简介
为了更好地保护与利用古籍,提升古籍数字化水平,向大众传播古籍知识,在字节跳动的支持下,北京大学与字节跳动公益部门联合成立了“北京大学-字节跳动开放实验室”,期望解决古籍数字化利用过程中的瓶颈问题,打造互联网环境下内容丰富、使用便捷的高质量古籍数字化阅读平台,面向海内外学者和古籍爱好者免费开放。同时为了支持阅读平台的数据加工的需要,还建设有面向古籍收藏机构和整理人员的一站式古籍智能整理平台。
背景
中华民族在数千年历史发展过程中,创造了光辉灿烂的文化,留下了灿若群星、独具特色的古代文献典籍。随着数字化时代的到来,古籍的保存与整理工作也亟需人工智能技术的注入,使其更加丰富、更加立体、更加便捷。尽管海内外已有不少古籍阅读平台,但是在方便大众阅读、整理质量、阅读体验等很多方面都有很大的提升空间。
2022 年 3 月,北京大学数字人文中心接受字节跳动公益的捐赠,联合成立“北京大学-字节跳动数字人文开放实验室”,致力于古籍资源的智能开发与利用,研发基于古籍智能化处理的“识典古籍”阅读平台与整理平台,面向社会公众提供对古籍数字化资源免费公益的访问和利用。
“识典古籍”平台致力于在检索方式、异体字支持、文字质量、阅读辅助、浏览体验等多个方面进行探索,期望建立一个文字精良、功能丰富、阅读体验优秀的古籍阅读平台。同时,识典古籍有着丰富的检索功能以及分类与时代筛选功能,因此也是一个初步的古籍研究平台,辅助分析概念与句子在各部类与时代的分布与差异情况。
系统介绍 1. 书库浏览
阅读平台设计了简单易用的书库浏览功能,书库沿袭传统的经、史、子、集四部分类法,同时外加道教部、佛教部,涵盖古籍的全部类别。每种分类皆有二级类目,部分有三级类目。为了便于使用,道教部、佛教部的分类方法均遵照传统方法。
平台上对每一种书不仅标示了书名、卷数、作者、作者年代、版本等基本信息,而且每一种书的作者都有简单的作者介绍与内容简介,以方便学者了解其大致内容。
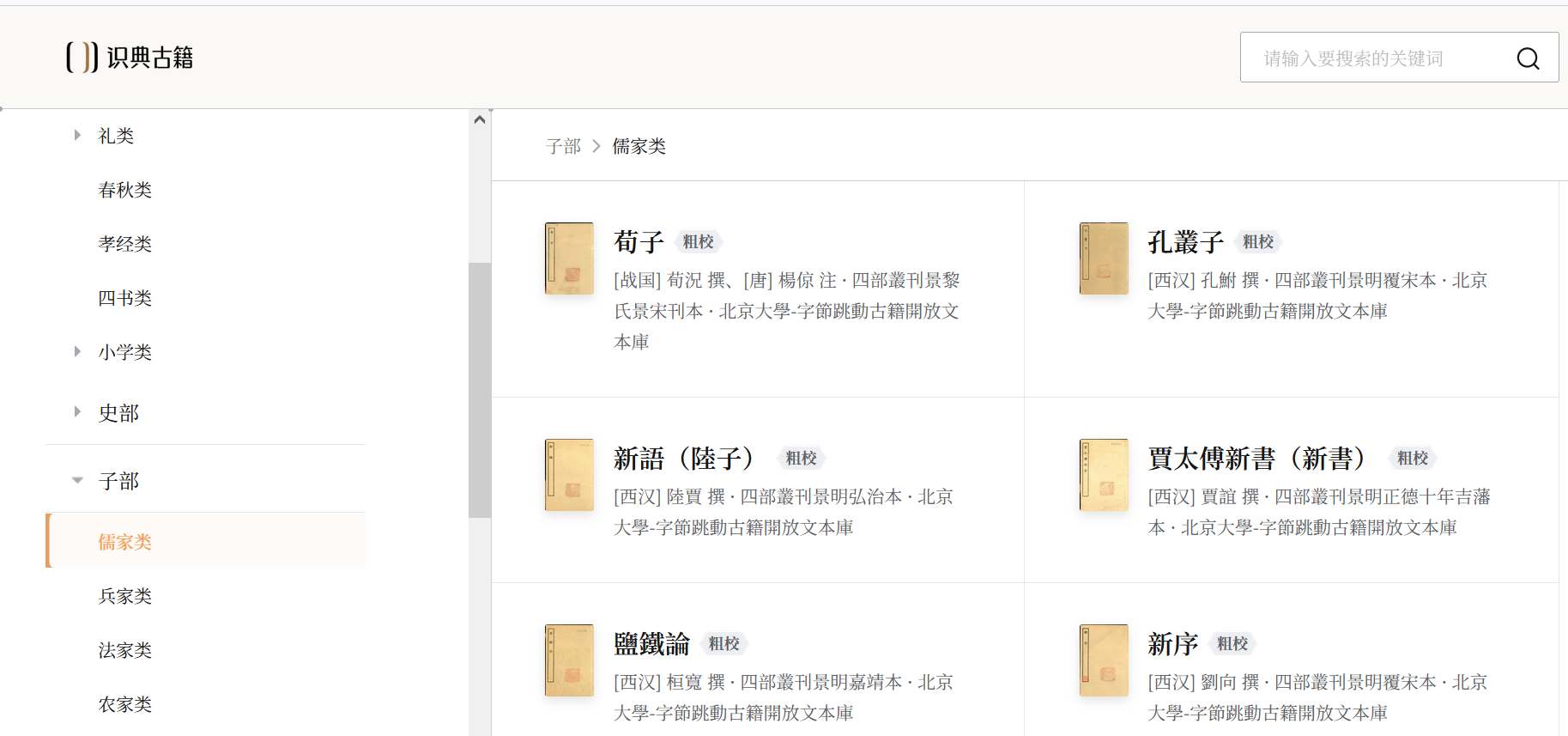
图1. 书库浏览
值得一提的是,书库的排列顺序大致按照书籍的撰述年代排序。撰述年代只用于排序,并不会展示给读者。很多古籍的写作年代均无法考证,除少数能够确定准确的撰述年代之外,一般采用作者卒年作为撰述年代。如果作者本身生卒不详,则根据作者生活的大致年号等进行推算。
2. 图文阅读
具体的阅读界面,是适配屏幕阅读的横排的方式,默认以繁体字型显示。为了提高文本内容的可靠性与可用性,可以采用图文对照的模式进行核对。文本施以现代标点,以方便阅读。
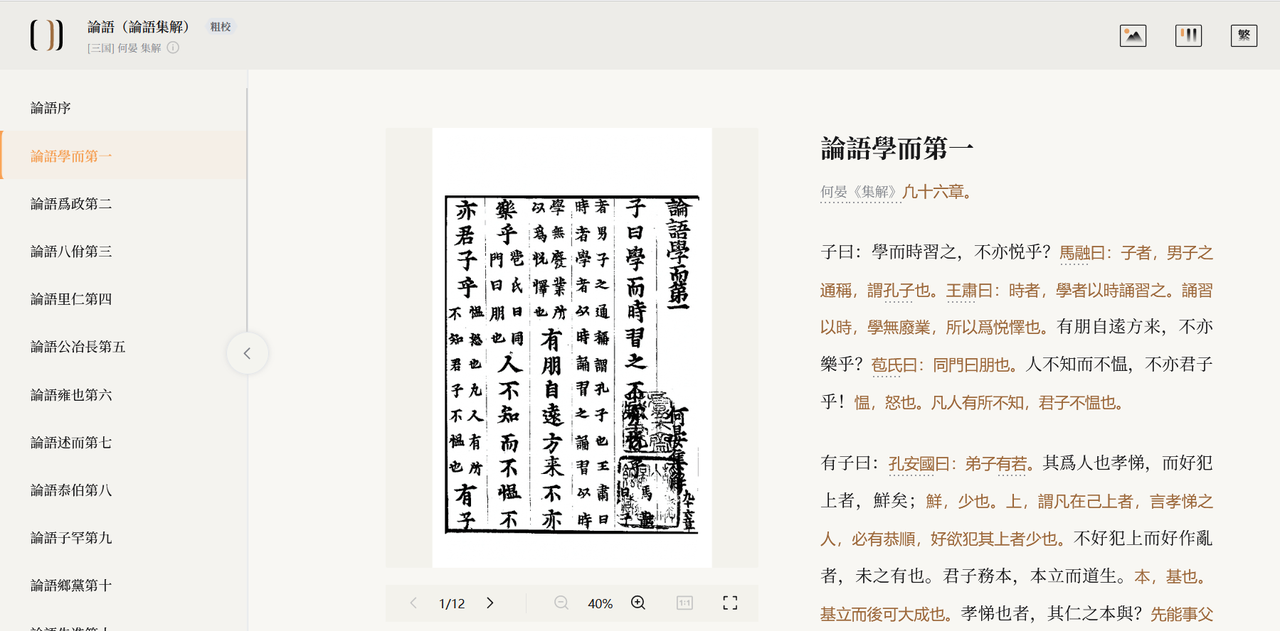
图2. 阅读界面
文本的质量目前有粗校、精校两种。粗校主要是指文本较为准确,但是标点与实体的识别都是通过机器自动识别,还未经人工校对。精校则是文字、标点、实体均经过人工的认真校对。目前平台上的部分文本正在精校过程中,已经精校的文本将陆续上线。
除了图文对照的功能之外,书籍的阅读支持三级目录的显示,同时还支持隐藏注文、繁简转换等功能。更多、更丰富的阅读功能还在开发过程中。
为了提供更佳的阅读体验,阅读平台还开发有移动端的阅读界面,以适配手机端、平板端的阅读。

图3. 移动端浏览界面
3. 整理平台
与阅读平台进行无缝衔接的是背后的整理平台。整理平台可以将图片数据经过整理发布到阅读平台,还可以将阅读平台中粗校的数据进行精加工。整理平台设计了从古籍图像 OCR、文字校对、文字对勘、标题的识别与校对、分段、标点校对、实体校对等环节。同时该平台还支持古籍元数据的修改,任务分发等。所有这些整理工作都尝试充分利用人工智能技术与计算机技术的优点,在计算机辅助下实现人机协同加工与整理,最大程度地减轻整理者的工作量。

发表评论