用来做降维处理的统计方法,SPSS提供了比如因子分析、主成分分析、对变量聚类等。
01
案例数据
洛杉矶12个地区的五项社会经济指标,人口pop、教育school、就业employ、服务业services及房价house,试 综合五项指标提取公因子对12个地区进行评价。
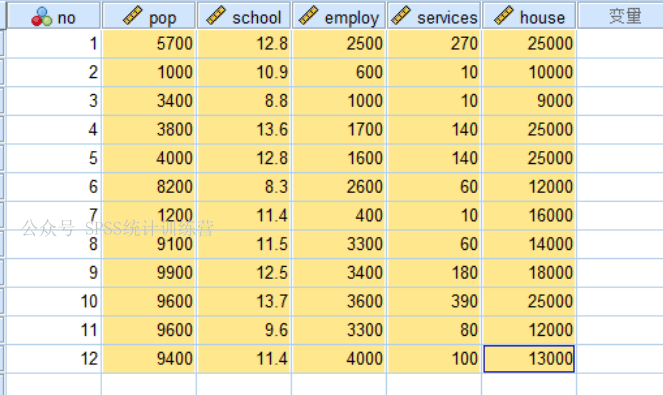
五项指分别反映了地区五个不同的发展方面,如果要给地区发展一个综合的评价,对五个指标进行降维处理是一个办法。
02
SPSS菜单对话框
菜单:【分析】→【降维】→【因子】,打开因子分析主对话框。
对 人口pop、教育school、就业employ、服务业services及房价house 五个指标进行降维处理。
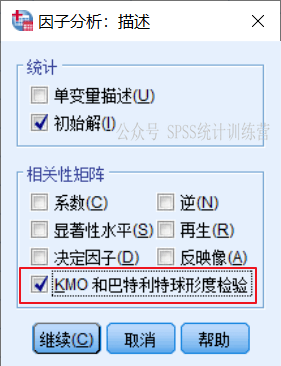
点开【描述】对话框,要求 输出kmo和巴特利特检验,我们要看一看数据是否适合做因子分析,这是基础工作。

点开【提取】对话框,这里有极其重要的参数选项。
1)提取公因子的方法有不少,SPSS提供了7种, 默认推荐使用主成分法提取,这是很流行的,或普遍认可度较高的一个方法。其他方法比如最大似然法、主轴因子法、a分解法等,本案例就使用主成分法。
2)SPSS基于相关性矩阵提取的好处是,省去我们对原始数据做标准化处理。
3) 最终提取几个公因子合适呢?总的原则是信息损失不能过大,为此我们可以综合特征值大于1,方差贡献度超过60%,以及碎石图拐点来综合判断。
点开【旋转】对话框,为方便对公因子的实际含义进行提炼归纳,我们建议 直接做最大方差的旋转。输出载荷图看看可视化的效果如何。
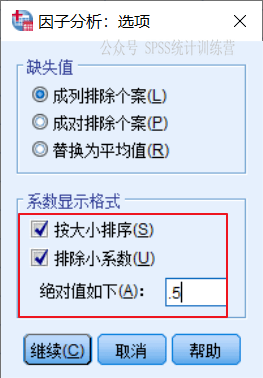
点开【选项】对话框,我们要求对载荷矩阵数据再做调整,首先是排序,然后是隐去小于0.5的载荷,便于观察公因子和变量间的关系。
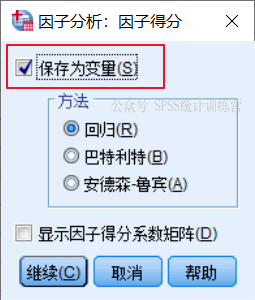
点开【得分】对话框, 要求软件计算公因子得分变量,这样我们就有了新的数据来对12个地区主体做评价了。
03
公因子的个数
只解读重要的结果,以及必要的结果,其他结果略。

kmo=0.575>0.5,巴特利特检验 p<0.05 我们认为现有的数据做降维处理具有相关性的前提条件基础,数据适合做因子分析。
特征值大于1的因子有两个,分别为2.873和1.797。 这两个因子的累积方差贡献率93.4%,意思是说两个因子可以对原来5个指标做充分的概括。
碎石图,拐点很明显,前两个石头落差较为突出。
综合以上信息,我们决定提取前两个因子作为公共因子。
04
公因子的含义
怎么对公因子F1和F2进行命名呢?看下面这篇文章。
→ 因子分析载荷系数表结果如何解读?简单高效因子命名方法!
公因子F1的信息主要从哪里来呢,房价+教育+服务业,三个载荷系数均在0.7以上,公因子F2的信息来自人口和就业,两个载荷系数均在0.7以上。
归纳一下:
F1:发展因子或福利因子
F2:规模因子或人口因子
05
公因子的使用
原来有五个社会经济指标,降维处理后,我们发现了两个公因子福利和人口因子。能不复杂就不复杂, 能简约就简约, 咱们现在就用两个公因子来对12个地区做评价。
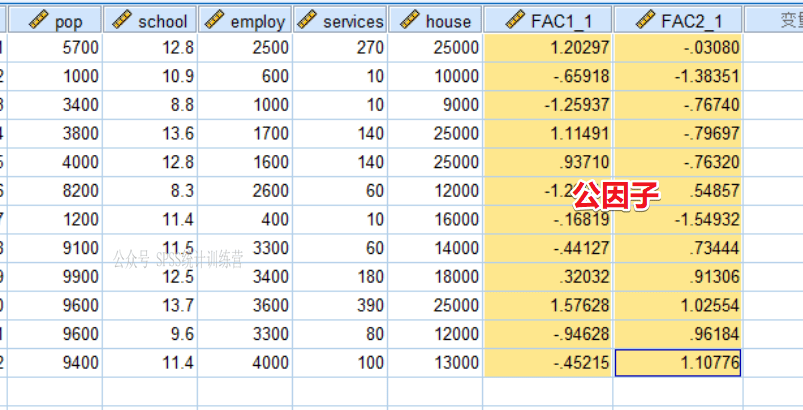
福利和人口两因子可不是嘴说的,来看原始数据后新计算生成的两个因子得分变量。
这次案例,我就不写什么构造因子总得分之类的操作了。咱们直接利用两个公因子来 绘制一个四象限图不是更加直观的嘛,这一步当然也是SPSS完成。
以FAC1和FAC2作为横轴和纵轴画散点图,再以个案号或者地区名称为标签,来观察12个地区在二维图形上的分布状况。
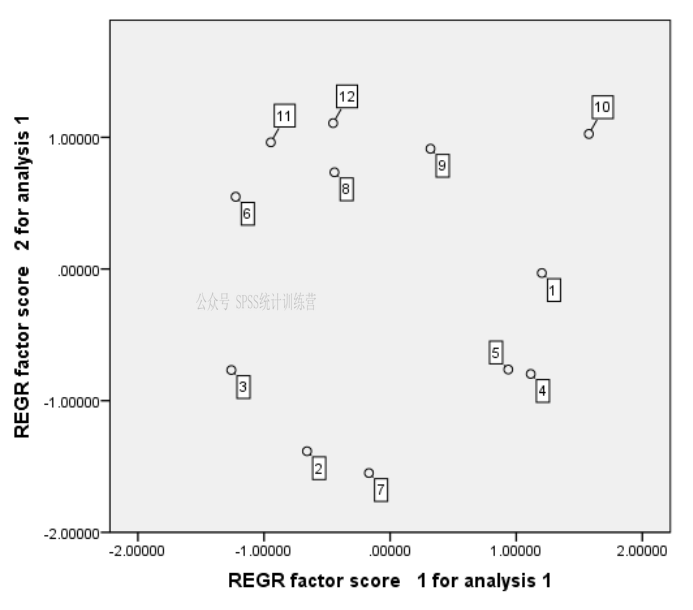
然后是横轴纵轴 添加0刻度横线和0刻度竖线,做个简约版四象限图。
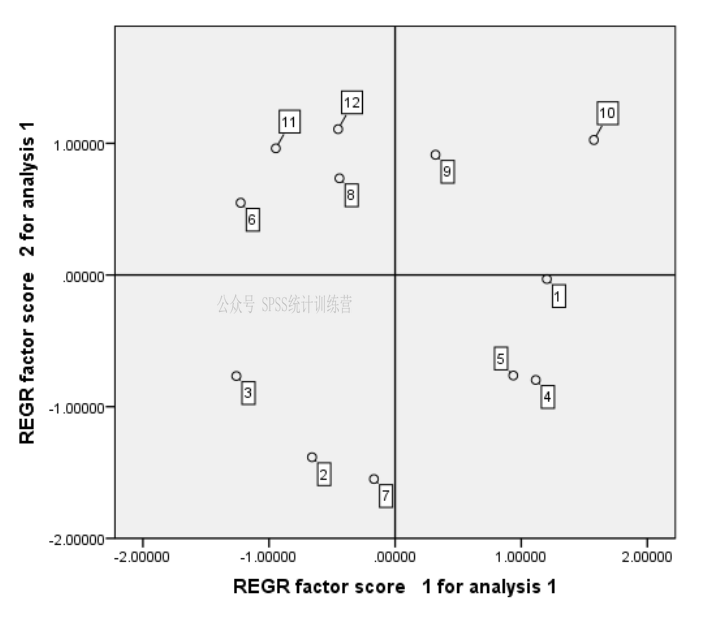
把12个城市放在一个二维平面图上,以四象限图将12个城市划分为4个类型,想必做社会研究的读者应该已经能看出端倪了,专业上如何去解释城市间的区别,如何以两个公因子数据对12个城市进行综合评估,这个事情咱们就交给专业人士去做。
SPSS做因子分析的演示,到此结束。
-------------------------------------






发表评论