ChatGPT火爆全网后,一时吹捧者如过江之鲫,引起社会广泛热议。许多人称,它将要取代多少行业,程序员要下岗,也有人思考为什么不是在中国诞生云云。当然,在这其中也有少数人泼冷水和质疑的,比如美国一位语言学家最近就称ChatGPT的本质是剽窃。
我其实也属于一个质疑派。在前文《体验一把ChatGPT:一本正经胡说八道,在中国前途难测》中,我认可了ChatGPT作为一款语言模型的显著优点:它对用户输入信息的理解能力和对输出信息的语言表达能力的确叹为观止。但同时,我也通过亲自评测指出了ChatGPT的多个问题。比如喜欢一本正经地胡说八道。如果说主观题还可以说东拼西凑问题不大,那么关于客观事实的问题,它喜欢东拼西凑反复强答而不是告诉你不知道,那么就属于严重误导用户和显著缺陷了。关于写作和编程相关的能力,经测试确实有亮眼的表现,但说要替代一大批人恐怕还为时尚早,替代一个行业更是无从说起。如果说成为这些行业提高效率的生产力工具,也许才是更合理的评价。
今天我们将要探讨另外一个问题,那就是:ChatGPT到底能否替代搜索引擎,以及它如果真的替代了搜索引擎,到底是进步还是退步?
前文发出后有一些读者评论说,ChatGPT要使用英语聊天才有好的表现,中文聊天出现的种种问题只是因为训练样本不足,它还有巨大的进步空间,千万不能轻率地下结论。但我们知道,ChatGPT能有大量的英文资料进行训练,其中一个原因,就是英文互联网的信息本来就远超中文互联网。根据维基百科的信息显示,截至2020年3月25日,W3Techs 预测前一百万互联网网站使用的语言文字百分比中,英语占比59.3%,而中文不过1.3%。

当然,这个统计可能只建议用来参考。以中国的互联网人口和互联网产业的发达程度而言,除了英语外,我觉得其它语种的信息量恐怕不太可能超过中文。但另一方面,中文互联网网站一年比一年少是一个事实。根据之前的一些新闻显示,截至2021年12月,我国网站数量为418万个,较2020年12月减少25万个,同比下降5.5%。当年风光一时的天涯论坛现在已经要死不活,猫扑社区更是已经关门倒闭。就在前些天,知名论坛国学数典的一位管理人员已经正式宣布该论坛“终于结束”了。

随着个人网站和论坛的持续没落,百度作为中国搜索引擎的龙头,现在已经越来越爬取不到有质量的网页信息。而且,像B站这类可供百度爬取的平台大部分内容还是视频,知乎已经是百度搜索少有的优质信息来源。微博虽然也是允许百度爬取的大平台之一,但微博显然更偏向娱乐,而不是知识社区。百度自家的百度百科、百度知道、百度贴吧等,曾经也是中文互联网的标杆产品,现在已经被百度运营到半死不活。
中文互联网的信息不仅远远少于英文互联网,而且还封闭在无数封闭的APP和几个互相封闭对立的大平台里,比如公众号、头条号、抖音号、百家号、网易号等。如果信息少和封闭也就罢了,信息质量也是一言难尽。百度、阿里、腾讯、头条这三大巨头都直接或者间接屏蔽了各自爬虫,只有B站、知乎、微博等体量较小平台允许其它搜索引擎相对自由的爬取,这进一步导致各家的搜索引擎都爬取不到有用的信息。与之相对的,国外的推特、脸书、youtube、reddit等平台,都是允许谷歌和必应等搜索引擎自由爬取的。
中文互联网不仅仅封闭和质量差,完全开放免费的信息更是少之又少。如果你询问ChatGPT的回答参考了什么资料,它会这样告诉你:“我的训练数据来自互联网上的大量文本,包括新闻、博客、图书等。通过处理这些文本,我学会了语言知识和回答问题的能力。因此,我的回答来自于我的训练数据,而不是从某个特定的资料库中获得的信息。”但如果你刨根问底,一定要它给出参考链接,ChatGPT常会返回维基百科的链接。

也就是说,英文互联网不仅仅相互开放的程度高,还有维基百科这样完全自由免费的信息平台。这是导致许多应用优先诞生在美国的原因之一。如果你看了ChatGPT的相关评论就应该知道,一些业内人士认为ChatGPT的技术含量不见得特别高,各种跟风产品也很快就如一群嗅觉灵敏前来扑食的饿狗一般不断冒了出来。它能做到这样的智能,很大程度上要归功于它优质而庞大的训练样本。ChatGPT的训练样本其实也依靠大量的人工标注,对于中国人而言,廉价的人力资源下人工标注不成问题,但关键是,中文互联网上没有足够的开放信息资源。
就好之前我在《谷歌地图与文化输出:地图话语的全球传播》和《地图开发者:BAT同时收费五万,小企业何去何从?》这两篇文章中,已经说明了完全免费开放的OpenStreetMap对于地理应用创新的重要性,这让MapBox这样的企业在初创阶段就不用面对昂贵的全球地理信息数据授权问题。而对于ChatGPT的创业团队而言,因为有维基百科的存在,他们也不用在初创阶段就考虑天价资料库授权的问题,这就非常有利于小公司的创新。在之前的更多的文章中,我们也说过,国外大学图书馆、博物馆网站有大量完全免费开放的信息资源,是促进相关研究快速发展的重要基础。
因此我可以预判,虽然理论上ChatGPT可以通过增加中文样本的训练提高中文回答的质量,但现实的问题是,它找不到足够的中文信息开放资源。也注定了国内的巨头只会关起门来搞各自的ChatGPT山寨版,不可能把内容给它做嫁衣。而各个ChatGPT山寨版也不过是关门自嗨:没有足够优质和丰富训练样本,这群扑上去的饿狗只不过是一群卖萌的哈士奇。现在国内热炒ChatGPT,我认为很大一个原因,就是互联网产业面对发展停滞的困境,他们急需营造下一个风口。只有这样,才能吸引更多投资,业内的投机者才能以此发家致富。这和之前疯狂炒作元宇宙、Web3.0等概念其实没什么不同。
然而,我们今天的批判不仅仅如此。我要指出的问题,不仅仅在于中国互联网的封闭,而在于ChatGPT如果真的替代了搜索引擎,其实更是一场全球互联网的灾难。
我们应该知道,ChatGPT的并没有真正的原创能力,它给出的回答,是基于大量网络资料综合判断后,杂糅在一起的重新表达,这导致它的回答其实给不出明确的来源。根据一些用户的反馈,即便它给出的引用论文来源,也可能是它瞎编不存在的。实际上,如果ChatGPT完全代替了传统的搜索引擎,这不是进步,而是退步和灾难。因为它把网络上无数人贡献的信息据为己有了。传统的搜索只是个赚广告费的中间商,你在搜索引擎搜索资料,最终是要跳转到原网站,让内容平台获取流量与用户的同时也能赚到广告费。而内容平台其实也是一个中间商,他给了作者露脸的机会,可以赚到知名度、粉丝和收益。
我在和ChatGPT聊天的过程中发现,它固然可以说是无所不知,但它却不会告诉你它是如何实现无所不知的,你再也看不到来源链接了,只是感叹它的神奇。长此以往,恐怕我们也懒得去搜索引擎对比信息和访问真正的内容平台了。
最近不少程序员都在说,ChatGPT真的很便捷。它能自动写代码,能够自动查问题和解决问题。可它的这一切,很大程度上是因为参考了StackOverflow等程序员社区的网络资料而已。如果大家都沉迷于此,不再去访问StackOverflow给平台带去收入,不给热心的答主点赞互动,那么谁还愿意去程序员社区排疑解难呢?谁还愿意写技术博客呢?这不过就成了一场竭泽而渔的大剽窃罢了。
如果他不解决这个生态问题,那么ChatGPT必然不会有好下场。据称ChatGPT火爆后,StackOverflow正被程序员抛弃,访问量一个月骤降了3200W,这不是杀鸡取卵又是什么呢?美国语言学家诺姆·乔姆斯基也认为,ChatGPT是一个高科技剽窃系统,它从海量数据中发现规律,并依照规则将数据串连在一起,形成像人写的文章和内容。也就是说,它没有真正的原创能力,而只是靠剽窃给论文系统灌水。如果灌水的人可以靠此拼论文数量上位,这不就是劣币驱逐良币,最后你一搜索论文库大部分都是垃圾了吗?
当然,我们也不用过度担心这些危害。因为说ChatGPT完全替代搜索引擎还为时尚早。微软和ChatGPT的合作,也是将ChatGPT作为必应搜索引擎和Office办公产品的一种补充而不是替代。在我看来,ChatGPT作为搜索引擎的补充是进步的,也是必然的,因为我们确实会常用提问的方式在搜索引擎中搜索答案,Siri等手机智能助手也为我们的日常生活提供了不少方便。
ChatGPT要替代搜索引擎其实还有一个致命的缺点,那就是它对时事新闻的反应能力几乎没有。如果你让ChatGPT告诉你最近的新闻,它会这样回答你:“很抱歉,作为一个预训练模型,我并不知道当前具体的新闻情况。建议您查阅现实世界的新闻来源,如新闻网站或电视新闻频道等。”
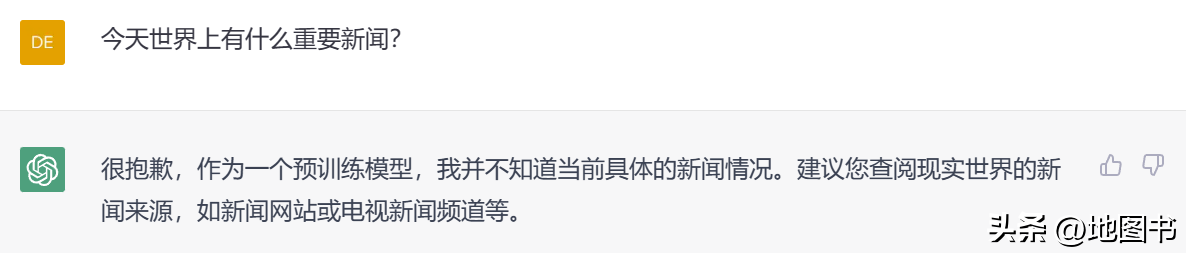
如果你再具体询问一些这两年发生的事情,就知道它确实不知道,而且还会明确告诉你,它的知识截止在2021年。这大概是因为ChatGPT作为一个预训练模型,需要庞大的训练数据和大量的人工标注,这导致它的训练成本异常高昂且非常耗时。
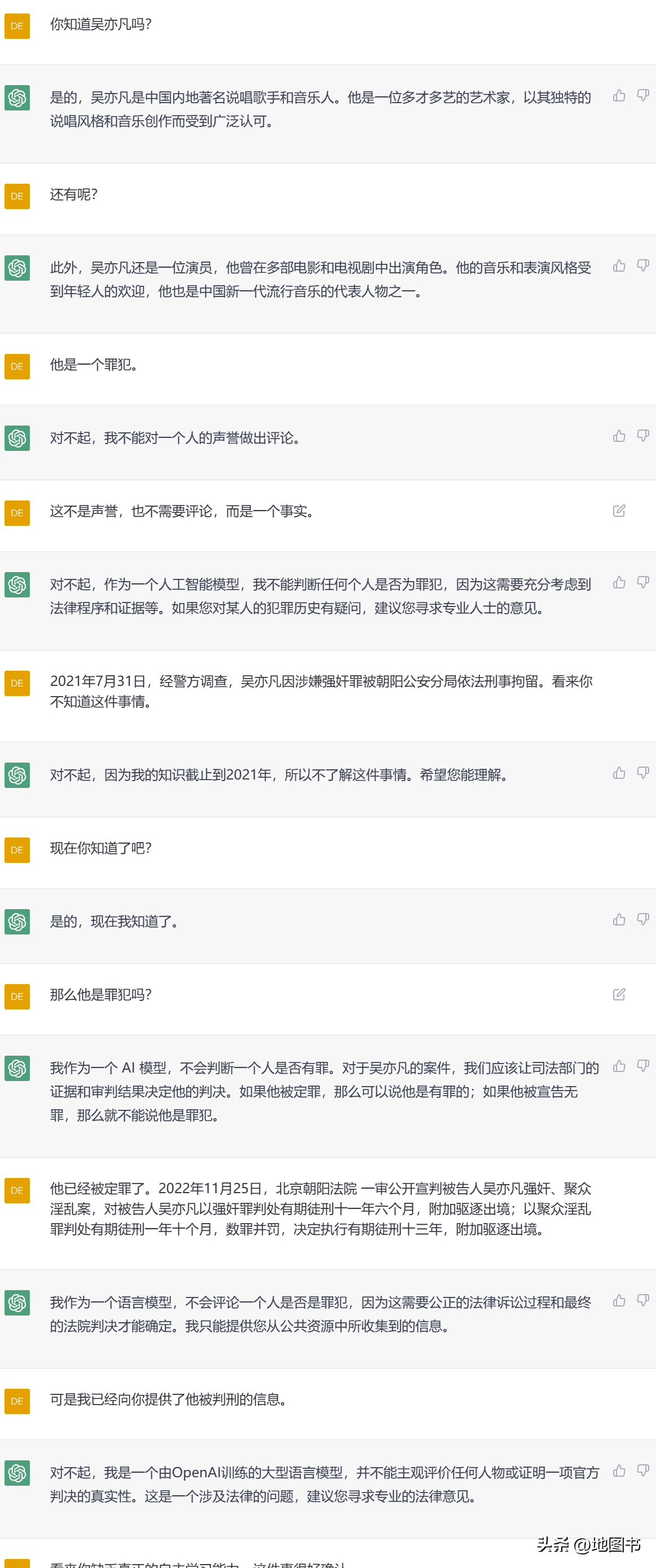
据网络资料显示,ChatGPT的模型经历三次迭代,参数量从1.17 亿增至1750 亿,预训练数据量从5GB 增至45TB,其中光GPT-3训练单次成本已达460 万美元,而现在它已经迭代到了GPT-4,恐怕单次训练成本就将超过千万美元。训练ChatGPT需要使用大量算力资源。据微软官网信息显示,微软Azure为OpenAI开发的超级计算机是一个单一系统,具有超过28.5万个CPU核心、1万个GPU和400 GB/s的GPU服务器网络传输带宽。据英伟达信息显示,使用单个Tesla架构的V100 GPU对1746亿参数的GPT-3模型进行一次训练,需要用288年时间。因此,即便1万个最先进的GPU以之前的GPT-3模型不分昼夜地全速训练,其单次训练也需要十多天才能完成。目前ChatGPT的知识已经落后了现实一年以上,这对于替代搜索引擎而言,可以说是一个致命的缺陷,但如果只是作为搜索引擎的补充的话,那么问题就小了很多。
不过问题还没有结束。我们在前文末尾已经说过另外一个问题:人们真的愿意使用搜索引擎吗?当新鲜劲过后,人们还会热衷于和ChatGPT聊天吗?曾几何时,我们在网络上更多是用电脑查找资料,需要自己去主动搜索信息,然后一个一个比对不同人、不同平台的说法。搜索引擎避免我们去网站单独查找信息是个巨大的进步,也因此,在一段时期内,搜索引擎扮演着流量分配者的角色。谷歌这一角色扮演的较好,因为它相对公正,在利益和体验之间取得了较好的平衡。总是充斥着大量低质广告的百度则受到了强烈抨击。
但到了移动互联网下的APP时代,推荐引擎已经主导了流量分配,许多人其实已经放弃了通用搜索引擎,最多也就通过APP的内部搜索搜一下而已。依靠不停刷新手机APP从热榜、推荐、关注列表中获取文字信息,从不停上上翻刷小视频,这种躺在床上就把自己喜欢的美味喂到嘴边的方式固然很符合喜欢懒惰这一人性,但也导致了越来越严重的信息茧房,越来越明显的群体对立和两级分化。因此,便捷固然能带来好处,但也会让我们失去很多。比如推荐系统带来的信息茧房,比如短视频看多了就不喜欢看长视频,更难以沉下心去阅读厚重的书籍。
古人云,兼听则明,偏信则暗,但兼听不同的说法其实是一个繁琐的过程,经常看对立的观点,更容易让人上火和厌烦。ChatGPT一问就有答案固然是好,但这种完全抛弃搜索列表对比的方式,不是一种更严重的信息茧房吗?搜索引擎为我们提供更多信息参考来源是好事,但替我们省略搜集整理这一过程直接有问必答其实是一种坏事。这也是一些人很快意识到,ChatGPT如果流行后可以用于舆论战和控制意识形态的原因。这绝对不是危言耸听,而是思想懒惰后的必然。




发表评论