当今科技高速发展,新技能和概念不断涌现,我们经常被这些创新所吸引,但是我们的认知常常跟不上热度的变化,而创新的潮头似乎总是风云变换。2021年被称为Web3.0或元宇宙元年,Facebook被更名为Meta,然而短短一年间,元宇宙似乎就成为了过去式。作为被当下备受瞩目的新兴技术,生成式人工智能是否也是过眼云烟的技术概念呢?
我们认为不会。核心原因有三:
1、颠覆式技术:本轮技术浪潮可能是人工智能范式的转换,和过往所有NLP模型不同,以GPT-4为代表的预处理大语言模型具有“理解/推断”的能力。
2、生产力变革:大语言模型对人类的意义在于它是目前“调用数据和资源”最精准、高效的手段,像是使用电脑、手机成为我们的生产工具。未来,每人都将拥有属于自己的定制大模型。
3、应用变革:大语言模型将彻底改变人机交互方式,技术将推动AIGC可用性不断增加。我们判断AIGC未来十年将带来千亿美元的机会,应用层创新将出现百花齐放的场景。
02 Why Now?
1950年,计算机之父艾伦·图灵发表了论文《电脑能思考吗?》,其中讨论创造出具有真正智能机器的可能性,并提出了著名的图灵测试:如果一台机器能够与人类展开对话而不能被辨别出其机器身份,那么称这台机器具有智能。(测试机器是否能表现出与人无法区分的智能)自此,让机器产生智能的想法开始进入人类的视野。
此后,人类一直试图通过图灵测试获得真正的人工智能。

注:美国人工智能教程的封面,图灵和早期重要的推动者与部分工作依然印刻其中。
一、人工智能发展的潮起潮落
(一)第一次浪潮(1956—1970年代)
1956年,达特茅斯学院人工智能夏季研讨会上正式提出使用人工智能(Artificial Intelligence, AI)这一术语。这是人类历史上第一次人工智能研讨,标志着人工智能学科的诞生。
1957年,佛兰克·罗森布拉特(Frank Rosenblatt)在一台IBM-704计算机上模拟实现了一种他发明的叫做“感知机”(Perceptron)的神经网络模型。这是最早的人工神经网络。
本阶段是让计算机具备逻辑推理能力。早期人工智能致力于解决计算机逻辑推理问题,并发明了解决代数和几何的程序,但是受硬件水平限制,计算机缺乏自学能力。这导致人工智能经历了近10年的低潮。
(二)第二次浪潮(1970—2006年)
1、应用发展(1980S—1970年代)
1979年,汉斯·贝利纳打造的计算机程序战胜双陆棋世界冠军成为标志性事件。
1982年,约翰·霍普菲尔德发明了霍普菲尔德网络,这是最早的RNN的雏形。
1989年,LeCun (CNN之父,Meta现任首席科学家) 发明了卷积神经网络,并首次将卷积神经网络成功应用到美国邮局的手写字符识别系统中。
阶段核心:总结知识,并传递给计算机。专家系统模拟人类专家的知识和经验解决特定领域问题,研究走向实际应用。
2、平稳发展(1990s-2006年)
1997年,IBM深蓝技超级计算机战胜了国际象棋世界冠军卡斯帕罗夫,通过生成所有走法探索最佳棋局路径轰动全球。
2003年,Google公布了3篇大数据奠基性论文,为大数据存储及分布式处理的核心问题提供了思路:非结构化文件分布式存储(GFS)、分布式计算(MapReduce)及结构化数据存储(BigTable),并奠定了现代大数据技术的理论基础。
第一次算力和模型的爆发下,人工智能研究的重心从知识系统转向了机器学习,并推出数个关键的技术理论雏形。
(三)第三次浪潮(2006年至今)
2006年,杰弗里·辛顿以及他的学生正式提出了深度学习的概念(Deeping Learning)。
2006年,亚马逊AWS云计算平台发布,进一步大幅提升人工智能模型计算的算力。
2014年,4G时代的到来和智能手机大规模普及,带来了模型训练迭代所需的海量数据养分。
人工智能在诞生之初,社会对其充满了无限的乐观。然而,研究成果很快被证明缺乏实际作用,AI寒冬到来,人们的情绪反复在两端来回盘旋。
随着算法、算力和数据三大要素的任意一项的迭代,人工智能发展也呈螺旋式上升,AI技术也得以逐步成熟和应用到各个领域。
1、生成式AI即将大规模商业化
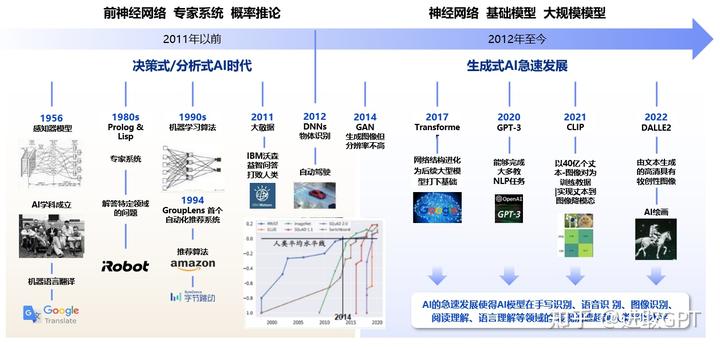
回顾过去人工智能发展,我们可以将该领域的范式归纳为决策式和生成式人工智能,其中发展最成熟也应用最广的当属决策式AI。
(1)决策式AI
决策式AI的基本思想是将问题拆分成多个步骤,然后通过一系列决策和条件判断,逐步缩小答案的范围。
(2)生成式AI
生成式AI是一种利用神经网络和深度学习技术生成新内容的人工智能算法。它通常被用于生成文本、图像、音频或视频等内容,具有模拟人类创造力和想象力的特点。
2016年开始,人工智能技术落地全面爆发,以计算机视觉为首,推荐算法、自然、语言处理等技术得到全面应用和发展,字节跳动、特斯拉等公司应运而起。
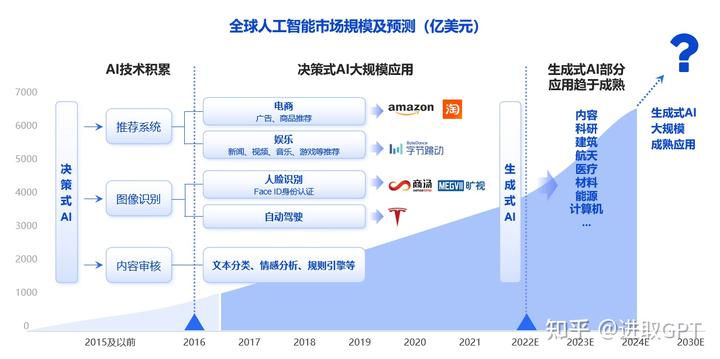
过去决策式AI应用最广泛的地方是个性化推荐算法,通过分析一组数据,发现其中的规律模式并用于多种用途。如果我们把它看作是信息分发的强大引擎,那AIGC就是信息产生的强大引擎,AIGC正朝着效率和品质更高、成本更低的地方发展。
我们判断不同于决策式AI较为成熟的市场及应用,生成式AI刚到技术拐点,其技术能力有机会将过去大部分场景和应用全面颠覆。我们判断的原因有以下几点:
全新架构:随着Transformer架构的提出,深度神经网络的学习能力和模型大小呈正相关,模型参数从几万提升到数千亿量级,这促进了人工智能技术的进一步提升。
算法(模型)发展:GPT-3、Diffusion、DALL-E2等模型的提出,极大地提高了AI能力的上限,从而为人工智能技术的应用提供了更多可能性。
优质数据供给:通过使用更多优质数据进行训练,算法可以从中学习到更多有效的信息,从而提高模型的精度和效率。
算力提升:随着硬件技术的不断提升,训练算力大约是5年前的10到100倍左右,这为AI技术的应用提供了更多可能性和空间。
03 范式的变化
一、过去的范式
过去机器学习一直没有摆脱“Data Fitting”的基本范式,即找到数据的对应关系并应用。这有些像“鹦鹉学舌”,机器学习找到的对应关系仅仅能在已有信息包含的范畴之内总结规律。
Siri刚出来的时候,当时大家都曾觉得这是人工智能,但背后不过是NLP做的填表任务,语音助手从来没有真正“懂”这些指令。
二、新的范式
朱松纯教授在2017年有一篇思考人工智能和智能本质的文章,举了一个关于乌鸦和鹦鹉的例子,深刻揭示了什么是新的范式。

一只乌鸦发现并安全吃到坚果的全流程
没有人教会乌鸦如何安全的吃到坚果,在情境中,乌鸦安全吃到坚果需要满足三个隐性条件:
1、掌握红绿灯(车)规律
2、车可以压碎坚果
3、车可以撞死乌鸦
过去的范式:鹦鹉学舌,所有乌鸦共用一个大脑,用穷举的方式尝试所有可能性,直到吃到坚果。
新的范式:尝试让自身学会乌鸦是如何“推理/推断”得到结论。
鹦鹉学舌:先听,再模仿,基于“对应关系”
乌鸦:先观察,再学习,基于“内在逻辑”
ChatGPT/GPT-4看似拥有乌鸦的能力。
04 ChatGPT & GPT-4
一、什么是ChatGPT?
背景:2015年,谷歌刚刚收购了位于伦敦的人工智能公司DeepMind(推出击败围棋世界冠军的AlphaGo)。当时Elon Musk、YC总裁Sam Altman、PayPal的Peter Thiel等人在一个晚宴上讨论,这是一家最可能开发生成式人工智能的公司,如果DeepMind成功了,谷歌可能会垄断这项技术。在这个背景之下,OpenAI成立了。起初,其作为一个非盈利组织运营,承诺公布其研究成果并开源所有技术。
从2018年开始,OpenAI就开始发布一系列生成式预训练语言模型GPT(Generative Pre-trained Transformer),用于一系列问答任务。
每一代GPT模型的参数都会爆炸式增长,初代GPT的参数为1.17亿,到了ChatGPT,参数量达到了惊人的1,750亿。ChatGPT是基于GPT3.5架构开发的对话AI模型,是InstructGPT的兄弟模型,是OpenAI演化两年后的产品之后更一举推出GPT-4。
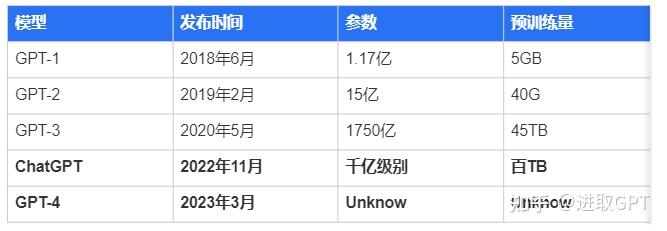
ChatGPT本质是一个大语言模型,聊天机器人,它可以模仿人类的语言行为,为用户提供自然聊天体验,并拥有精准的上下文语义捕捉能力,可以被应用在各个领域。接触过它的人都会被其能力所惊艳。
谷歌高级副总裁和 Google Brain 负责人 Jeff Dean 更是盛赞道“ChatGPT具有成为未来基于语言的人工智能应用程序基础的潜力。
此外,ChatGPT是有史以来月活用户超亿最快的2C应用,达到同样的成就,TikTok用了9个月时间,Instagram花费了两年半。
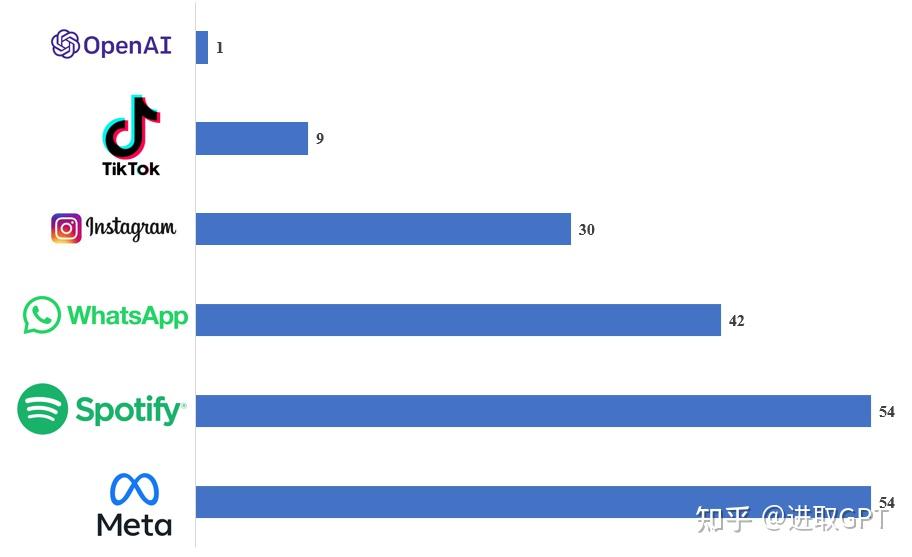
各大热门平台月活破亿所需时长(单位:月)
二、ChatGPT能力展示
理解能力展示
写作能力展示

ChatGPT是一种高度智能的语言模型,可以对复杂问题进行自动解析,并给出相关建议。对于从未见过的问题,只要通过人类语言提示“let's think step by step",甚至无需任何提示,AI就可以自动拆解复杂问题,并给出一个靠谱率明显提升的答案。
三、 GPT— 4
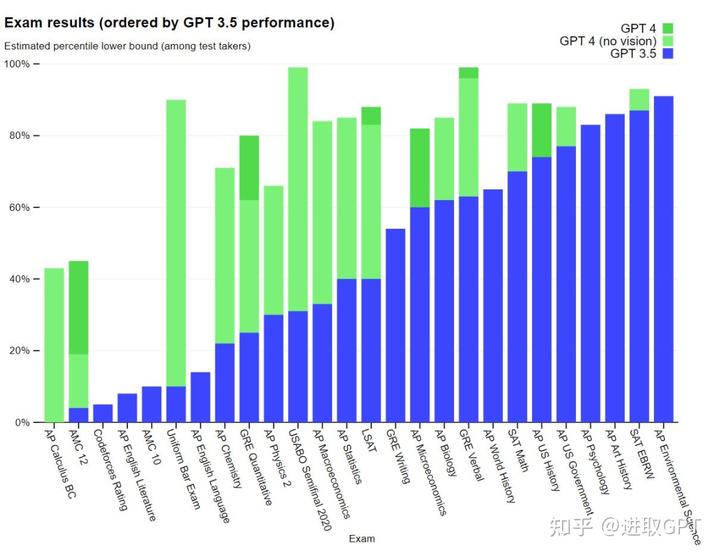
能革掉ChatGPT的只有它自己。新近发布的GPT-4能力又上一个大台阶,在图文识别、文字输入和回答逻辑准确性均有显著提高。
GPT-4手机跑分
超强计算机视觉+推理能力


准识别冰箱内的水果、肉类,并能给出推荐的菜谱
手绘草图,十秒生成网站代码
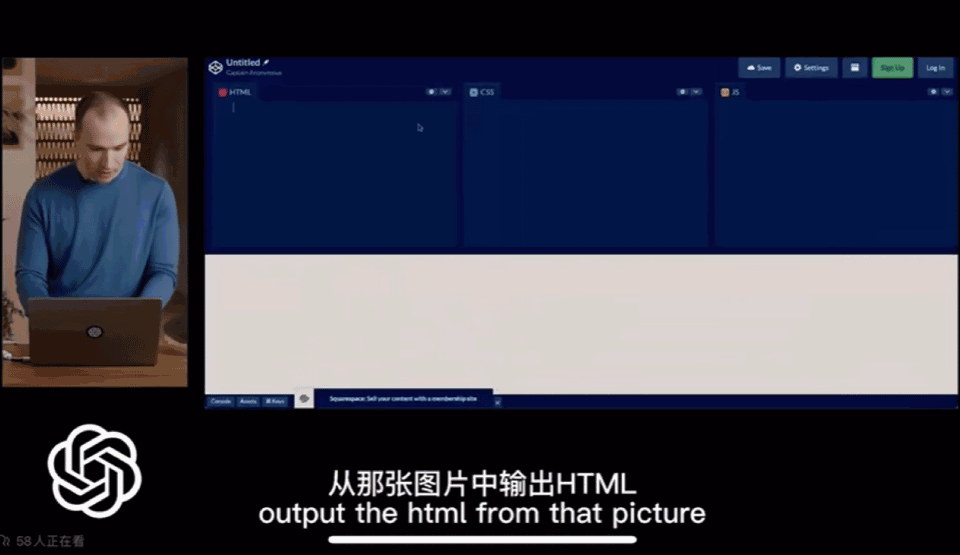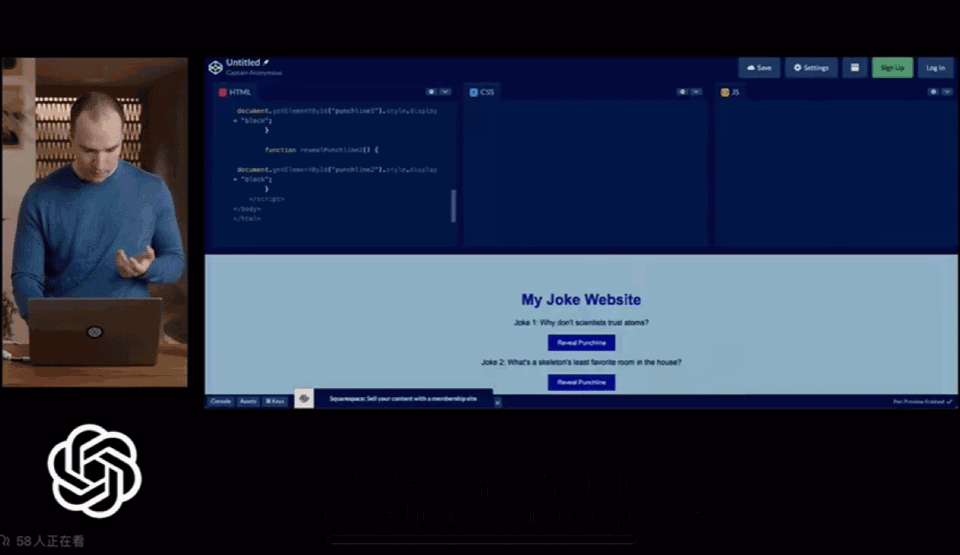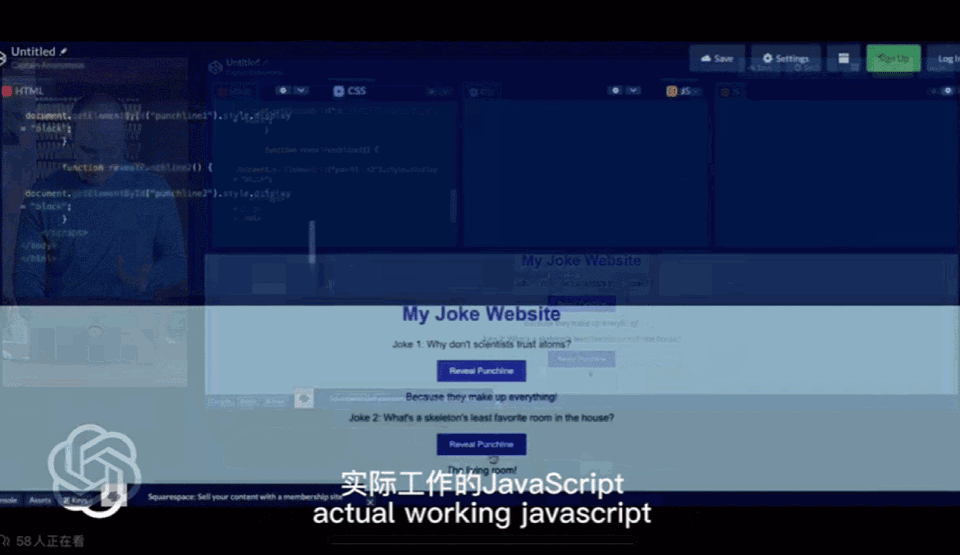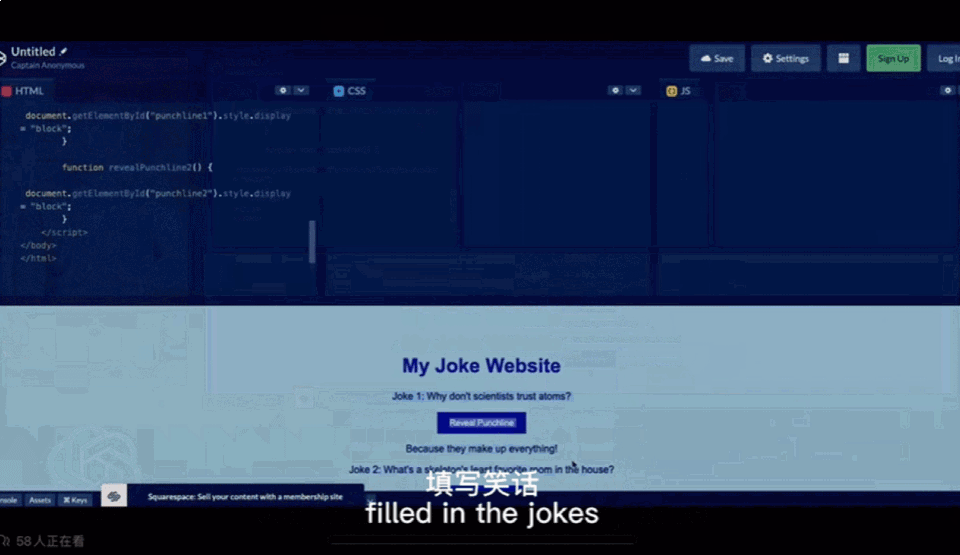
第一张图Greg用手机拍了张照片,之后GPT-4生成了网页所需的代码并可以运行
2023年3月16日,微软推出Microsoft 365 Copilot,GPT-4结合AI驱动工具Copilot整合进微软全家桶,所有用户都可以用人工智能自动生成文档、邮件、Excel、PPT。Talk is Cheap。
微软&OpenAI一骑绝尘,开启应用颠覆之旅。
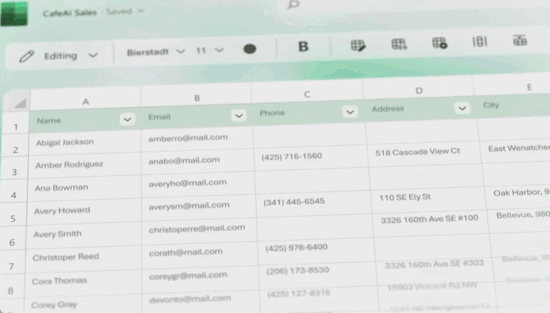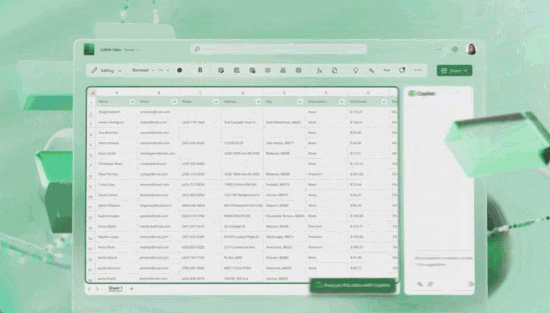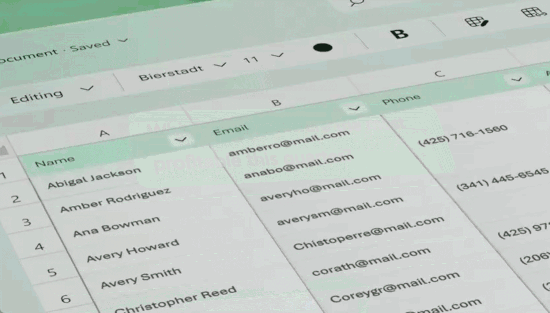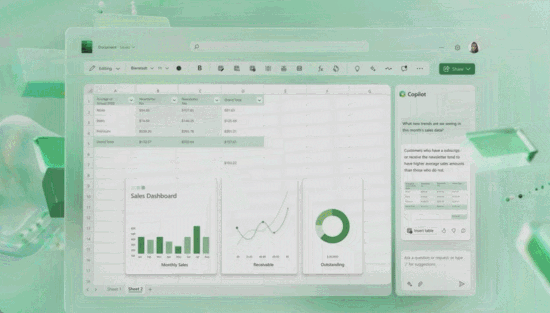
示例:创建基于数据的PivotTable
四、GPT的发展历程
1、2018年6月发布的GPT-1,其参数量为1.17亿,使用transformer的decoder架构和任务微调,具有一定的泛化能力。
2、2019年2月发布的GPT-2,其参数量为15亿,使用了更多的预训练数据和优化后的网络架构,具有prompt learning的能力,能够在生成方面表现更强。
3、2020年5月发布的GPT-3,其参数量为1,750亿,使用了更优秀的技术架构、更大的参数规模和数据量,成为了GPT时代的基石,能够完成绝大部分自然语言任务。
4、2022年1月发布的InstructGPT,它是基于GPT-3的微调,重要的是强化学习人类反馈(RLHF),能够将有害、不真实和有偏差的输出最小化,从而实现更贴近人类偏好的能力。
5、2022年11月发布的ChatGPT,它是InstructGPT的衍生产品,优化了人类反馈的训练过程,能够更好地使模型输出与用户偏好保持一致,并且在内容安全方面有了一些优化。
6、2023年3月发布GPT-4,极大提升了文字输入上限和图片识别能力,对于回答问题的逻辑和准确性有显著提升。






发表评论