身处大数据时代,每天接收到海量数据,例如高通量测序产生的一个样品的原始fastq文件就高达数十甚至上百GB,然而,对我们来说,真正感兴趣的只是最终产生的excel表格形式的数据。如何从这个excel表格中找到我们感兴趣的数据及规律似乎更加重要,因为这一步是“智慧的一步”,有助于我们更好地了解生物发生、发展的规律。
图1. 数据-信息-知识-见解-智慧
数据分析第一步:探索性数据分析,了解你的数据
当我们拿到数据(一般是excel表格)后,需要先对数据有个大概地了解,例如一般需要了解下:
1,每一列存储的是什么数据,是数值列(例如表达量fpkm)还是字符列(例如基因名)
2,数值列的数值范围是多少,最大值,最小值是多少,有没有缺失值
3,字符列有没有重复条目,最频繁出现的是哪个条目
4,数值列间是否存在相关性等等
pandas_profiling简介
工欲善其事必先利其器,pandas_profiling就是这样一款工具,pandas_profiling基于pandas的DataFrame数据类型,可以简单快速地进行探索性数据分析。
对于数据集的每一列,pandas_profiling会提供以下统计信息:
1、概要:数据类型,唯一值,缺失值
2、分位数统计:最小值、最大值、中位数、Q1、Q3、最大值,值域,四分位
3、描述性统计:均值、众数、标准差、绝对中位差、变异系数、峰值、偏度系数
4、最频繁出现的值,直方图/柱状图
5、相关性分析可视化:突出强相关的变量,Spearman, Pearson等矩阵相关性热图
并且这个报告可以导出为HTML,非常方便查看。
安装与使用
安装:
pip install pandas-profiling
使用:
# 导入相关库import pandas as pdimport pandas_profiling as pp# 读取数据集data = pd.read_csv(‘data.csv’, sep=’\t’)report = pp.ProfileReport(data)report.to_file('report.html')
让我们以表达谱表格为例,探索下这个包的神奇之处吧!

图2.表达谱示例数据
运行以上代码后,数据结果在report.html中
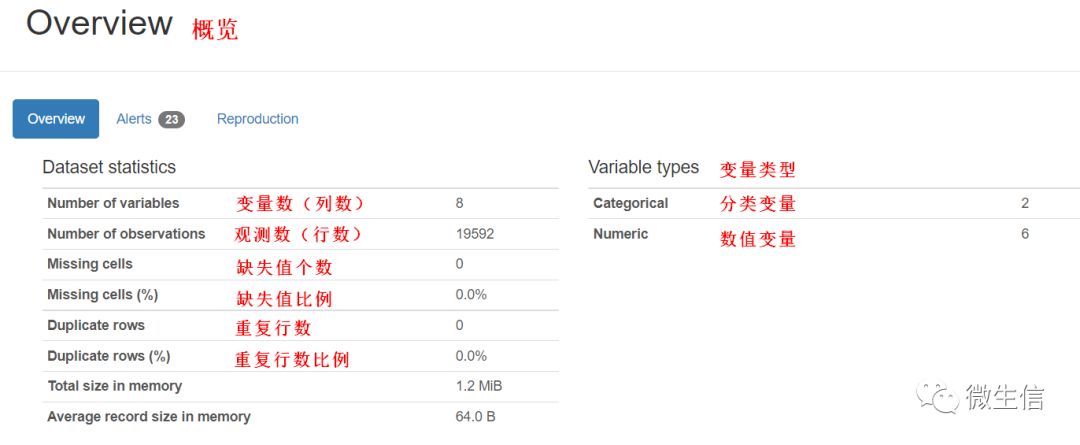
图3. 数据概览
总结了数据的基本信息,包括行数,列数,是否有缺失值等
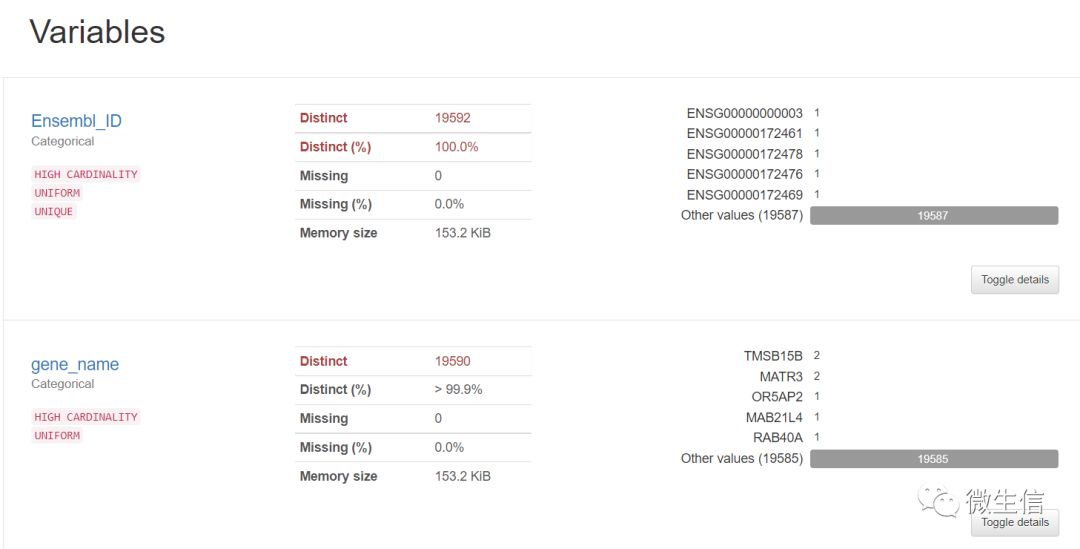
图4. 分类变量(前两列)的统计
我们的数据前两列是ensembl_id和gene_name,图4中提供了每个id的统计信息,包括distinct id的个数及比例,缺失值的个数及比例。从中可以看出,ensembl_id是唯一的,而gene_name是有两个重复的:TMSB15B和MATR3。

图5. 数值变量(最后6列)的统计结果
提供了缺失值个数及比例,inf个数及比例,平均值,最小值,最大值,0值的个数和比例,负值的个数和比例等,同时提供了histogram图等。点击“Toggle details”按钮可以看出数据详情,提供了更多的统计量,histogram,相同值的个数,极值等信息。
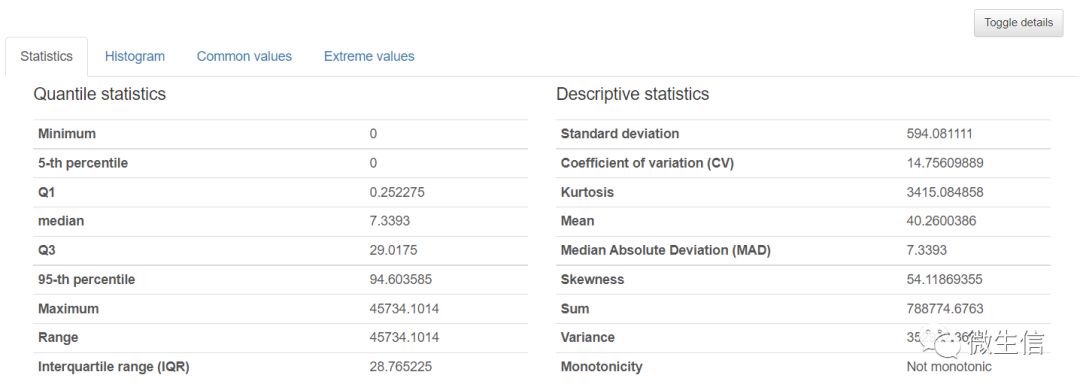
图6. sample1列的详细的统计结果
以上是针对单列的,同时还提供了多列的相关性信息及热图。包括Spearman、Pearson等,可以从总体上看出我们数据之间的联系。

图7. 数值变量相关性
最后,还提供了一些“Alerts”信息,也就是对各列的总结。
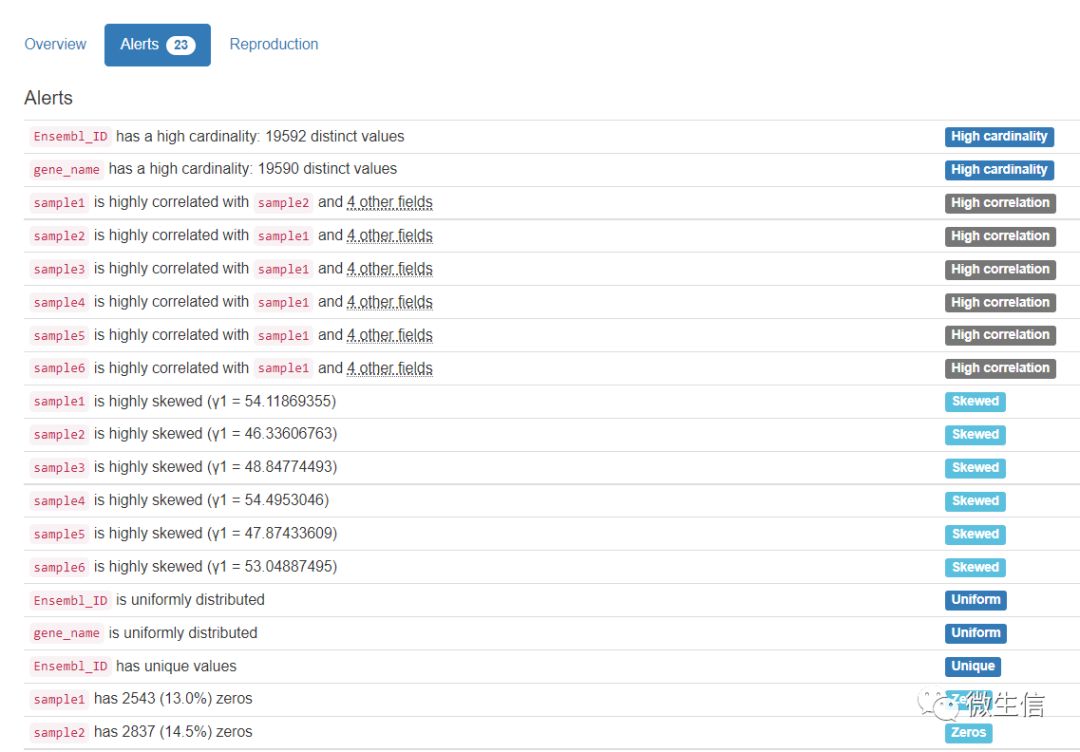
图8. Alert信息(部分)
熟悉python的小伙伴可以试试这个包,几行代码就可以对自己的数据进行探索性分析。微生信平台也提供了在线版本供大家使用,其目的是为了让大家更好地了解自己的数据,以便更方便地在微生信网站进行作图和分析。以带标注的火山图为例。首先我们使用pandas_profiling小工具检查下我们的输入。

图9. 上传页面
将右侧例子右键另存为txt,名字必须英文。
然后在左侧“选择文件”,点击提交按钮。约10s后会返回结果页面。

图10. 输出页面
下载并打开结果报告
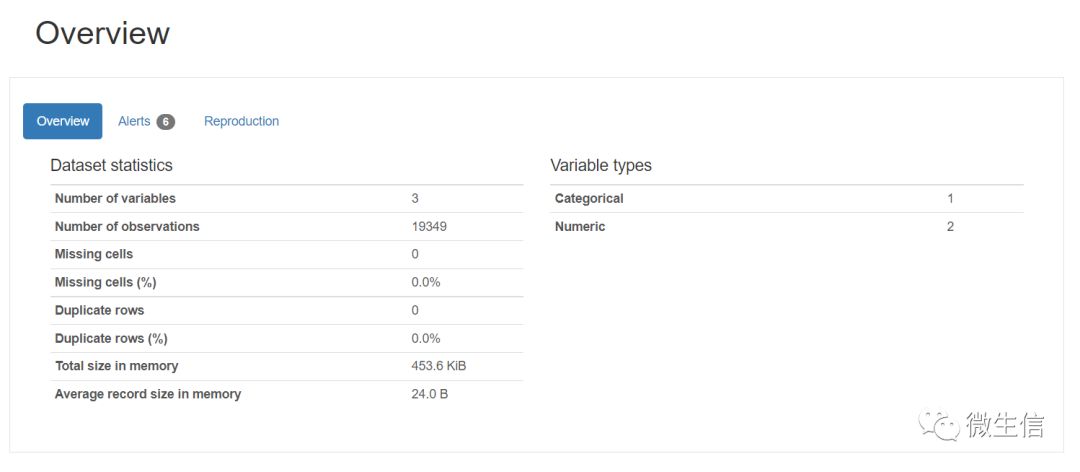
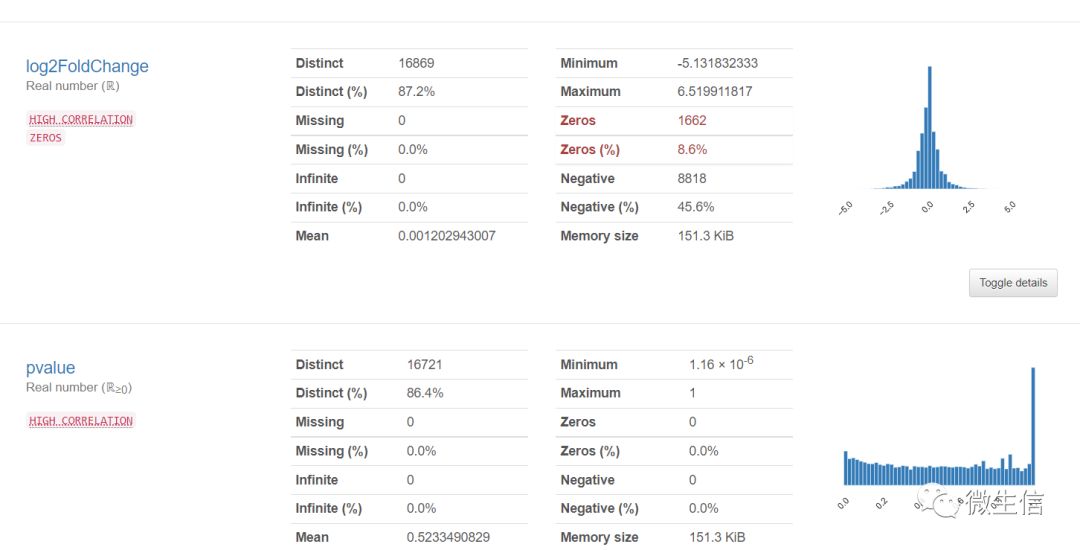
图11. 结果报告示例
该工具可以很方便地帮助我们检查数据中是否异常,例如基因名重复,p值>1等,如果有,则需要对数据进行校对后再进行绘图和分析。注:由于这个程序计算量较大,仅提供了粘贴方式的上传数据方式。感兴趣的小伙伴也可以试试本地python版,几行代码就可以对数据进行探索性分析。
微生信助力发文章,谷歌引用620+,知网引用450+

发表评论