应该如何阅读古籍?人们通常认为,阅读古籍要选择合适的版本,了解历史背景知识,借助注释和工具书,对照其他相关文献,才能更好地体会古籍的独特之处。然而,事实上,“找不到、不会用、读不懂”是人们阅读古籍时面临的常见情况。
随着人工智能技术的发展,这些问题正在慢慢解决。近日,在字节跳动研发的“识典古籍”数字化平台上,读者多了“古籍智能助手”的选项——选中读不懂的古文原文点击“问AI”,就可以看到这句话的翻译,并可以用日常说话的方式,让智能助手总结文本内容,提出可供参考的研究问题。
可以看到,古籍智能助手降低了古籍的阅读门槛,让流传千百年的宝贵文献走入寻常百姓家。事实上,以古籍智能助手为代表的人工智能工具还有更长远的价值——在让更多读者亲近古籍的同时,为古籍数字化工作带来了机遇,“我们所处的新时代,有可能实现文化典籍永久保护和传承。”业内人士表示。

识典古籍相关海报
让大模型更会检索
在字节跳动看来,古籍智慧助手上线有赖于近年来人工智能技术的爆发式发展。
2022年3月,字节跳动向北大教育基金会提供捐赠,全面支持“北京大学-字节跳动数字人文开放实验室”的工作。彼时,字节跳动计划研发古籍数字化平台,利用智能技术加速中华古籍资源的数字化建设,向全社会提供公益化服务。如今,“识典古籍”数字化平台已上线,免费开放古籍超过2900部。目前“识典古籍”平台为方便用户的检索和阅读,已上线了全文和分类检索、字典、古籍译文、命名实体查阅百科等功能。
然而,“识典古籍”数字化平台研发团队发现,虽然平台内辅助工具繁多,但是用户的需求依然没有被精准满足——“找不到、不会用”成为用户使用古籍阅读工具时的一大难关。
“大模型技术发展以后,我们开始自然而然地思考,对于用户来说,利用人工智能,以对答的方式和数字化平台进行交互,会不会是更好的体验?”“识典古籍”数字化平台产品经理汪晴表示,“我们希望为研究和检索古籍提供便利。”
基于在OCR(文字识别技术)、自然语言处理、知识图谱等技术领域的积累,以及互联网产品设计与研发优势,研发团队很快对古籍智能助手有了初步的设想:打造一款能够帮助用户检索、阅读,甚至深入挖掘古籍知识的工具。
然而,古籍智能助手只是一个具有实验性的新事物,当初的期待想要落地还需要长久地摸索。研发团队首先想到的是利用大模型为用户带来额外的惊喜。于是,经过了多轮的磨合和探索,字节跳动研发团队决定将研发的重点放在检索增强生成技术上。
“识典古籍”数字化平台产品负责人王宇介绍,检索增强生成技术是通过检索不同资料来源,获得所需上下文,来“增强”大模型生成答案的质量。比如从古籍数据库里检索古籍资料,让获得的上下文更加相关。在关键词检索之外,研发团队还开发了语义检索,让智能助手在回答时能参考到虽然文字不一样、但含义相关的相关古籍段落。
这也让古籍智能助手和市场中已有的通用大模型形成了差异。“古籍智能助手并不是靠前期训练时使用的数据和知识进行解答,而是实时调动较新的专业数据库,这是通用大模型难以做到的。”汪晴说,“我们希望古籍智能助手是具备专业度的。”
增强问答准确性
古籍智能助手的研发也并非一帆风顺。对于字节跳动研发团队来说,最大的难点莫过于大模型会产生错误和“幻觉”。
产生“幻觉”几乎是大语言模型的“通病”。有学者曾指出,这种“幻觉”是指人工智能会生成貌似合理连贯,但同输入问题意图不一致、同世界知识不一致、与现实或已知数据不符合或无法验证的内容。
有专家认为,从技术原理上看,人工智能“幻觉”多由于人工智能对知识的记忆不足、理解能力不足、训练方式固有的弊端及模型本身技术的局限性导致。而现阶段,大模型产生错误“幻觉”的情况难以完全消除。
然而,在古籍领域,基于文言文可能出现的阅读障碍,由大模型产生的错误和“幻觉”让用户更加难以分辨。但是即便如此,字节跳动研发团队依然希望能尽可能减少“幻觉”,并让用户在希望追求准确性的时候,能够进行查证。
相关负责人表示,为了减少大模型产生的“幻觉”,团队付出了巨大的努力:一方面,古籍智能助手使用了检索增强生成技术,这样就要求大模型根据从数据库和字典中检索到的、有一定可靠性的资料作答,在一定程度上限制了大模型产生“幻觉”;另一方面,研发团队正在尝试在生成的答案后附加原文链接,这样对于写作等场合,用户就可以方便地去原文查证并且做出自己的判断。不仅如此,在古籍智能助手的界面,研发团队还设置了“回答由人工智能生成,请注意查证”的提示词。
“古籍智能助手的作用是提升查阅古籍的效率。它代替不了专业的学术判断和阅读积累,但我们希望它能为使用古籍的人节约时间、开拓新的思路。”王宇表示。
在减少大模型“幻觉”的基础上,古籍智能助手最终还是上线与用户见面。在“识典古籍”数字化平台,当用户选中古籍中的文字并点击“问AI”,或者输入问题时,古籍智能助手首先会对用户提出的问题进行意图判断,如果回答这个问题需要利用字典中的条目或者古籍数据库搜索结果作为上下文,智能助手会获取相关的上下文,然后通过大语言模型综合总结并给出回复。
汪晴称,古籍智能助手上线几周后得到了较好的反馈。“很多用户通过智能助手去理解句子含义,帮助用户实现了从‘不懂’到‘懂’的跨越。不仅如此,展示参考引用的功能也受到了用户的好评。虽然目前古籍智能助手还无法将参考引用完全展示,但依然有用户表示对发现之前忽略的知识有帮助。”
让古老经典“活”起来、传下去
虽然古籍智能助手已经上线运行,但是研发团队并没有停下探索的脚步。汪晴表示,在功能方面,正在计划逐步为古籍助手提供更多的工具,比如是否能从百科资料中检索答案,是否能和一些更加专业的数据库进行合作。“我们也希望用户能够多使用和反馈,为后续优化提供建议,通过实践和应用来打磨出好的产品。”
在汪晴看来,这种探索为阅读古籍的用户提供了便利,也拉近了公众和古籍之间的距离,让经典更加触手可及。“这也是古籍智能助手给‘识典古籍’数字化平台带来的较为突出的价值。”
业内普遍认为,将大模型和人工智能引入古籍保护领域是时代带来的便利。今年全国两会期间,有委员表示,中国是全球拥有古籍最多的国家,国内现存汉文古籍300万部,散落在海外的古籍超过40万部,已完成数字化的古籍7.4万部。
可以看到,还有大量的古籍被束之高阁。不仅如此,对于古籍来说,修复的速度远远赶不上老化的速度,古籍数字化迫在眉睫。
对此,王宇认为,大规模解决古籍数字化的问题只能等待技术进步,而近十年,大模型和人工智能的飞速发展刚好为加速实现全部古籍数字化带来了技术条件。
“如果现存古籍全部数字化,那么我国古籍保护就迈上了一个新台阶,古籍灭失的可能性就大幅降低了。这对于赓续中华文脉,将是一个了不起的贡献。”有学者表示。文/李濛
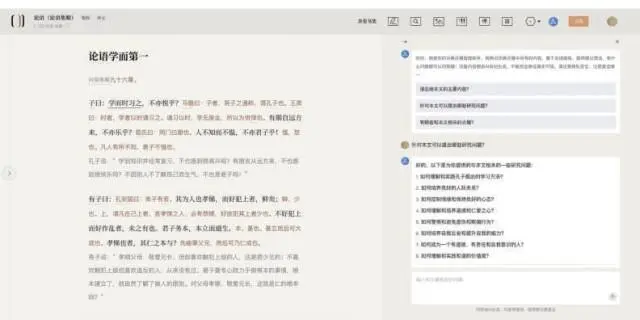
古籍智能助手宽屏模式页面截图

发表评论