数据集以总结其主要特征的方法。它用于理解数据,获取有关它的一些上下文,理解变量和它们之间的关系,并制定在构建机器学习预测模型时可能有用的假设。
所有数据分析必须以一些关键问题或目标为指导。在开始任何数据分析任务之前,您应该有一个明确的目标。当您的目标允许您了解您的数据和问题时,您将能够从分析中获得有意义的结果!
在本教程中,我们将学习如何使用数据可视化来执行EDA。具体来说,我们将重点介绍seaborn,这是一个构建在matplotlib之上的Python库,支持NumPy和panda。
seaborn使我们能够制作出具有吸引力和信息丰富的统计图形。尽管matplotlib使得可视化任何东西都成为可能,但是要使图形具有视觉吸引力通常是困难和乏味的。seaborn通常用于使默认的matplotlib图看起来更好,并引入了一些额外的图类型。
我们将介绍如何进行视觉分析:
通过有效地可视化机器学习数据集的变量及其关系,数据分析师或数据科学家能够快速了解趋势,异常值和模式。然后,可以使用这种理解来决策并创建机器学习预测模型。
数据准备
数据准备是任何数据分析的第一步,以确保以可分析的形式清理和转换数据。
我们将在Ames Housing数据集上执行EDA() 。这个数据集在那些开始学习数据科学和机器学习的人群中很受欢迎,因为它包含了爱荷华州艾姆斯出售的不同房屋几乎所有特征的数据。然后可以使用该数据来尝试预测销售价格。
请先进行数据集清理然后进行分析。我们要做的就是过滤一些变量来简化我们的任务。首先,让我们将数据读取为panda DataFrame:这个数据集在那些开始学习数据科学和机器学习的人群中很受欢迎,因为它包含了爱荷华州艾姆斯出售的不同房屋几乎所有特征的数据。然后可以使用该数据来尝试预测销售价格。
此数据集已经过清理并可以进行分析。我们要做的就是过滤一些变量来简化我们的任务。首先,让我们将数据读取为panda DataFrame:
import pandas as pd
import matplotlib as plt
housing = pd.read_csv('house.csv')
housing.info()

此图像仅显示数据集中前五列的信息
如果您在Jupyter notebook中运行此Python代码,则可以看到有1,460个观察值和81列。每列代表DataFrame中的变量。我们可以从每列的数据类型中看到它是什么类型的变量。
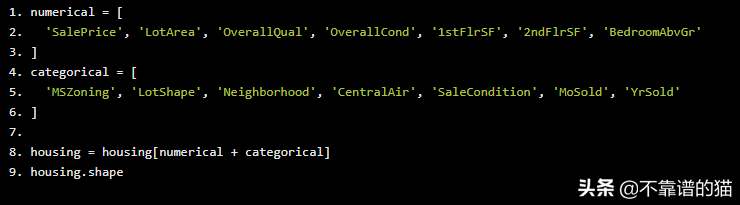
我们将只处理其中的一些变量——让我们将它们的名称过滤并存储在两个名为numerical和categorical的列表中,然后重新定义我们的housing DataFrame,使其只包含这些变量:
numerical = [ 'SalePrice', 'LotArea', 'OverallQual', 'OverallCond', '1stFlrSF', '2ndFlrSF', 'BedroomAbvGr' ] categorical = [ 'MSZoning', 'LotShape', 'Neighborhood', 'CentralAir', 'SaleCondition', 'MoSold', 'YrSold' ] housing = housing[numerical + categorical] housing.shape
Out: (1460, 14)
从housing.shape中,我们可以看到DataFrame现在只有14列。让我们来分析一下!
分析数值变量
我们的EDA目标是了解此数据集中的变量如何与房屋的销售价格相关。
在我们做到这一点之前,我们需要先了解变量。让我们从数值变量开始,特别是我们的目标变量SalePrice。
数值变量就是那些数值为数字的变量。当我们有数值变量时,我们要做的第一件事是了解变量可以取什么值,以及分布和离散度。这可以通过直方图来实现:
import seaborn as sns
sns.set(style='whitegrid', palette="deep", font_scale=1.1, rc={"figure.figsize": [8, 5]})
sns.distplot(
housing['SalePrice'], norm_hist=False, kde=False, bins=20, hist_kws={"alpha": 1}
).set(xlabel='Sale Price', ylabel='Count');
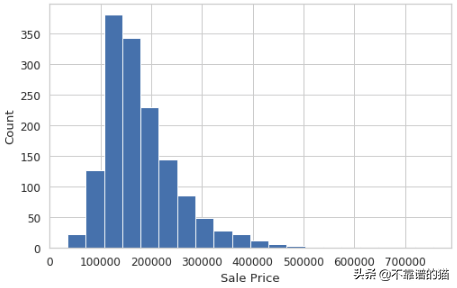
SalePrice变量的分布
请注意,seaborn库被导入为sns。
只需一种方法sns.set(),我们就可以设计图形样式,更改颜色,增加字体大小以提高可读性,并更改图形大小。
我们使用distplot来绘制seaborn中的直方图。默认情况下,这会绘制带有核密度估计(KDE)的直方图。您可以尝试更改参数kde=True,看看它是什么样子的。
看一下直方图,我们可以看到,很少有房子的价格低于10万,大多数房子的价格在10万到20万之间,很少有房子的价格高于40万。
如果我们想为所有数值变量创建直方图,pandas提供最简单的解决方案:
housing[numerical].hist(bins=15, figsize=(15, 6), layout=(2, 4));
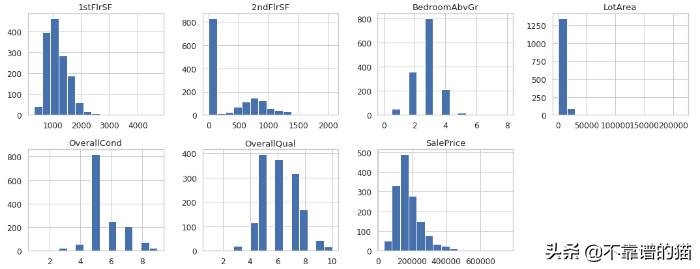
每个数值变量的分布
从这个可视化中,我们获得了大量信息。我们可以看到1stFlrSF(一楼面积)严重偏态,大多数房屋没有二楼,并且有3个BedroomAbvGr(地上卧室)。大多数房屋的售价分别OverallCond of 5和OverallQual of 5或更高。LotArea可视化更难理解——但是我们可以看出,在建模之前可能需要删除一个或多个异常值。
请注意,该图保留了我们之前使用seaborn设置的样式。
分析分类变量
分类变量是指其值被标注类别的变量。分类变量的值、分布和离散度最好通过条形图来理解。让我们分析一下SaleCondition变量。seaborn为我们提供了一种非常简单的方法来显示每个类的观测计数:countplot。
sns.countplot(housing['SaleCondition']);
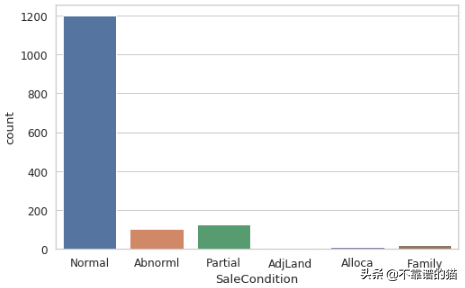
该图中的条形表示每种销售条件下的房屋数量
从可视化的角度,我们可以很容易地看到,大多数房屋是在Normal情况下出售的,而在AjdLand(毗连土地购买)、Alloca(分配:两个有独立契约的相互关联的房产)和Family 家庭成员之间的销售)条件下出售的很少。
为了可视化数据集中的所有分类变量,就像我们对数值变量所做的那样,我们可以循环遍历pandas序列来创建子图。
使用plt.subplots,我们可以创建一个包含2行和4列网格的图形。然后我们遍历每个分类变量,使用seaborn创建countplot:
fig, ax = plt.subplots(2, 4, figsize=(20, 10)) for variable, subplot in zip(categorical, ax.flatten()): sns.countplot(housing[variable], ax=subplot) for label in subplot.get_xticklabels(): label.set_rotation(90)
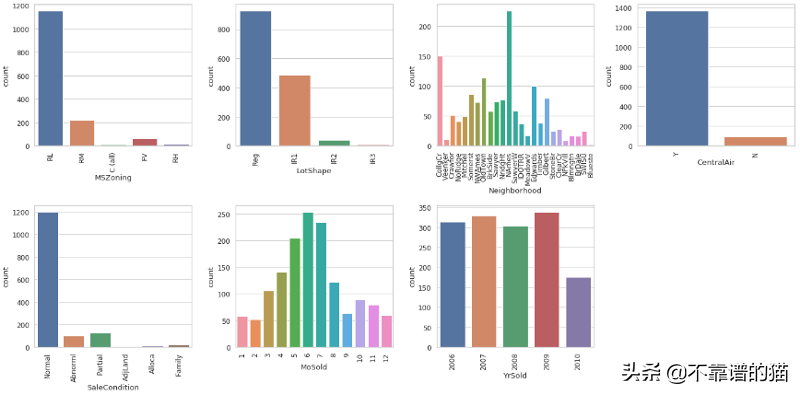
每个分类变量的Countplots
第二个for循环只是获取每个x-tick标签并将其旋转90度,以使文本更适合图标(如果您想知道不旋转文本的外观,可以删除这两行)。
与我们的数值变量直方图一样,我们可以从这个视觉中收集大量信息 - 大多数房屋都有RL(住宅低密度)分区分类,有Regular地段形状,并且有CentralAir。我们还可以看到,在夏季,房屋销售频繁,大多数房屋在NAmes(北艾姆斯)社区出售,2010年销售有所下降。
但是,如果我们YrSold进一步检查变量,我们可以看到这种“下降”实际上是由于只收集了截至7月的数据。
housing[housing['YrSold'] == 2010].groupby('MoSold')['YrSold'].count()

正如您所看到的,彻底探索变量及其价值非常重要 - 如果我们在假设2010年销售额下降的情况下建立了预测销售价格的模型,那么这种模型可能会非常不准确。
既然我们已经探索了数值和分类变量,那么让我们来看看这些变量之间的关系 - 更重要的是,这些变量如何影响我们的目标变量SalePrice!
分析数值变量之间的关系
绘制变量之间的关系使我们能够轻松地了解模式和相关性。
该散点图通常用于可视化两个数值型变量之间的关系。seaborn创建散点图的方法非常简单:
sns.scatterplot(x=housing['1stFlrSF'], y=housing['SalePrice']);
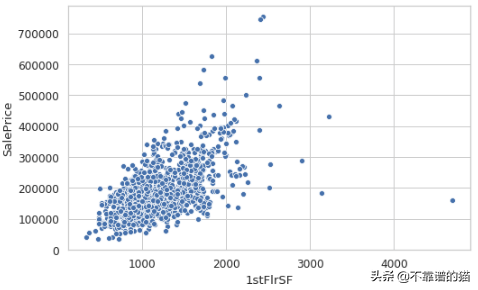
1stFlrSF与SalePrice之间的关系
从散点图中,我们可以看到房子的1stFlrSF和房子的SalePrice之间存在正相关关系。换句话说,房子的一楼越大,可能的售价就越高。
您还可以看到,axis标签在默认情况下是为我们添加的,并且标记是自动列出的,以使它们更加清晰——这与matplotlib相反,在matplotlib中这些不是默认的。
seaborn还为我们提供了一个很好的函数jointplot,它将为您提供一个散点图,显示两个变量之间的关系以及边距中每个变量的直方图 - 也称为边际图。
sns.jointplot(x=housing['1stFlrSF'], y=housing['SalePrice']);
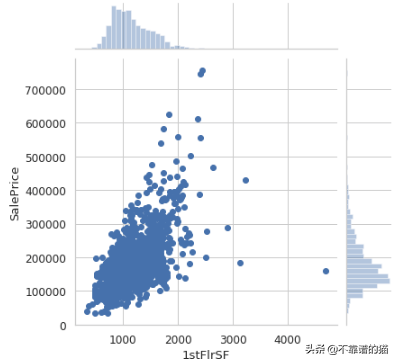
显示1stFlrSF与SalePrice及其各自分布关系的联合图
您不仅可以看到这两个变量之间的关系,而且还可以看到它们是如何单独分布的。
分析数值和类别变量之间的关系
盒须图通常用于可视化数值变量和分类变量之间的关系,复杂条件图用于可视化条件关系。
让我们先用seaborn的boxplot方法创建盒须图:
fig, ax = plt.subplots(3, 3, figsize=(15, 10)) for var, subplot in zip(categorical, ax.flatten()): sns.boxplot(x=var, y='SalePrice', data=housing, ax=subplot)
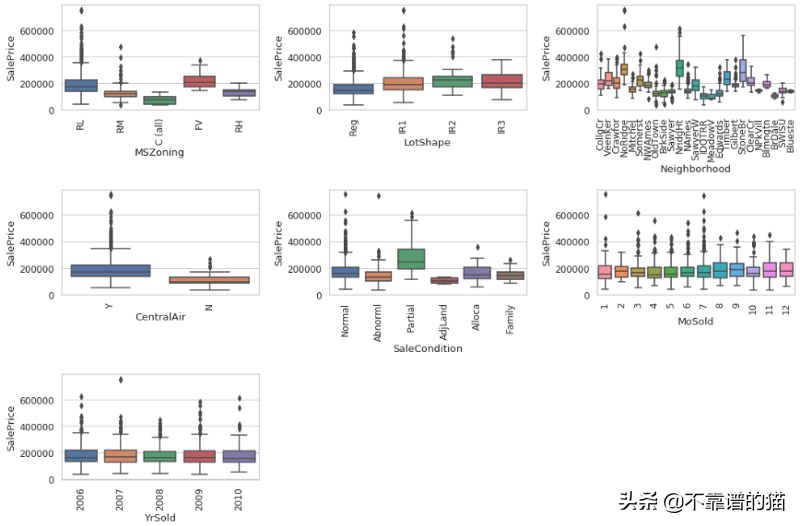
每个分类变量及其与SalePrice的关系的盒须图
在这里,我们遍历了每个子图,以生成所有类别变量和SalePrice之间的可视化。
我们可以看到具有FV(Floating Village Residential)zoning 分类的房屋的平均SalePrice高于其他zoning 分类,有CentralAir的房屋和部分(上次评估时未完成的房屋)销售合同的房屋的平均售价也高于其他zoning分类。我们还可以看到,不同lotshape的房子之间,MoSold和yrsell之间的平均售价差异很小。
让我们仔细看看Neighborhood变量。我们看到,对于不同的neighborhood,肯定有不同的分布,但是可视化有点难以理解。让我们使用额外的参数顺序,按照最便宜的neighborhood到最昂贵的(按照中间价格)对box plot进行排序。
sorted_nb = housing.groupby(['Neighborhood'])['SalePrice'].median().sort_values() sns.boxplot(x=housing['Neighborhood'], y=housing['SalePrice'], order=list(sorted_nb.index))
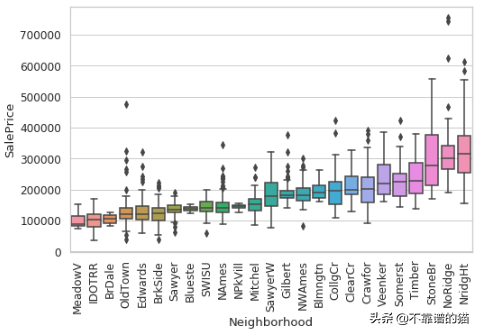
分类盒须图显示Neighborhood与SalePrice的关系
在上面的Python代码片段中,我们按照median 价格对neighborhood进行了排序,并将其存储在sorted_nb中。然后,我们将这个neighborhood名称列表传递到order参数中,以创建一个排序的箱形图。
这个数字给了我们很多信息。我们可以看到,在最便宜的街区,房屋的售价median价格约为10万美元,在最昂贵的社区,房屋售价约为30万美元。我们还可以看到,对于一些neighborhoods而言,价格之间的差异非常小,这意味着所有价格都相互接近。然而,在最昂贵的街区,我们看到一个大盒子——价格分布有很大的分散性。
最后,seaborn还允许我们创建显示条件关系的图。例如,如果我们正在调整Neighborhood,使用该FacetGrid函数我们可以看到变量OverallQual和SalePrice变量之间的散点图:
cond_plot = sns.FacetGrid(data=housing, col='Neighborhood', hue='CentralAir', col_wrap=4) cond_plot.map(sns.scatterplot, 'OverallQual', 'SalePrice');
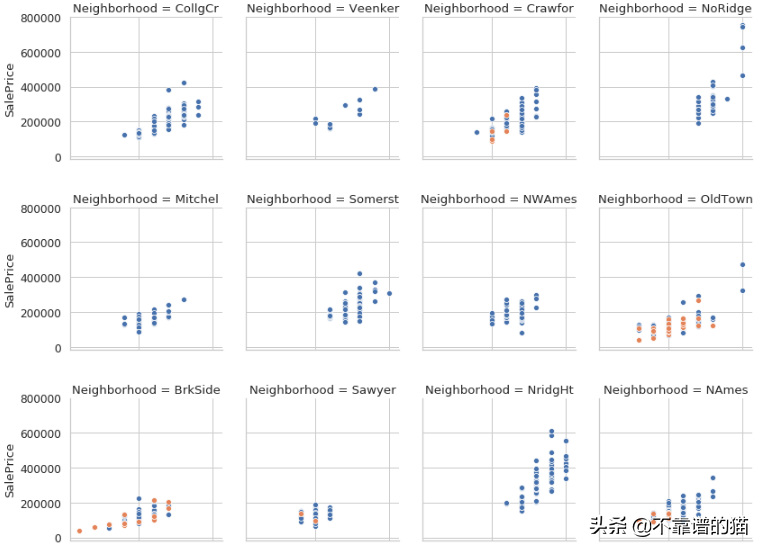
此图像仅显示前12个图。实际上有25个图 - 每个neighborhood一个
对于每个单独的neighborhood ,我们可以看到OverallQual和SalePrice之间的关系。
我们还在hue参数(可选)中添加了另一个categorical变量CentralAir——橙色的点对应于没有CentralAir的房屋。如你所见,这些房子的售价往往较低。
FacetGrid方法使生成复杂的可视化和获取有价值的信息变得非常容易。生成这些可视化来快速了解变量关系是一个很好的实践。
最后
在我们的探索过程中,我们发现了个别变量中的异常值和趋势,以及变量之间的关系。这些知识可以用来建立一个模型来预测艾姆斯的房价。例如,由于我们发现SalePrice与CentralAir、1stFlrSf、SaleCondition和Neighborhood变量之间存在相关性,我们可以从使用这些变量的简单机器学习模型开始。
本课程探索了NumPy的向量化操作,使用panda的EDA,使用matplotlib的数据可视化,使用seaborn的附加EDA和可视化技术,使用SciPy的统计计算,以及使用scikit-learn的机器学习。






发表评论