
生成描述性统计信息:
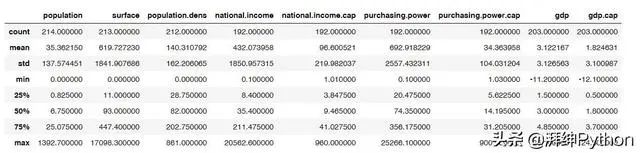
查看数据集结构的快速方法:
检查变量类型:

它们都是浮点数,但国家名称(字符串)除外。
显示摘要信息:
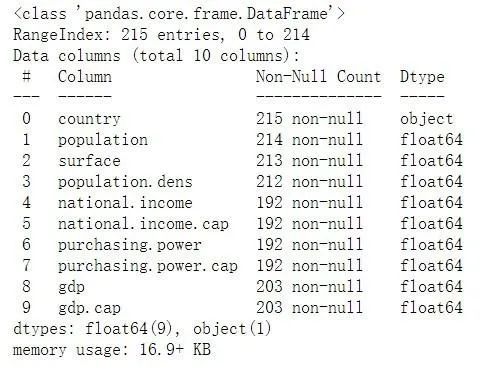
在这里,我们看到有些变量具有空值。
缺失值
缺失值可能是由多种原因引起的,例如数据输入错误或记录不完整。这是非常普遍的现象,会对从数据得出的结论产生重大影响。
上面我们已经看到,该示例中的数据集缺少几个值,但让我们看看如何测试任何数据集。
接下来,我们需要检查它们的数量:
现在,让我们再检查一下这些缺失值的摘要信息:
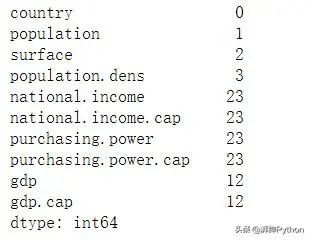
这是.info()函数的另一面。处理缺失值有不同的策略,而且没有通用的方法。
我们查看新的数据集:
在这里我们将删除缺失的值,并生成新的值。
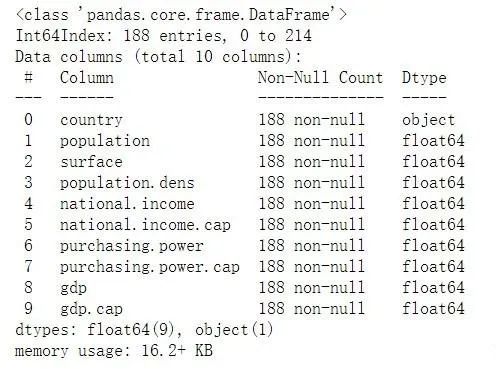
这里我们还剩余188条记录,没有空值。
可视化数据集
我们使用Seaborn可视化新数据集:
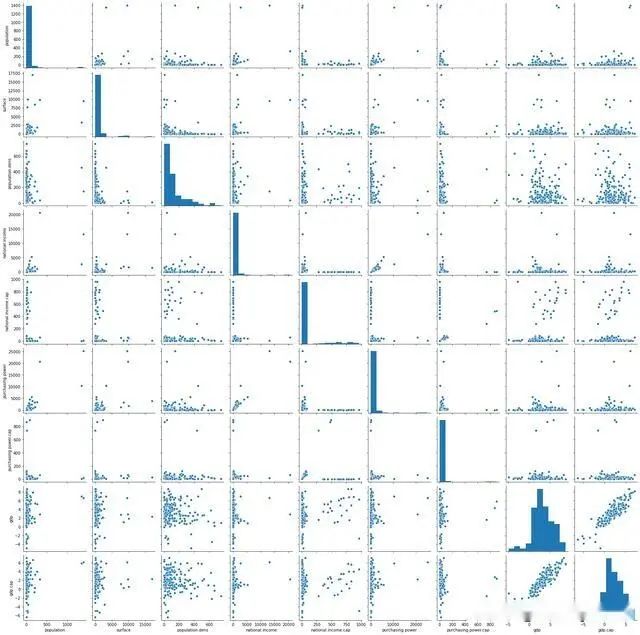
这样可以快速识别变量之间的异常值,聚类和明显的相关性。
我们再结合变量“gdp”和“population”
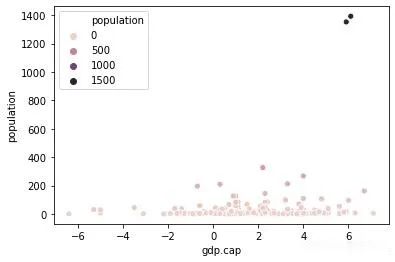
右上角有两个明显的异常值。与其他数据相比,有两个国家的人口水平非常极端。可以验证观察分析“population”变量本身:
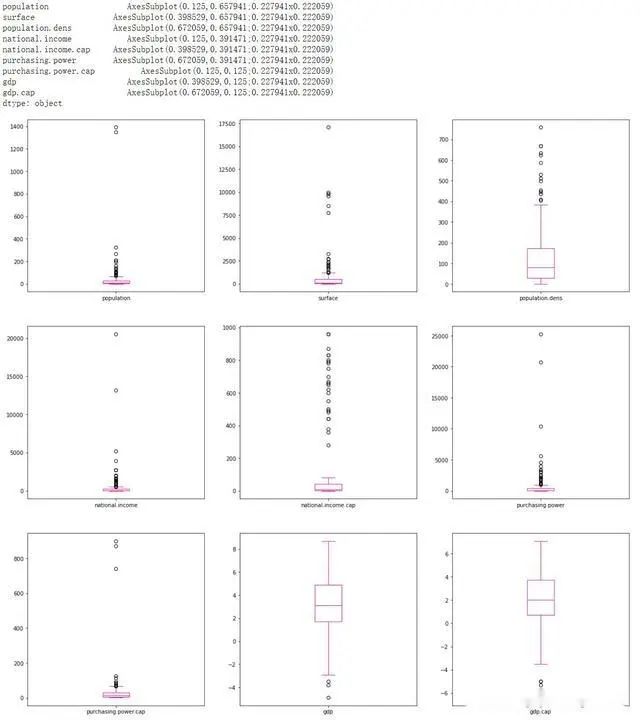
检测异常值的另一种方法是绘制一些箱形图:
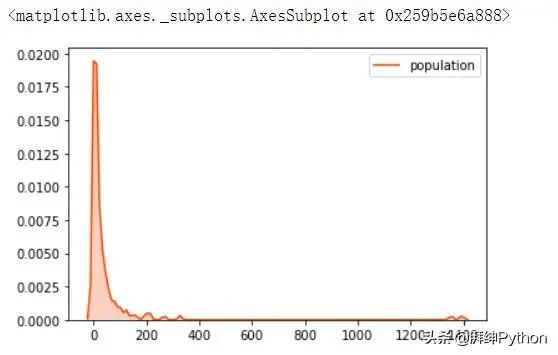
还可以显示这些变量的密度图并分析其偏斜度:
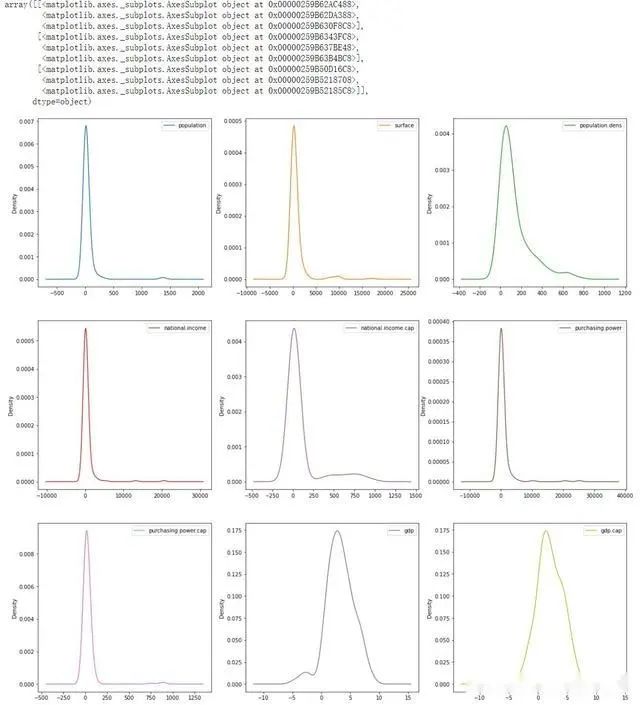
在这个例子中,我故意不处理离群值,但是有多种方法可以实现。
相关性
关联变量将为您节省大量的分析时间,这是对数据执行任何假设之前的必要步骤。相关性只计算数值变量,因此了解数据集中的变量类型很重要。
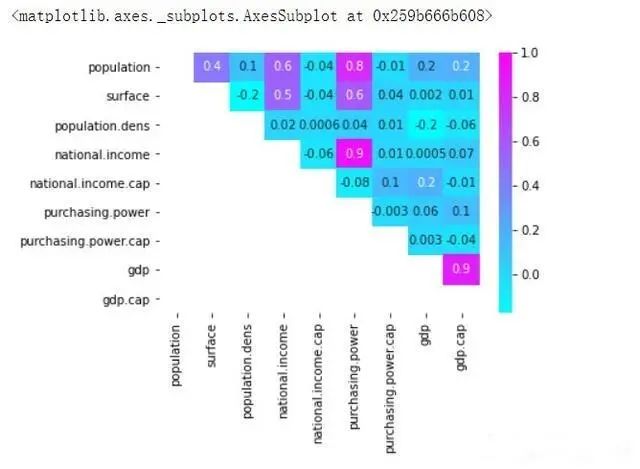
我屏蔽了左下角的值,以避免重复并提供更清晰的视图。右侧的值标度还提供了极值的快速参考指南:您可以轻松地发现变量之间的高低相关性。(例如“national income(国民收入)”与“purchasing power(购买力)”具有高度正相关)
结论
EDA对于理解任何数据集都是至关重要的。但是EDA需要做大量准备工作,因为现实世界中的数据很少是干净且同质的。人们常说,数据科学家宝贵的时间中有80%花费在查找、清理和组织数据上,而仅剩下20%的时间用于实际执行分析。

发表评论