一篇文章写清楚一个问题,关注我,自学python!
本来打算写一个python做结构方程模型系列的,发现python并不能生成路径图,于是决定先学习R吧,毕竟我时间有限,之后还是会更新python,也会加上R,感兴趣的朋友可以关注一波。今天给大家写写验证性因子分析的做法。还有因为自己用惯了jupyter,用Rstudio不太习惯,所以给jupyter安上了R内核,目前在jupyter中跑R,很舒服。
因子分析
介绍验证性因子分析之前还是先给大家介绍一下因子分析,因子分析分为两种:
所以说做验证性因子分析必须有理论基础,此方法本身只是一种验证性的方法。
举个例子:
比如我现在编了一个量表测量「工作伦理」,我首先应该做个EFA,我发现而依照EFA的结果,我编的量表其下又可分为工作态度与工作意义感两个维度,工作态度有X1~X3共3个条目表示 ,工作意义用X4~X6这六题表示。
那么我们在进行CFA时,就会依照上面的理论设定模型,然后看整个数据适配该模型的结果如何?简言之,就是看理论与实证数据是否贴近,称之为验证。典型的验证性因素分析(在SEM中或称为测量模型)如下例图:
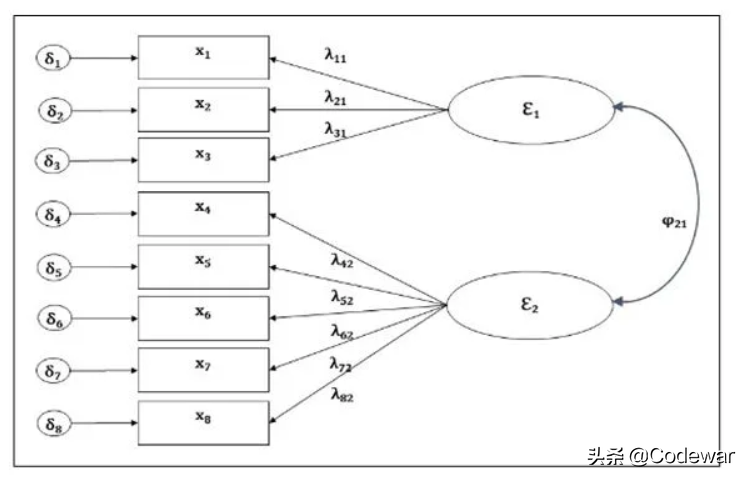
从上面的叙述中我们也可以看到,做因子分析得用两套数据,一套探索,一套验证,本文只写验证性因子分析的做法。
R语言实操
library(lavaan)
library(semPlot)
data <- read.csv("cfa.csv")CFA_model = '
familiar =~ q3 + q13 + q14 + q16 + q20 + q21 + q22 + q23 + q27 + q30
attitudes =~ q1 + q2 + q4 + q5 + q8 + q11 + q18 + q19 + q28 + q29
aversion =~ q6 + q7 + q9 + q10 + q12 + q15 + q17 + q24 + q25 + q26
'上面的代码就是说q3 + q13 + q14 + q16 + q20 + q21 + q22 + q23 + q27 + q30这些条目就是用来表示familiar这个因子的,attitudes和aversion同。
myCFA = cfa(CFA_model, data = data)在上面的代码中,我将拟合好的模型给myCFA对象。
summary(myCFA)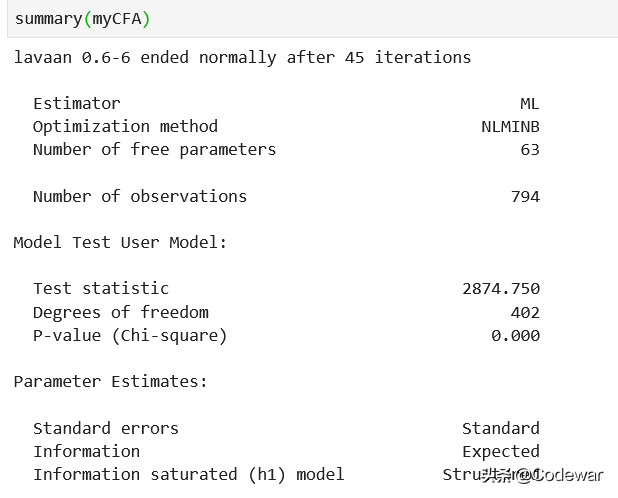
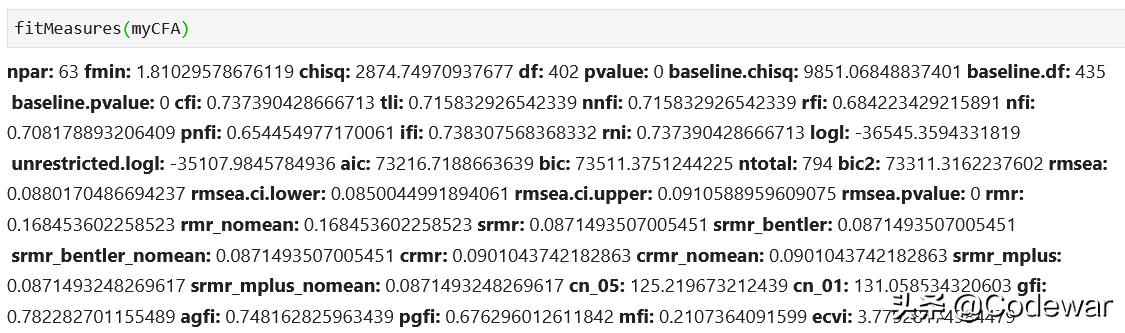
可以看到直接用summary方法就可以得到模型结果,要查看其他的拟合指标的话还可以用fitmeasure方法,很简单。
semPaths(myCFA, whatLabels="std", layout="tree")后面两个参数都是可以变的,大家可以自己试试,输出如下图:
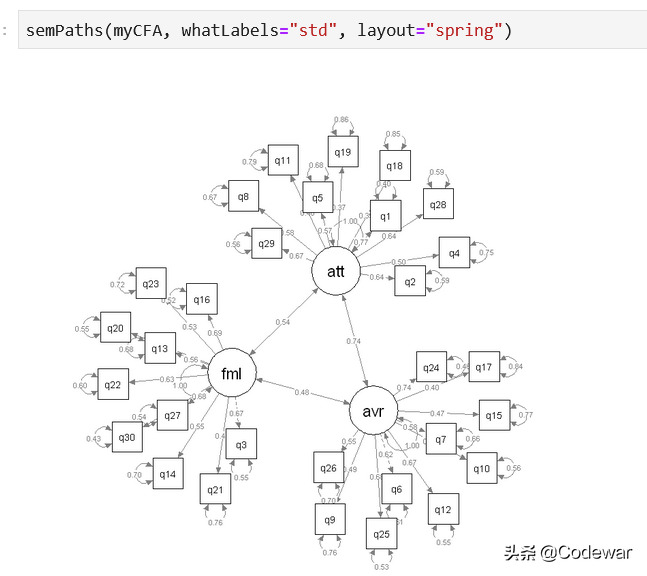
可以看到各个因子载荷,因子相关都直接显示出来了,很棒。
小结
今天给大家写了CFA的做法和图形画法,感谢大家耐心看完。发表这些东西的主要目的就是督促自己,希望大家关注评论指出不足,一起进步。内容我都会写的很细,用到的数据集也会在原文中给出链接,你只要按照文章中的代码自己也可以做出一样的结果,一个目的就是零基础也能懂,因为自己就是什么基础没有从零学Python的,加油。
(站外链接发不了,请关注后私信回复“数据链接”获取本头条号所有使用数据)
往期文章:
R数据分析:结构方程模型画图以及模型比较,实例操练
python数据分析:如何用python做路径分析,附数据库实例操练






发表评论