“这是数据分析中我最喜欢的部分:获取枯燥的平面数据,并通过可视化将其变为现实。”
— 约翰·图基

探索性数据分析 (Exploratory Data Analysis - EDA) 会应用一组用于探索、描述和总结数据性质的统计技术,以确保分析的客观性和互操作性。EDA可以帮我们识别可能犯的错误,找到异常值的存在,检查变量之间的关系(相关性)及可能的数据冗余,并通过图形和重点摘要对数据进行描述性分析。
在本文中,我们将通过对 QS 世界大学排名(2017-22)数据集的分析,向你介绍 EDA 的过程。
(复制此链接到浏览器打开可下载数据:
kaggle.com/datasets/padhmam/qs-world-university-rankings-2017-2022)
EDA 的工具

有很多工具可以被用于开发 EDA,其中比较流行的是R和Python 。R 是 R Foundation for Statistical Computing 支持的开源编程语言。它具有易于使用的界面和富有表现力的语法,可以让统计学家、数据分析师、研究人员等人检索、清理、分析、可视化和呈现数据。另一方面, Python在更大程度上促进了快速的应用程序开发。
把Python和 EDA 结合,它可以用于识别数据集中的缺失值,以确保我们很好地处理机器学习中的缺失值。当然,你也可以选择MS Excel和Tableau等其他软件。
EDA 的步骤

1.数据收集:

数据的收集是探索性数据分析的一个重要方面。在这个过程中,我们要定位数据,并将其放入我们系统。
2.数据清洗:
数据清理,就死从数据集中删除不需要的变量、值、以及任何异常的行为。这些异常可能会严重扭曲数据,对结果产生负面影响。
3.数据预处理:
这是一个处理计算机不能理解的真实数据(例如文本、图像、和视频)的过程,因此在此步骤中,我们将使用整洁和结构化的信息制作易于分析的数据,让它们能够被机器理解。
4.数据可视化:
为了更好地理解数据,我们必须让数据变得简单易懂,所以当我们以图表等可视数据的形式表示它时,它将帮助分析师和其他人快速地理解数据。
不同类型的 EDA
1. 单变量分析(Univariate Analysis):
单变量分析是分析数据的最简单形式。正如名称“uni”所暗示的那样,单变量分析是对一个变量的分析。它有助于数据分析师了解单个变量的值是如何分布的。它分别探索数据集中的每个变量。它会分析每个变量的特征,但不会研究和其他变量直接的影响或关系。
2. 双变量分析(Bivariate Analysis):
双变量分析会分析两个变量,并确定它们之间的关系。其中一个变量是因变量,另一个是自变量。它还可以帮助检验简单的关联假设。
3. 多变量分析(Multivariate Analysis):
当必须同时分析两个以上的变量时,我们就需要进行多变量分析。在处理现实世界的数据时,我们所做的很多预测都是基于多变量数据,因为在给定时间点或一段时间内可能有多个因素影响变量。多元分析的常见类型包括聚类分析、因子分析和多元回归分析。
用R 做 EDA分析
1. 数据收集:
Kaggle 收集了关于 QS 世界大学排名(2017-2022)的数据。QS 世界大学排名是由 Quacquarelli Symonds 每年发布的全球大学排名。QS排名得到国际排名专家组(IREG)的批准,被视为世界上阅读量最大的三个大学排名之一。
2. 数据清洗:
由于数据中多列有缺失值,让我们删除缺失值超过 4 个的行,因为我们无法分析缺失很多属性的大学。

3. 单变量分析:
像上文解释的,单变量分析不会给出两个或多个变量之间的任何关系。它只是解释和描述数据集。在这里,我们找到了平均值、中位数、标准差等。

4. 双变量分析:
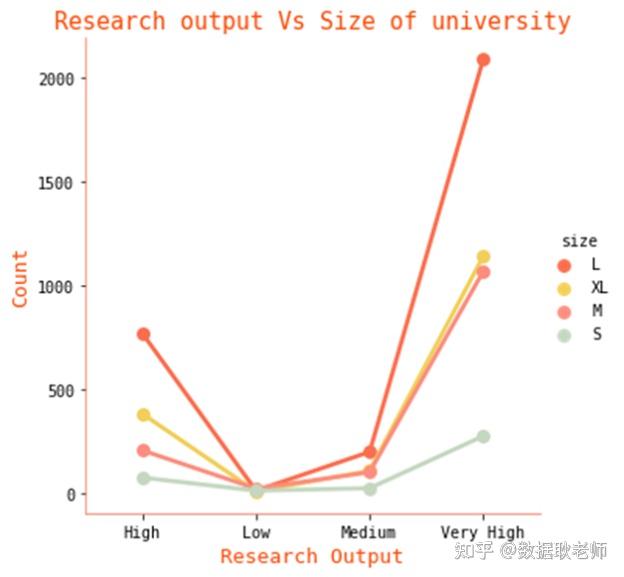
上图展示了大学规模与研究产出的关系。与产出“中”和产出“低”相比,具有“非常高”和“高”研究产出的大学规模更大。
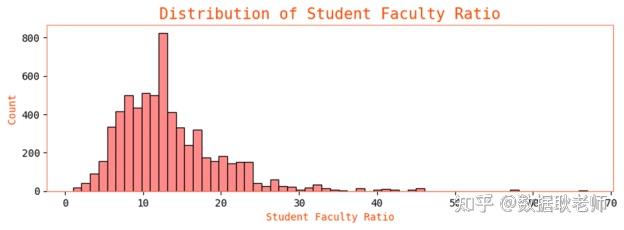
我们还得到了一个右偏分布。异常值似乎对均值影响不大。大多数大学的每个教员都有 5 到 20 名学生。
5. 多元分析:

与其他大学相比,研究成果“非常高”的大学的“师生比例”要低得多。

就规模而言,与公立大学相比,私立大学的“师生比例”要低得多。另一个有趣的观察是,平均“师生比”随着大学“规模”的增加而增加。
结论
探索性数据分析是进行数据分析时重要的第一步,因为它可以发掘出数据中重要的关系,因此可以作为分析过程中的指导手册。


发表评论