看似小小的中介,废了我好多脑细胞,这个东西真的不简单,从7月份有人问我,我多重中介,到现在的纵向数据中介,从一般的回归做法,到结构方程框架下的路径分析法,到反事实框架做法,从中介变量和因变量到是连续变量到中介变量和因变量是分类变量,很浩渺的系统知识,今天开始一点一点给大家写。
今天就和大家一起探讨纵向数据的中介效应检验,一般来讲考虑因果关系的时间先后顺序,纵向数据才是探讨中介的理想数据形式:
In practice, it is strongly recommended to establish mediation with longitudinal data
但是问题也存在,就是说同一波次的中介变量和因变量可能成为纵向中介路径上的混杂,自己会影响自己,自己又会受到中介变量和自变量的影响,这些中介和暴露又会受到前一波数据的影响,怎么说得清呢?况且做了中介我们还需要对每个路径上的效应进行分解,感觉好难哦。
今天就写写这个。
随机效应交叉滞后中介模型引出
首先明白一点,做中介用纵向数据才好,其次明白,交叉滞后是纵向面板数据的常用分析方法:
the CLPM allows time for causes to have their effects, supports stronger inference about the direction of causation in comparison to models using cross-sectional data, and reduces the probable parameter bias that arises when using cross-sectional data.
再记住,纵向数据的中介分析的做法之一就是使用交叉滞后。
但是传统交叉滞后不考虑个体扰动,只拟合全部个体的均值,所以在特定人群中估计系数可能不准(理解方法参考混合模型),因为存在上面的问题,所以一般我们会做一个允许个体扰动的情形下纵向数据的中介模型------multilevel model (MLM):
multilevel model (MLM), which is proposed on the basis of the fact that longitudinal data are clustered in nature: The repeated measures are nested within individuals
通过多水平模型我们允许个体扰动,使得模型更符合数据层次,但是开篇就指出,在纵向数据中我们需要控制掉前一波数据的影响,和同波次数据的相互影响,所以我们把多水平模型和交叉滞后一结合,形成带随机效应的交叉滞后就可以啦。
传统交叉滞后中介模型
开篇一张图:
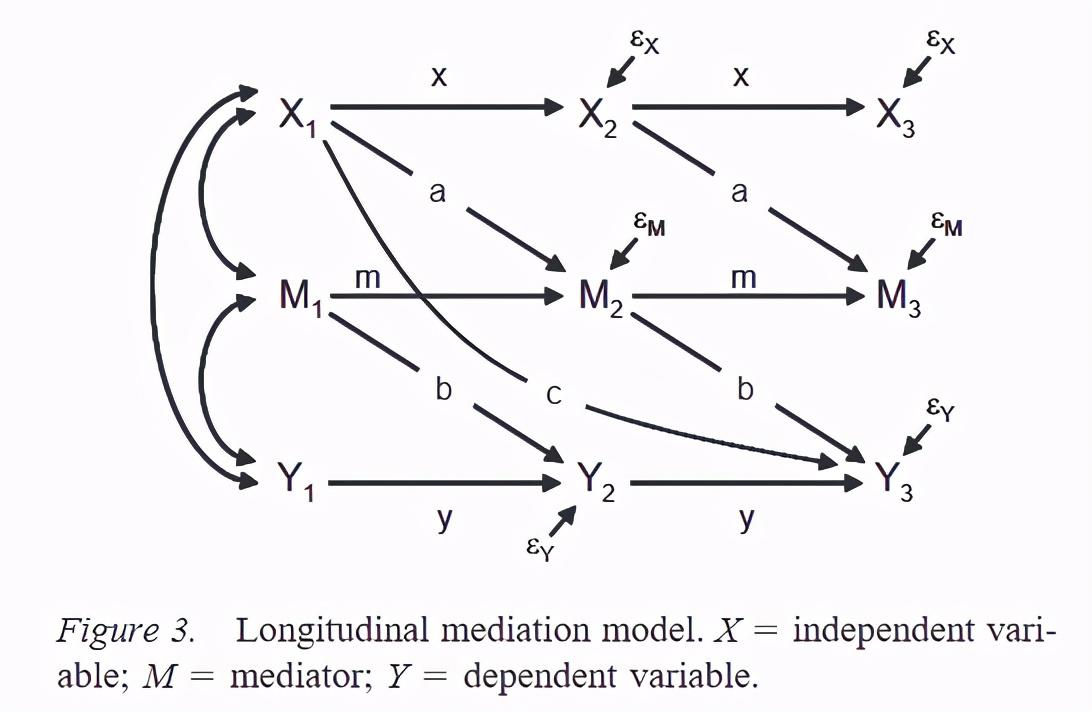
在做纵向中介的我们的数据最少是3波,期望检验的中介路径是x1到m2到y3,当然如果你比较猛,或者你们组比较猛,你还可以多整几波数据探讨中介效应的时间效应,本文不做展开。
treatment, mediator and outcome variables should be measured at three separated and ordered time points.
有同学问两波数据行不行?这个需要你自己考虑怎么来说服审稿人,比如你中介变量是时间不变的,那么你只要将自变量和因变量放在不同波次就行,我觉得也完全OK。
总之你自己自圆其说就完全没问题,本来是纵向设计,好多人完全拎出来横断面做中介人家也能发文章:
Another 10 (14%) ignored or abused the longitudinal structure of their own data by focusing on only a single wave,averaging across waves, or treating later variables as predictors of earlier variables when testing for mediation.
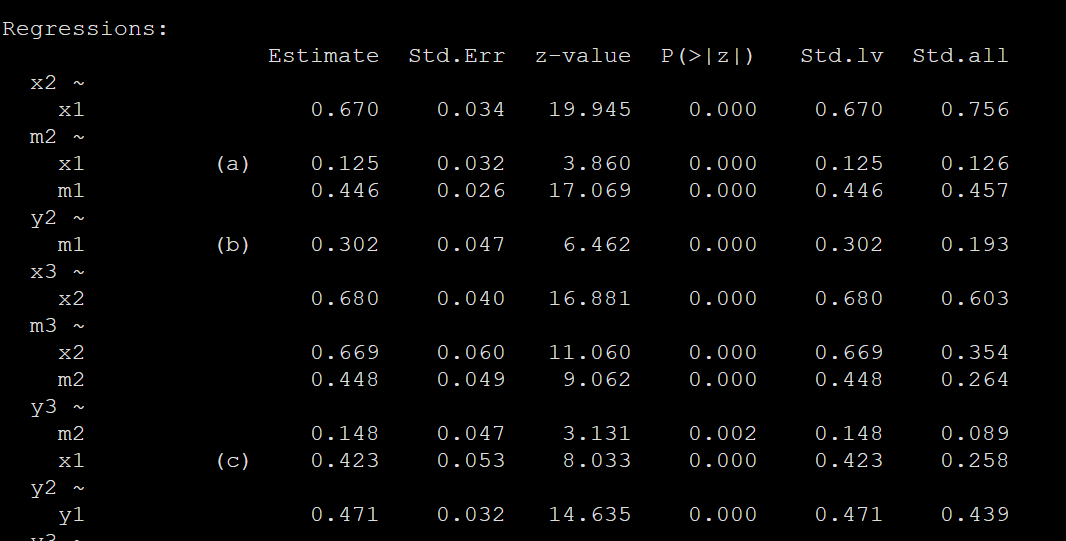
如果你是3波数据,中介出来的结构路径图就是开篇的第一张图。要报告的系数就是中介路径上的a,b,c,分别代表两个间接效应和一个直接效应。需要注意的是对间接作用的检验是检验ab的乘积,并非单单只看一条路径,这个是很多同学不太明白的地方。
The indirect effect is denoted by ab because it is often quantified by the product of two effects: the effect of X on M (a effect) and the effect of M on Y controlling for X
传统交叉滞后中介模型的做法实例
我的数据长这样哈,这个数据是我们自己模拟出来的,只是为了给大家说明数据形式,其中3波次的自变量x,3波次的中介变量m,和3波次的结局y,还有两个协变量z,只考虑人群均值而不考虑个体扰动,我们做一个交叉滞后中介模型,探讨在纵向设计中m是否中介了xy的关系:
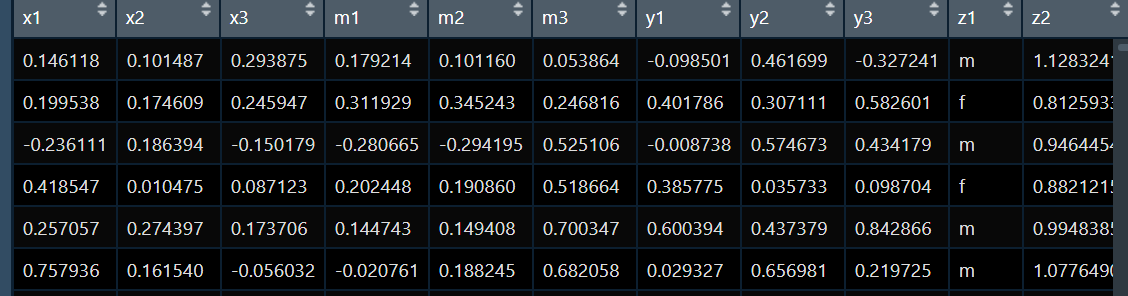
首先,我们加载相应的包并进行模型设定,代码如下:
CLPM <- '
# 路径系数
x2 ~ x1
m2 ~ a*x1
m2 ~ m1
y2 ~ b*m1
x3 + m3~ x2
m3+y3 ~ m2
y3~c*x1
y2~y1
y3~y2
x1+m1+y1~z1
x1+m1+y1~z2
# 相关
x1 ~~ y1 # Covariance
x1 ~~ m1
m1 ~~ y1
# 方差
x1 ~~ x1
m1 ~~ m1# Variances
y1 ~~ y1
x2 ~~ x2
m2 ~~ m2# Residual variances
y2 ~~ y2
x3 ~~ x3
m3 ~~ m3
y3 ~~ y3
# 间接作用 (a*b)
ab := a*b
# 总效应
total := c + (a*b)
'可以看到为了方便报告和中介效应分解,我还设定了系数标签,abc,和新的间接效应ab和总效应tatal,运行上面的代码,总结后即可输出模型结果:
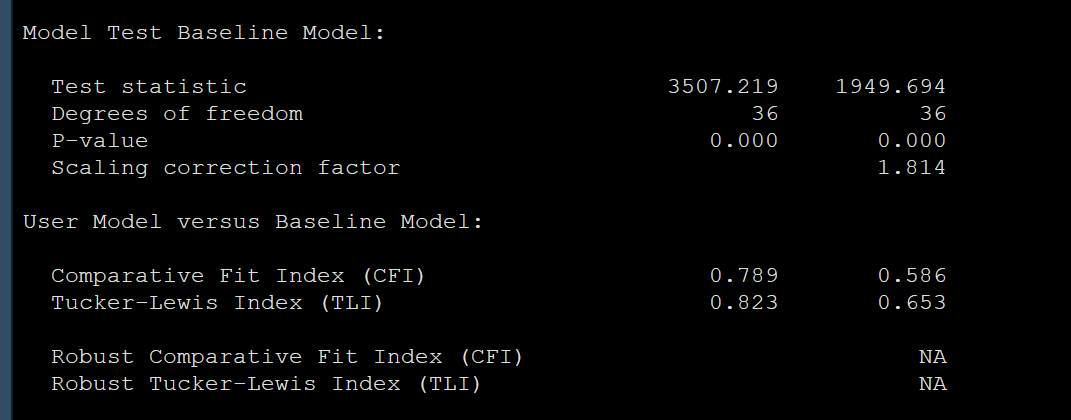
基本的模型优度如下,可以看到模型拟合是很差劲的,不过数据都是模拟出来的嘛,大家主要看方法就行:
各个回归系数如下(没有截图完整的)可以看到我们关心的系数abc都有标注:
当然还有间接效应和总效应的检验结果:

有了上面这些结果你就可以报告这就是一个部分中介模型了
另外再给大家分享一个出图的方法,之前我做结构方程一直用的semPlot出图,图不好个性化定制,乱糟糟的,最近发现tidySEM才是真的好用,比如就我上面的模型,写代码如下:
graph_sem(model = CLPM.fit)
lay <- get_layout("x1", "x2", "x3","m1","m2","m3","y1","y2",
"y3",rows = 3)
graph_sem(model = CLPM.fit,layout = lay)就可以出一个整整齐齐的图,见下图,简直跟发表的文献中一模一样哦,真好,强烈推荐给大家,之后有空出一期tidySEM的详细教程,快快点关注哈:
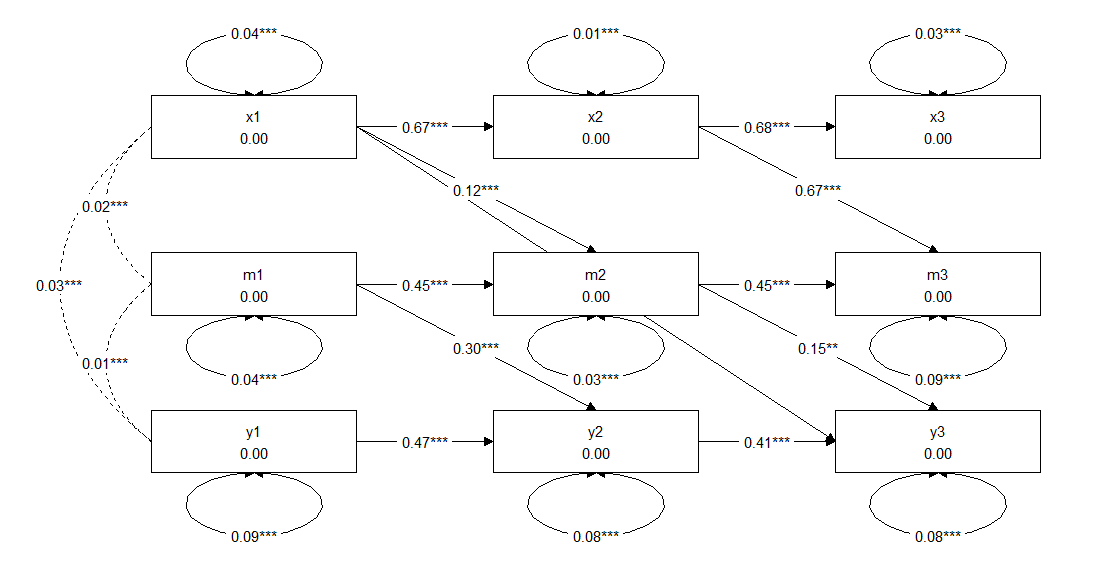
随机效应交叉滞后中介模型
关于交叉滞后和随机效应(截距和斜率)交叉滞后的区别之前文章有给大家写,如果要考虑个体间的变异或扰动,我们就需要给模型加上随机效应,此时就是随机效应交叉滞后中介模型。
为啥要考虑随机效应呢?因为本来个体残差异质性都是可能存在的嘛,如果我们做模型的时候不考虑,简单的认为人都是一样的水平,其实和你在嵌套数据中用了回归是一回事的,此时你的统计推断可能不准,注意是可能不准,如果你的人群确实都是一个样,那也就无所谓,你有这个意识就行,可能不准带来的后果就是也许你用交叉滞后回归没做出来阳性结果,然后你把变异分解的更好后用随机效应交叉滞后就出来阳性结果了。
random effects will cause heteroscedasticity in the residuals. Failure to take into account this heteroscedasticity can bias the standard error estimates, leading to misleading statistical inferences.
那么具体的随机效应交叉滞后中介模型如何做呢,其实就是在随机效应交叉滞后加上和上面一样的中介设定就行了,随机效应交叉滞后的代码在之前的文章中,这儿就不给大家写例子啦。
小结
今天给大家写了纵向数据的中介做法-----交叉滞后中介模型,这个模型考虑个体随机扰动就是随机效应交叉滞后中介模型,希望对大家有所启发。
感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请转发本文到朋友圈后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞分享。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦,另欢迎私信。
如果你是一个大学本科生或研究生,如果你正在因为你的统计作业、数据分析、模型构建等发愁,如果你在使用SPSS,R,Python,Mplus, Excel中遇到任何问题,都可以联系我。因为我可以给您提供最好的,最详细和耐心的数据分析服务。
如果你对Z检验,t检验,方差分析,多元方差分析,回归,卡方检验,相关,多水平模型,结构方程模型,中介调节,量表信效度等等统计技巧有任何问题,请私信我,获取详细和耐心的指导。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #Reports, #Composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...
往期精彩
R数据分析:ROC曲线与模型评价实例
R数据分析:用R语言做潜类别分析LCA
R数据分析:用R语言做meta分析
R数据分析:使用R语言进行卡方检验
R数据分析:如何用R做验证性因子分析及画图,实例操练
R文本挖掘:中文文本聚类
R文本挖掘:中文词云生成,以2021新年贺词为例
R数据分析:多分类逻辑回归
R数据分析:列线图的做法及解释
R数据分析:有调节的中介
R数据分析:混合效应模型实例
R文本挖掘:词云图怎么做,worldcloud2初识
R数据分析:随机截距交叉滞后RI-CLPM与传统交叉滞后CLPM
R数据分析:层次聚类实操和解析,一看就会哦
R数据分析:探索性因子分析
R数据分析:如何做逻辑斯蒂回归
R数据分析:交叉滞后模型非专业解释
R数据分析:逐步回归的做法和原理,案例剖析
R数据分析:非专业解说潜变量增长模型
R数据分析:竞争风险模型的做法和解释
R数据分析:中介作用与调节作用的分析与解释
R数据分析:生存分析的做法和结果解释
R数据分析:潜在剖面分析LPA的做法与解释






发表评论