
王小新 编译自 Medium
量子位 出品 | 公众号 QbitAI
找到马路上的车道线,对于人类来说非常容易,但对计算机来说,一点阴影、反光、道路颜色的微小变化、或者车道线被部分遮挡,都会带来很大的困难。
正在Udacity学习自动驾驶课程的Michael Virgo写了两篇博客文章,介绍了如何构建检测模型。
以下内容编译自他的文章:
在Udacity无人车纳米学位第一学期课程的五个项目中,有两个是关于车道检测的。
其中第一个项目介绍了一些基本的计算机视觉技术,如Canny边缘检测。

图1:Canny边缘检测
第二个项目深入介绍了一种方法,称为透视变换(perspective transformation),能将图像中的某些点延伸到目标位置。根据透视原理,车辆视角拍摄的照片上,车道线会在远方聚拢;而进行变换之后,我们会得到一张鸟瞰图。

图2:透视变换前后的图像
在遍历图像时,如暗色的道路变为亮色的车道线时,像素值会变化。在透视变换前,利用梯度和颜色阈值得到一张二值图像,当像素值高于阈值时设置为1。在透视变换后,可在该图像上运行滑动窗口,来计算特定车道线的多项式拟合曲线。
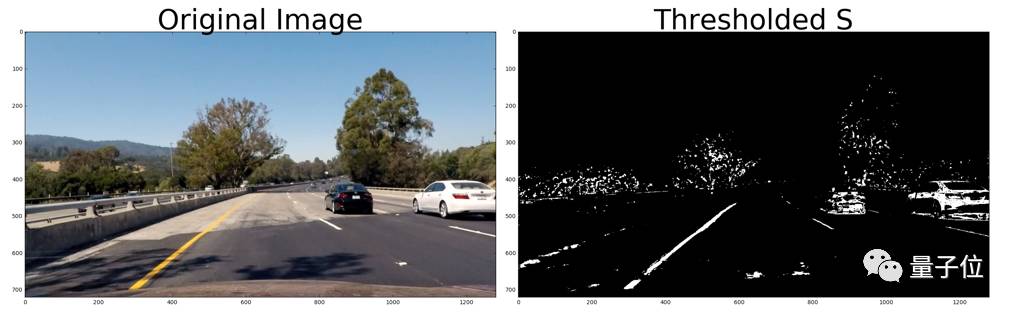
图3:阈值为S的二值图像

图4:原二值图像和透视变换后的二值图像
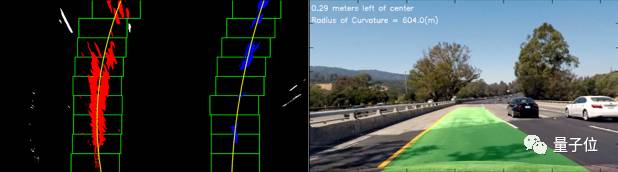
图5:应用滑动窗口的二值图像和输出结果
这种技术效果看起来不错,但实际存在很多限制。首先,透视变换操作会对相机有一些具体的要求,在变换前需要调正图像,而且摄像机的安装和道路本身的倾斜都会影响变换效果。其次,各种梯度和颜色阈值只在小部分情况下适用,故前面提到的计算机识别车道线的各种问题在这里变得更加突出。最后,这种技术处理起来很慢:实现车道检测功能的程序大约每秒能处理4.5帧(FPS),而汽车摄像头的帧数可能会在30 FPS或以上。

图6:车道检测出错的例子
我已经成功地应用深度学习技术完成了这两个车道检测项目,接下来我将对项目实现过程进行详细介绍。
创建数据集
虽然目前有大量用于训练自动驾驶技术的数据集产生,但大多数都没有对图像中的车道进行标注。我决定创建一个新的数据集,这是最关键的也是最耗时的一部分。为训练深层神经网络而针对性地创建新数据集,也是一个有趣且有意义的挑战。
收集数据是很容易的。在我住处的周围,有很多不同类型的道路可以开车去收集数据。根据我以往的项目经验,一个各类数据平衡的数据集非常重要。我收集了高速公路、辅路、盘山路、夜晚和雨天的数据。在这个过程中,我利用手机拍摄了超过21,000帧视频图像。
在提取出所有图片帧后,我注意到了一个问题:在亮度高且开车速度较慢时视频中的图像质量较高,在高速公路夜间驾驶和雨中驾驶时视频质量较为模糊,且这两种情景下的图像都存在很多问题。为了神经网络能更好地学习相关信息,我不得不检查和筛选每张图像。最终,训练集的图片数量减少到14,000张,但仍然存在一些轻度模糊的图像,希望不影响车道检测的效果。

图7:一张被删除掉的模糊图像,但是车道检测模型在该图像上的实际效果很好。
为了标注数据集,我用了自己原来做过的一个计算机视觉算法,不是在输出图片上标注预测的车道线位置,而是输出六个多项式系数,以二次函数Ax2+Bx+C的形式来描述这两条车道线。
但是,我希望深度神经网络能具有更好的效果,所以我决定统一使用红线来手动绘出真实的车道线,以便接下来可以使用红色阈值来更好地检测车道线。我最初以为需要处理14000张图像,但这将会花费太长时间,不切合实际;同时,如果在低速时多张相近的图像同时存在,则预测模型的准确率可能会虚高。考虑到时间对数据集的影响,我决定从每10张图像中抽取一张,从而创建了只具有1400张训练图像的原始数据集。
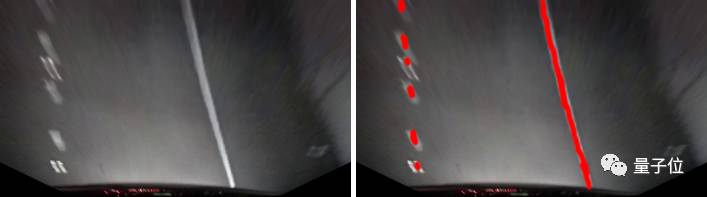
图8:由于最终的模型仍能在模糊的夜间图像中检测到车道线,看来这个方法提高了模型的鲁棒性。
此后,我根据以往项目做法创建了一个程序,在道路图像上使用了传统的CV检测模型,用拟合出的多项式,来重新绘制车道线。这种做法可以节省图像处理的时间,但在我检查实际效果时发现了一个明显的问题:虽然我已经用大量弯曲道路的图像来训练这个传统模型,但是仍然不能检测到所有的车道线。在训练集的1400张图像中,大约有450张无法使用,出现问题的样本主要是弯曲道路图像。
然而,我意识到这是由于算法的滑动窗口机制,导致这个模型本身存在问题。如果一条车道线在图像边缘停止了,原始的滑动窗口将沿着图像边缘垂直向上迭代,导致该算法相信该线往该方向延伸。我们可以通过判断滑动窗口是否触及图像边缘来解决这一问题,如果滑动窗口触及边缘,且已在图像里迭代若干步(这么设置是防止模型开始时被误判断触及边缘),那么滑动窗口就停止工作。
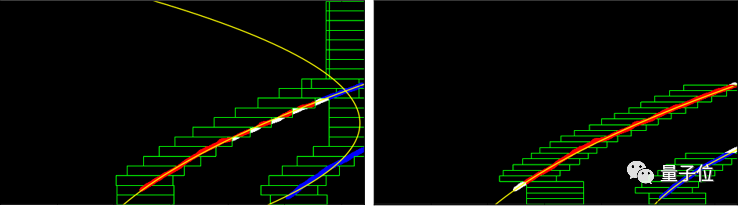
图9:在弯曲道路图像上建立一系列滑动窗口,前后处理效果对比
从图里看出,这个效果很好,故障率降低了一半,从原来的约450张减少到约225张。我想通过检查标签的实际分布情况来分析无法使用的剩下图像。我通过直方图来检查六个系数的实际分布,结果显示拟合曲线仍趋于直线。我还尝试增大弯曲道路图像的所占比例,但问题没有解决:对于极其弯曲的道路,检测出的车道仍然很笔直。
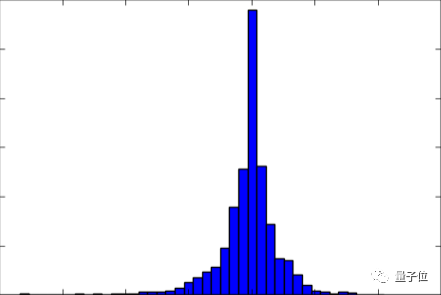
图10:一个车道线系数的分布图:明显以直线为中心。
我借用了以前参加过的一个交通标志检测项目的经验。那个项目的数据集中,有些类别图片非常少,我对它们进行小幅度旋转操作,增加了该类数据的比例,大大提高了准确率。
我再次使用这种方法,对于某一特定分布范围之外的任何系数标签,对图像进行小幅度旋转并同时保持相同的标签。对于其中的三个系数,我大约各处理了400、100和30张图像,部分图片可能进行了三次调整操作。
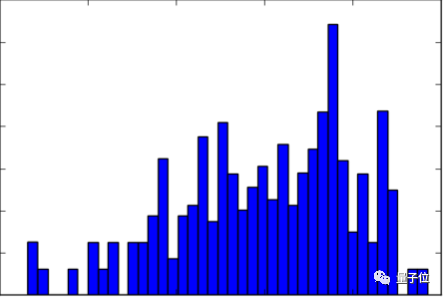
图11:对部分图像进行旋转后,单个系数分布更为均匀。
在旋转图像后,每个系数的分布更为合理。当然,我还对数据集及标签进行了一些快速预处理操作。训练集的图像从最初的720 x 1280以不同倍数缩小,并进行归一化,有助于模型加快收敛。我也使了用sklearn库中的StandardScaler函数来归一化图像标签,归一化时请确保保存缩放信息,因为在最后一步需要恢复操作。标签归一化后会降低训练时的Loss值,但是绘制回到原始图像后,最终的结果也提升不大。
引入深度学习
你可能会想,接下来不采用透视变换方法了么?是的,但是为了创建一个初始的模型结构,我想基于这个特定的数据集,将深度学习方法和传统CV检测模型的效果做对比。因此网络输入是做了透视变换后的道路图像,在逻辑上,神经网络可能更容易学习到相关参数。
在这里,我使用了一个与行为克隆(Behavioral Cloning)项目中类似的模型结构,包括一个批归一化(BN)层,接上多个卷积层、一个池化层、一个扁平层和多个全连接层。最终的全连接层的输出大小为6,也就是要预测的车道线系数数量。我还使用Keras库中ImageDataGenerator函数,主要通过旋转、偏移高度和垂直翻转来试图增强模型的泛化能力,因为水平翻转可能会误导网络去识别车道信息。经过对模型结构、超参数和输入图像大小的微调后,该模型的效果不错,但是对输入输出的透视变换操作极其依赖。总体来说,这个模型不能让我满意。
新的车道检测模型
当我发现深度学习方法在这个模型上效果不错时,我决定创建一个能在没有进行透视变换的前提下检测车道线的模型。我沿用了这个原来的结构,还添加了一个裁剪层,切除了输入图像的上三分之一。我认为,对于任何一张道路图像,这部分会包含很少关于车道检测的信息。而且该模型经过训练后轻松达到与透视变换模型相近的效果,所以我知道该模型的输入图像不必是经过透视变换后的数据集了。
在这一点上,我想将一些不同相机拍摄的额外数据输入该模型,以解决相机的扭曲问题,所以我还使用了一些从Udacity其他项目中获得的视频数据集。然而,我们需要为新数据创建对应标签,因为之前用于标记图像的透视变换方法不适用于这些视频。这也使我意识到了另一个大问题:图像标签本身就是鸟瞰图中的多项式系数,就意味着在预测和绘制车道线后,仍然需要反向变换,恢复到原始图像的视角。
这就导致了该模型具有特殊性,仅能在我录制的视频中查看车道检测效果。我意识到该模型也许已经能正确地检测车道,但是在后期预测中使用了透视变换,所以无法重现良好的视觉效果。我认为,该模型似乎在转换视角上存在困难,所以可以通过查看各层的激活情况,来判断该模型是否已经学会检测车道。
keras-vis的激活图
我很快找到了所需的keras-vis库。keras-vis库很好上手,只需将训练好的模型传给对应函数,就可以返回对应层的激活图。这个函数一般在分类神经网络中辨别各类特征,但在这里我用来可视化多项式系数。

图12:前几个网络层的激活图(请注意裁剪层处于这些网络层之前)
看到这些卷积神经网络处理后的道路图像,这是一件很有趣的事。虽然第一层的图像效果看起来不错,但是这种方法还存在一些问题。
首先,该模型在处理多张弯曲道路的图像后,得到了车道的一条线。该模型已经学习到,两条车道线之间存在联系,因为在大多数情况下,车道线是互相平行的,所以如果识别出一条线,那就可以推理出另一条线的所在位置。可能是由于使用过生成器翻转图像,所以在处理天空部分时激活值大幅变化。该模型会把图像中的天空误定位为车道,所以如果想在原始视频中标出车道,必须以某种方式删除这部分被错误激活的区域。

图13:可视化深层网络
第二个问题更加难解决。由于在弯曲道路的图像中倾向于对单车道线和天空区域进行激活,在笔直道路的图像中通常会激活图片底部的汽车本身,或者是汽车前方的区域,而不是标出车道的位置。我进一步增加了直道图像的数量,检测效果有时会变好。但是在弯道和直道之间,激活规律没有任何一致性,所以不能深入研究这种方法。
迁移学习
我还使用keras-vis库尝试了迁移学习(Transfer Learning)的方法。在之前的行为克隆项目中,我已经使一辆模拟车已经学会了根据训练好的神经网络呈现出的图像来引导自动驾驶。这个我使用了超过20,000张图像训练得到的模型,会怎么看待车道呢?

图14:一张模拟车的输入图像
这个问题的答案是整条道路,因为Udacity模拟器里没有隔离出多条车道,但是我想知道我是否可以使用迁移学习来将模型的注意力集中在车道上。我希望利用这个项目20000张数据集的基础上,添加一些用于车道检测的新数据,并进行一些额外的训练,希望能有更好的激活效果。在从该项目加载训练模型之后,使用model.pop()函数移除了最终用于输出转向角的输出层,并将其替换为输出六个标签系数。在训练前,需要根据模型的输入来调整输入图像的大小,否则不能正常运行。
经过一些额外的训练与输入自己的数据集,这个模型效果略有提升,从检测整个道路,开始转为识别车道线。但是,该模型仍然存在一致性问题,如哪些图像区域该被激活和对应的激活程度等等。
一种完全卷积方法
我感觉这些方法行不通,所以开始寻找一种新的方法。最近我看到一些小组在处理汽车拍摄的图像时采取图像分割的方法:将一个给定的图像分成如道路、汽车、人行道和建筑物等等多类对象。SegNet网络是一种很有趣的图像分割技术,在使用时可直接调用标准的模型结构。这种标准模型包含了带有BN层和Relu激活层的卷积结构、上采样层、池化层以及从中点到网络输出的反卷积层。这种方法没有添加全连接层,就能直接构建出一个完全卷积神经网络。
这似乎也是一个不错的方法,但是车道线可能还会以错误的方式被绘制,为什么不采用神经网络来直接预测车道线本身?所以我调整一下,网络的输入仍是道路图像,但输出为经过绘制的车道线图像。由于我是用绿线标出车道线的,我决定让模型的输出“过滤器”只对RGB的“G”通道起作用。对于RB通道,使用了两个空白过滤器,使相应图像与原车道图像结合。这种方法去除了水平翻转图像会对预测系数产生不良影响的担忧,也加倍了数据集的样本量。在使用这种方法预处理数据时,我可以同时翻转道路图像和车道图像标签。
图15:作为新标签的车道图像
在这里,我重新整理了数据集:
在原始数据集中有1,420张图像(在10帧中取1帧操作后),并删除了227个不能合适标注的图像;
在弯曲道路的视频中,一共有1636张图像,我从中挑选了568张图像;
在Udacity常规项目里给出的视频中,又挑出了另外217张图像;
上述总计1,978张图像;
样本量还太少,且各类分布不均匀,所以小幅度图像旋转后效果不好。在针对性调整后,得到了6,382张图像;
再次通过水平翻转,样本量加倍,得到了12,764张图片。
只要确保道路图像、系数标签和车道图像标签三者互相关联,我仍然可以旋转这些带有这些新标签的图像,无需考虑各系数的分布情况。
由于我从没使用过完全卷积神经网络,所以我按照SegNet网络结构来严格构建网络。幸运的是,我可以用Keras库快速构建,需要注意的是在添加反卷积层后,要确保网络输出图像和输入大小保持一致。在池化层之后,我将输入图像的长宽比调整为80 x 160 x 3(原始宽高比为90 x 160 x 3),并完全镜像前半部模型。因为所使用的池化层大小为2 x 2,如果输入维度为90,很快就不能被2整除,导致模型后半部分构建镜像时出现问题。
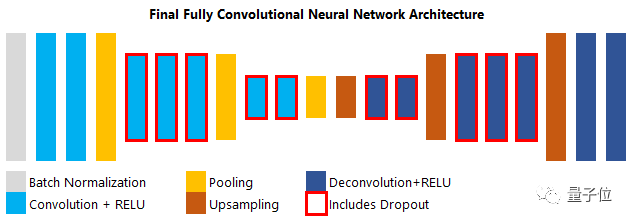
图16:SegNet网络结构示意图(从左到右)
在模型训练时存在一些小问题,网络过大导致内存溢出,所以我为每个卷积层和反卷积层添加了BN层和Dropout层,这是减小网络大小和防止过拟合的最有效方法。我在网络的开头设置了BN层,在网络中添加了Dropout层。由于只使用了“G”颜色通道,最终反卷积层的输出大小为80 x 160,这样更容易地与原始路面图像匹配。虽然我调小了输入图像,但是没有大影响。我也将道路图像标记除以255,进行归一化,这能改善收敛时间和最终结果,但是意味着在预测后需要对输出乘以255来恢复维度。

图17:不同模型的效果对比
从视频中可以看出,最终的预测效果不错。但是该视频已经被训练过,所以实际效果可能会虚高。为了检测实际效果,我们使用了车道检测项目中的另一个测试视频,发现该网络对这个视频的预测效果也很好。虽然在处理高速公路立交桥的阴影时存在小问题,但我们很高兴用这个视频证明了该模型的效果。此外,该模型比原有模型的处理速度更快,通常在GPU加速下每秒能处理25-29帧,实时可达到30 FPS。在没有GPU加速时,其每秒5.5FPS的处理速度仍然比每秒为4.5 FPS的CV模型稍快一些。

图18:传统的CV模型与SegNet模型做对比,在这里CV模型误认为两条车道线都在右边。改进方向
这就是我利用深度学习实现车道检测的全部过程。虽然不是很完美,但它比传统的CV模型更强大。我们也尝试在难度更大的测试视频中识别车道线,从结果中发现了一些问题:在光线和阴影的过渡时或者当强光照到车窗时无法准确预测车道线。以下是我接下来改进模型的一些方向:
更多数据集。这是应用深度学习方法很重要的一点,通过获取在不同条件下(如光线和阴影过渡时)和更多不同相机的数据,可以进一步提升该模型;
加入循环神经网络(Recurrent Neural Network)。我认为如果结合RNN网络强大的时间信息预测能力,这将是一个非常棒的方法。接下来我将研究递归方法在定位方面的应用,希望能在这方面再创建一种新的车道检测方法;
使用没有或只有一条车道线的道路数据集。因为在郊区或部分公路不会标记车道线,所以这种模型有更强的推广性;
扩展模型,用来检测更多的对象。类比于图像分割,可以添加车辆和行人检测的功能。上述模型只使用了“G”通道,接下来我们可以使用但不限于“R”和“B”通道,这种方法可能会优于常规的图像分割方法。
相关链接
该项目的完整程序请查看Github链接:
【完】
招聘
量子位正在招募编辑记者、运营、产品等岗位,工作地点在北京中关村。相关细节,请在公众号对话界面,回复:“招聘”。
One More Thing…
今天AI界还有哪些事值得关注?在量子位(QbitAI)公众号对话界面回复“今天”,看我们全网搜罗的AI行业和研究动态。笔芯~
")
发表评论