文来自datawhale8月组队学习数据分析入门
需要的使用平台及包:Jupyter Notebook,Numpy,Pandas
任务1:导包

任务2:载入数据

我们此次用的数据集是大名鼎鼎的泰坦尼克数据集,基本上每一次学习数据分析的朋友都仔细接触过或者研究过这个数据集,这个数据集在kaggle上可以自行下载kaggle.com/c/titanic/overview
pd.read_csv是pandas包里面自带的打开csv的工具,打开的数据格式会非常的整齐,会显示好行与完整的列的信息,如果用head()打开会默认是10行,此处设置成3,会显示3行信息如下。

这边提一下,我在平时工作学习中都习惯设成绝对路径,这样会给后面打开我的文件的同事或者队友提供方便,以防止因为路径不同意报错的情况。
任务4:将表头改成中文,索引改为乘客ID [对于某些英文资料,我们可以通过翻译来更直观的熟悉我们的数据

其实在pandas里面有很多的方法可以改变行的名字,比如
df.columns = ['乘客ID,'是否幸存',........]
df.rename(columns={'Name':"姓名", "Sex":"性别"},inplace = True)
但是很明显这个方法在这里略显麻烦……
然后打印一下可以看出来列名已经改正过来了

任务5:查看数据的基本信息
df.info() 打印数据基本情况

一般基本会打印出来这样的一个信息表,可以查看数据类型,还有数据的数量,通过这个数量其实可以看个大概分布,尤其是是否有null的情况,需要注意的是null不是0,是属于一个空置的状态,一般情况下需要将null的空值删除,不然会影响到后面统计数据分布或者画分布图。
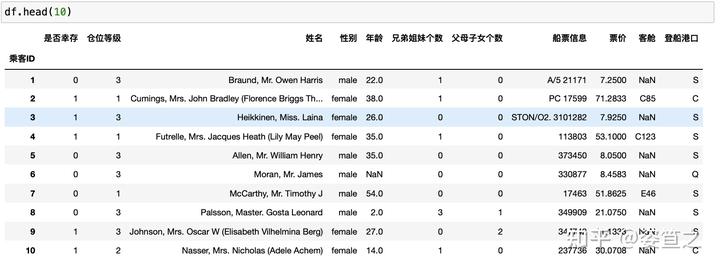
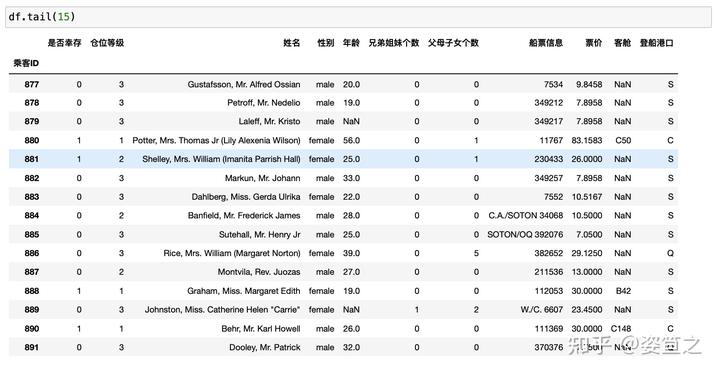
任务6:观察表格前10行的数据和后15行的数据
前面已经提到过了,这里不再重复。
head()打印前几行 tail()打印后几行,这里插一个比较有趣的现象,如果head不加括号打印出来的会是不整齐的表格,jupyter notebook默认没有括号的不是一个function,打印出来的是文本,自然而然就没有整齐的排版啦。
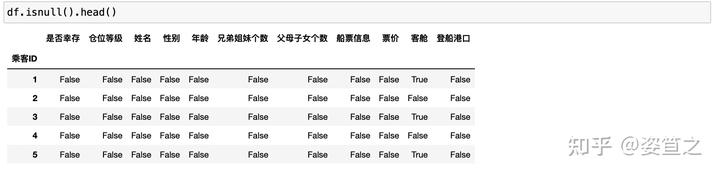
任务7:判断数据是否为空,为空的地方返回True,其余地方返回False
可以直接在dataframe上用is.null() 会返回false和true,true是表示这里有空值。
任务8:将你加载并做出改变的数据,在工作目录下保存为一个新文件train_chinese.csv
直接用pandas的build-in功能to_csv就好。

以上是一些简单的打开文件,查看数据,然后保存文件的简单操作,接下来我们会对pandas的包play around。
首先导入需要用的数据集

任务1:查看DataFrame数据的每列的名称
df.columns 查看。前面中涉及到的columns改变名字也可以通过这样的操作改变名字。

任务2:查看"Cabin"这列的所有值(有多种方法)

或者不需要大括号,直接的点好后面跟列名。

这里拓展一下,如果需要查询多个列的信息,需要多加一个大括号,如

下面加入一个新的数据集
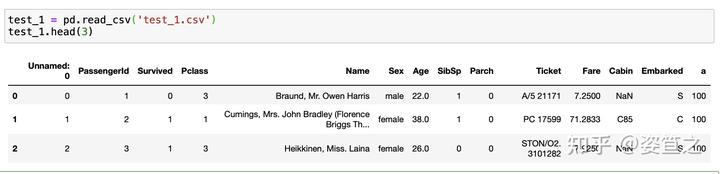
我们可以发现后面多出来了一列无用的“a”列,我们接下来把它删掉。
任务3: 将多出的列删除

除了直接用del来删除以外,因为pandas的灵活性,还有很多种方法可以删掉pandas的列
1)根据列的名字来删除
为了不影响原数据集,我重新定义了一个新的df1,用于演示和操作(虽然在实际生活工作中这个variable的名字不过关,但是这里就先将就一下吧 )
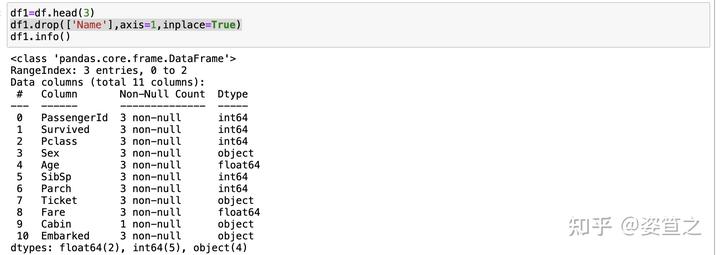
直接df1.drop后中括号加需要删除的列的名字,axis表示列的方向,inplace=True表示直接在数据集上做修改,如果你说,不我就是要inplace=false,也可以!就直接df2=df2.drop([“Name”],axis=1,inplace=False) 也可以达到一样的效果。
同样的,如果要删除的列大于一列,则需要多加一个中括号把他们都括起来,跟前面所提到的查询一样的操作,如下:
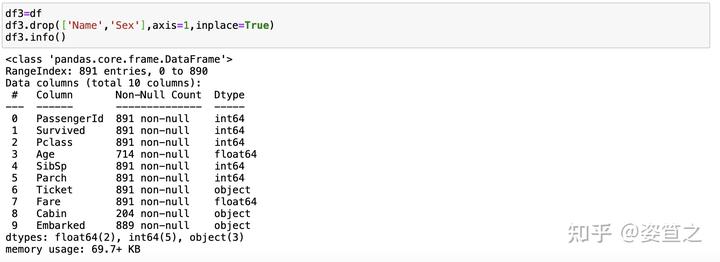
可以看到name的sex这两列已经没了,操作成功。
2)根据列的序号删除
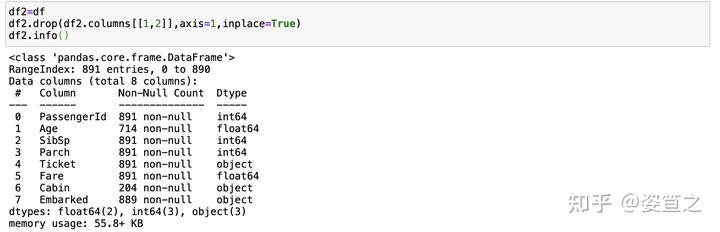
可以直接锁定一个或一个以上的列,区别在于是否加上那个中括号,更可以检索列,比如说从第0个到第三个

任务4: 将['PassengerId','Name','Age','Ticket']这几个列元素隐藏,只观察其他几个列元素
类似于过程的inplace的操作,现在只需要将这些发生的变化不作用于新的数据集就好

任务5:筛选列的满足的信息
比如说age列中,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
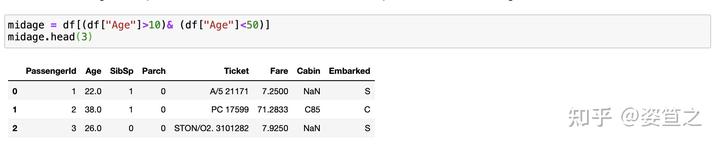
在df后面加上所有的条件,以&号连接,小括号将小的条件包起来,df["要搜索的列"]>需要满足的条件。
任务6:重新设置index

将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来

用loc检索,loc只针对列的检索
任务7:同样的方法使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来

iloc是针对行与列的检索,先出现行的检索,再列的检索
任务8:使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来


发表评论