目录
一、数据导入与总览
工具:Jupyter notebook+pandas(Python包)+pandas_profiling(Python包)
import pandas as pd
import pandas_profiling
data=pd.read_csv()
data.profile_report(title='')

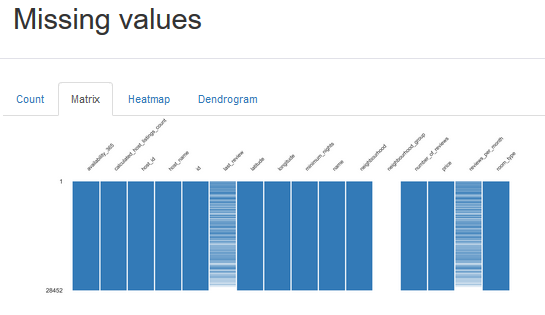
分析:预览数据总体情况,缺失值、特征异常情况(异常值、分布均衡性等)。
异常值特点:1)高绝对值的权重。2)与实际值差距过大的预测值。3)比平均值多大约 3 个标准差的输入数据的值。
二、数据清洗与整理
缺失值:参考 zhuanlan.zhihu.com/p/40775756
(1)删除该特征。如果特征缺失达到90%以上,说明丧失大部分有效信息,此特征沦为无效特征,可以考虑删除;另外也适用于样本数据量十分大且缺失值不多的情况。
df.dropna(how='any')
(2)填充
其他:数据分列、格式清洗(replace()\re.sub()\)
三、特征分析与可视化
(一)变量分析
(1)单变量分析
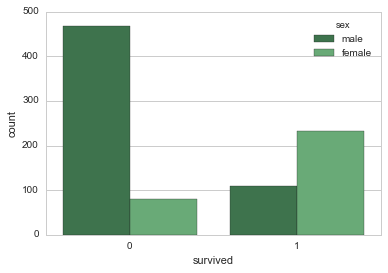
分类变量(categorical data)
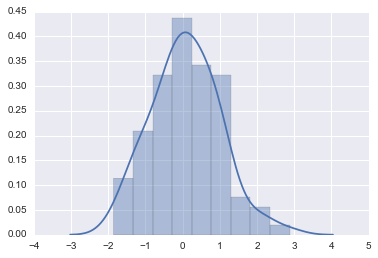
连续型变量
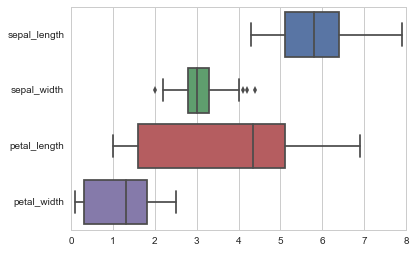
(2)多变量分析
分类变量+其他(分类、连续)
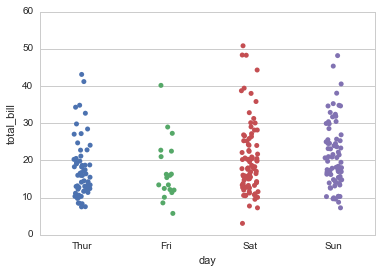
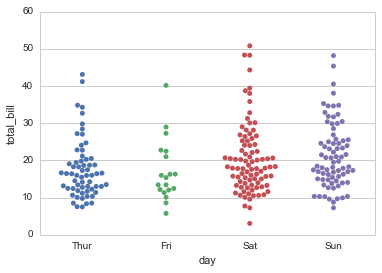
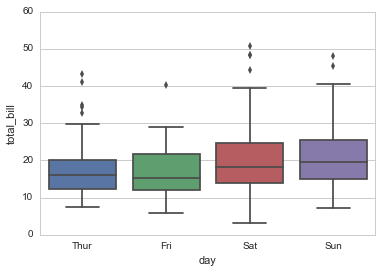
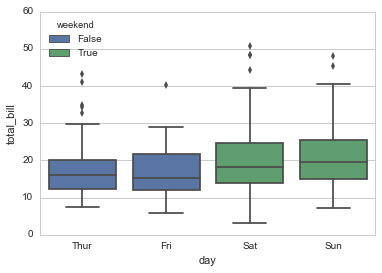
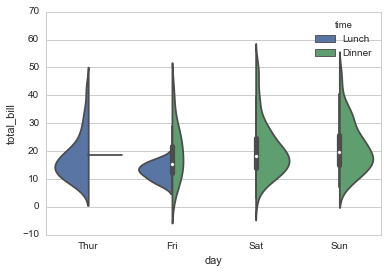
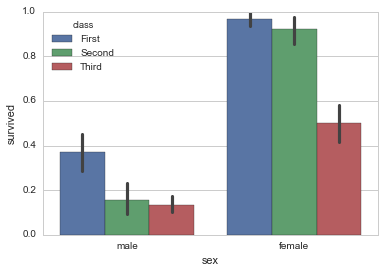
连续变量+其他
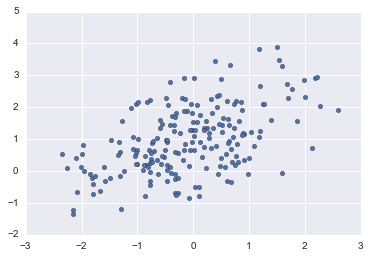
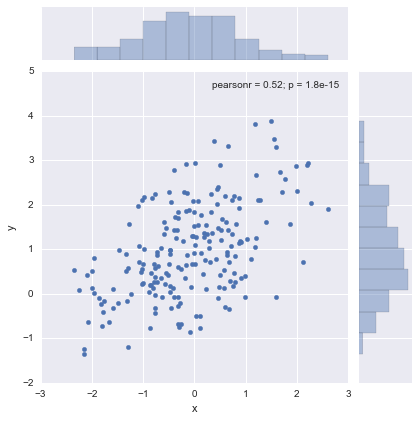
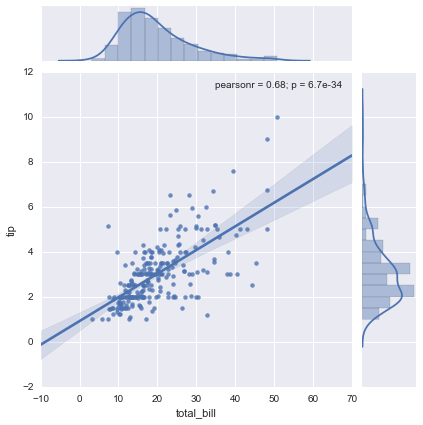
sns.jointplot(x="total_bill", y="tip", data=tips, kind="reg");
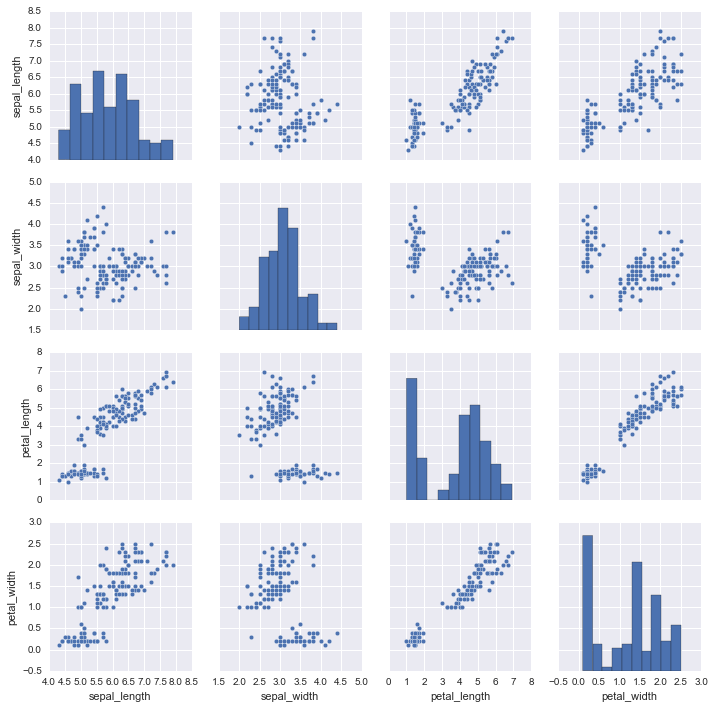
多变量
sns.pairplot(tips, x_vars=["total_bill", "size"], y_vars=["tip"],hue="smoker", size=5, aspect=.8, kind="reg");
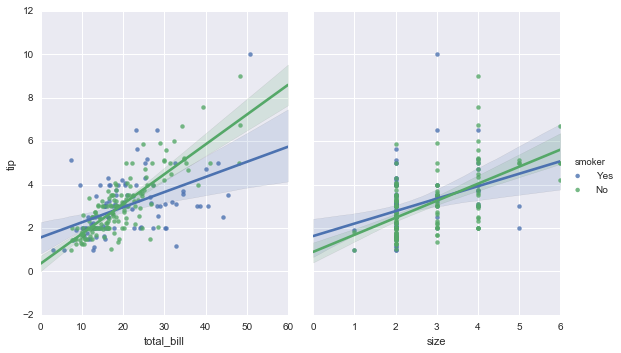
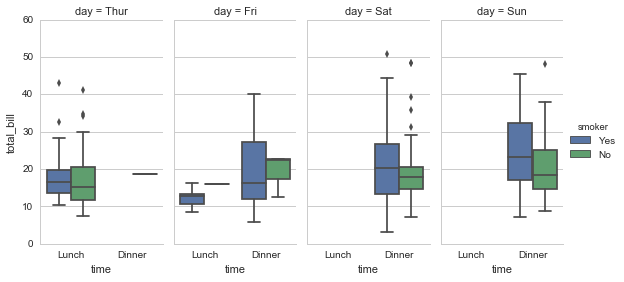
小结:
(二)变量关系可视化(Visualizing relationships between variables)
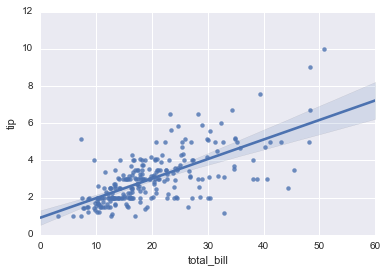
(1)双变量的线性回归函数
regplot:sns.regplot(x="total_bill", y="tip", data=tips);
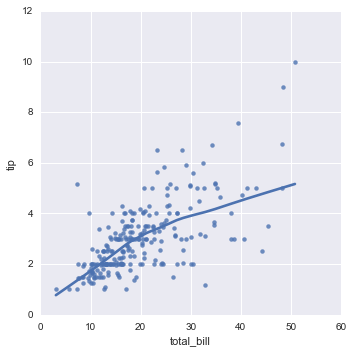
(2)局部线性,全局非线性 (Lmplot)
lmplot:sns.lmplot(x="total_bill", y="tip", data=tips,lowess=True);
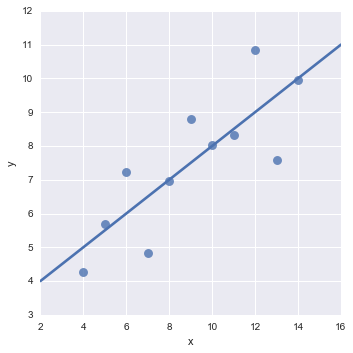
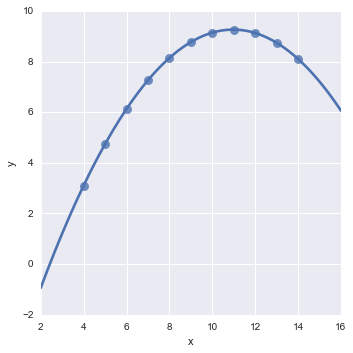
(3)一些简单高阶(二阶三阶)的关系探索 (Lmplot)
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),ci=None, scatter_kws={"s": 80});
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),order=2, ci=None, scatter_kws={"s": 80});
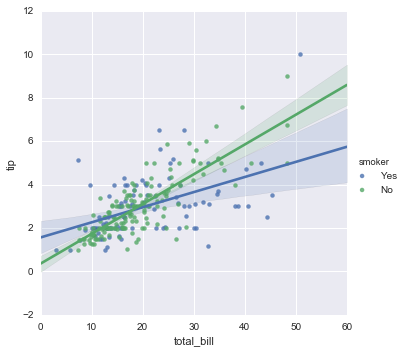
(4)聚类之后的线性回归(Lmplot,更高维度审视线性回归)
该部分和之前一样就是加入了hue,col,row(主要针对categorical数据)等操作,使得我们可以站在更高维度的空间来审视我们的数据,我将这个看做是类似于聚类之后的回归.之前没怎么使用过这种方法,最近看文档学习的,感觉非常有用. 如果发现某个子图中某两个变量存在完全的线性相关性,那么肯定是非常棒的!
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips);
框架记录")
发表评论