
笔者邀请您,先思考:
1 如何对数据集做探索性数据分析(EDA)?
本文为了迭代一个探索性数据分析的通用模式,首先使用银行信贷数据进行探索性数据分析,希望能够得到一个通用的强大探索性解决方案。
数据导入
数据是来自klaR的GermanCredit数据.
1library(pacman)
2p_load(tidyverse,klaR)
3
4data(GermanCredit)
5GermanCredit %>% as_tibble -> df
把表格数据已经导入到df中了。
整体把握
为了最快速地知道: - 表格有多少行、多少列 - 表格的变量都是什么数据类型的 - 表格是否存在缺失值,如果存在,是如何缺失的 - 数据大体的分布
我们决定使用最便捷的函数。首先,DataExplorer包提供了一个快速仪表盘的生成,简单粗暴直接出报告,如果是Rstudio的用户能够马上得到一个report.html,在工作目录中生成。
1p_load(DataExplorer)
2create_report(df)
先用dlookr对表格进行审视。
1p_load(dlookr)
2
3diagnose(df) %>%
4 arrange(types) %>%
5 print(n = Inf)
1## # A tibble: 21 x 6
2## variables types missing_count missing_percent unique_count unique_rate
3##
4## 1 status fact~ 0 0 4 0.004
5## 2 credit_hi~ fact~ 0 0 5 0.005
6## 3 purpose fact~ 0 0 10 0.01
7## 4 savings fact~ 0 0 5 0.005
8## 5 personal_~ fact~ 0 0 4 0.004
9## 6 other_deb~ fact~ 0 0 3 0.003
10## 7 property fact~ 0 0 4 0.004
11## 8 other_ins~ fact~ 0 0 3 0.003
12## 9 housing fact~ 0 0 3 0.003
13## 10 job fact~ 0 0 4 0.004
14## 11 telephone fact~ 0 0 2 0.002
15## 12 foreign_w~ fact~ 0 0 2 0.002
16## 13 credit_ri~ fact~ 0 0 2 0.002
17## 14 duration nume~ 0 0 33 0.033
18## 15 amount nume~ 0 0 921 0.921
19## 16 installme~ nume~ 0 0 4 0.004
20## 17 present_r~ nume~ 0 0 4 0.004
21## 18 age nume~ 0 0 53 0.053
22## 19 number_cr~ nume~ 0 0 4 0.004
23## 20 people_li~ nume~ 0 0 2 0.002
24## 21 employmen~ orde~ 0 0 5 0.005
上面的结果首先显示出来的,是数据名称及其类型,其次发现基本没有缺失,最后是看数据中有多少独特的取值。 此外,我们还可以用skimr包。与上面的方法相比,这个方法会自动对数据类型进行分类,而且还会给出每一个独特的值的数量,对数值型变量会给出直方图分布示意图。
1p_load(skimr)
2
3skim(df)
1## Skim summary statistics
2## n obs: 1000
3## n variables: 21
4##
5## -- Variable type:factor --------------------------------------------------------------------------------------------------
6## variable missing complete n n_unique
7## credit_history 0 1000 1000 5
8## credit_risk 0 1000 1000 2
9## employment_duration 0 1000 1000 5
10## foreign_worker 0 1000 1000 2
11## housing 0 1000 1000 3
12## job 0 1000 1000 4
13## other_debtors 0 1000 1000 3
14## other_installment_plans 0 1000 1000 3
15## personal_status_sex 0 1000 1000 4
16## property 0 1000 1000 4
17## purpose 0 1000 1000 10
18## savings 0 1000 1000 5
19## status 0 1000 1000 4
20## telephone 0 1000 1000 2
21## top_counts ordered
22## exi: 530, cri: 293, del: 88, all: 49 FALSE
23## goo: 700, bad: 300, NA: 0 FALSE
24## 1 <: 339, TRUE
25## yes: 963, no: 37, NA: 0 FALSE
26## own: 713, ren: 179, for: 108, NA: 0 FALSE
27## ski: 630, uns: 200, man: 148, une: 22 FALSE
28## non: 907, gua: 52, co-: 41, NA: 0 FALSE
29## non: 814, ban: 139, sto: 47, NA: 0 FALSE
30## mal: 548, fem: 310, mal: 92, mal: 50 FALSE
31## car: 332, rea: 282, bui: 232, unk: 154 FALSE
32## dom: 280, car: 234, rad: 181, car: 103 FALSE
33## FALSE
34## no : 394, FALSE
35## no: 596, yes: 404, NA: 0 FALSE
36##
37## -- Variable type:numeric -------------------------------------------------------------------------------------------------
38## variable missing complete n mean sd p0 p25 p50
39## age 0 1000 1000 35.55 11.38 19 27 33
40## amount 0 1000 1000 3271.26 2822.74 250 1365.5 2319.5
41## duration 0 1000 1000 20.9 12.06 4 12 18
42## installment_rate 0 1000 1000 2.97 1.12 1 2 3
43## number_credits 0 1000 1000 1.41 0.58 1 1 1
44## people_liable 0 1000 1000 1.16 0.36 1 1 1
45## present_residence 0 1000 1000 2.85 1.1 1 2 3
46## p75 p100 hist
47## 42 75 ▇▇▆▃▂▁▁▁
48## 3972.25 18424 ▇▃▂▁▁▁▁▁
49## 24 72 ▇▅▅▃▁▁▁▁
50## 4 4 ▂▁▃▁▁▂▁▇
51## 2 4 ▇▁▅▁▁▁▁▁
52## 1 2 ▇▁▁▁▁▁▁▂
53## 4 4 ▂▁▆▁▁▃▁▇
一个比较好的可视化方法,是visdat包。
1p_load(visdat)
2
3vis_dat(df)
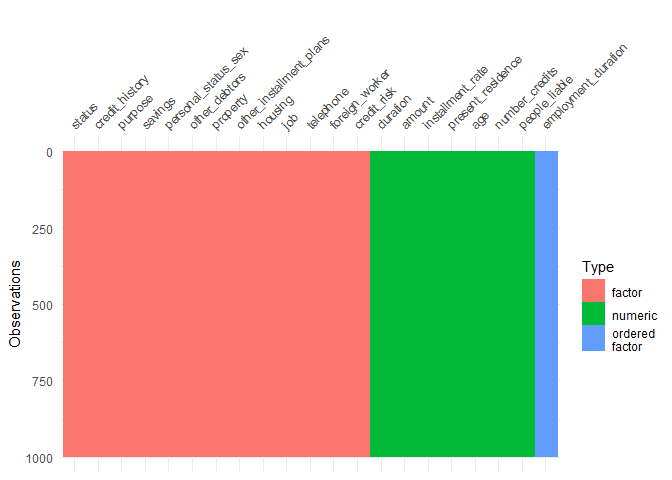
如果数据中有缺失值,也能够很好地展现出来,但是目前这里没有缺失值。
单变量数据分布
如果大家没有选择DataExplorer包的定制化数据报告服务,那么可以利用函数直接来看。
1p_load(DataExplorer)
2
3#数值型变量的分布观察
4plot_density(df)
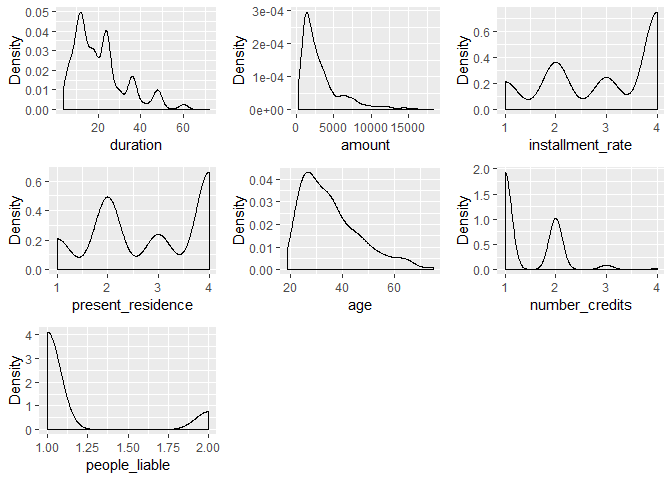
1#因子型变量的分布观察
2plot_bar(df)
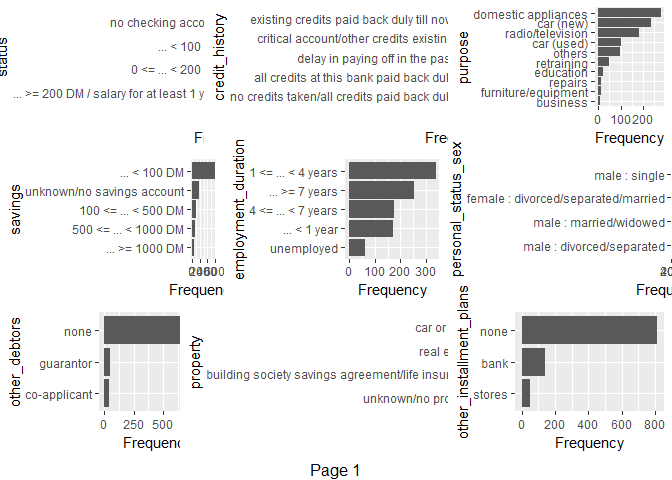
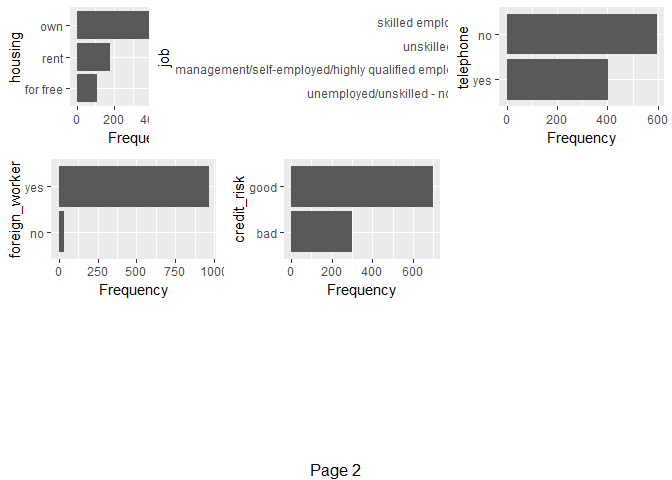
双变量数据分布
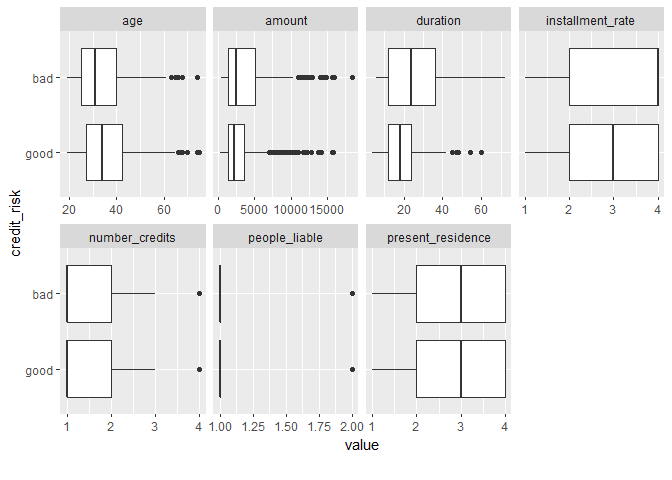
在这份数据中,响应变量是credit_risk,它代表着客户的守信水平,只有两个因子“Good”和“Bad”。我们想要看它和所有连续变量的关系。
1#响应变量为因子变量,因子变量与数值变量的关系,用箱线图表示
2plot_boxplot(df,by = "credit_risk")
如果想知道连续变量之间的关系,让我们做相关性矩阵图。
1p_load(dlookr)
2
3plot_correlate(df)
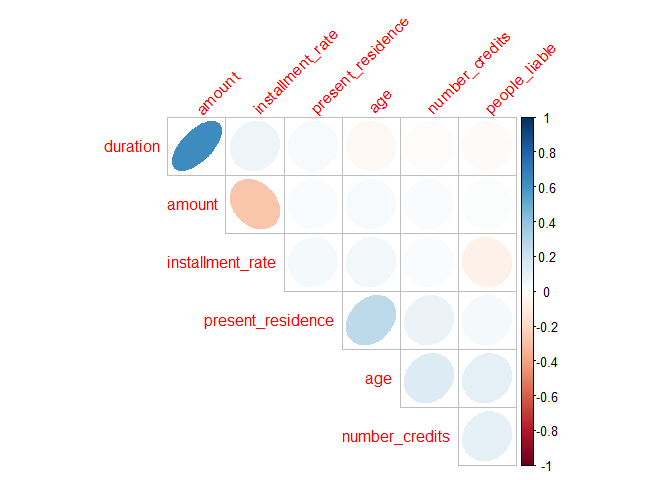
图中,越“椭圆”就越相关,蓝色是正相关,红色是负相关。如果连因子变量的相关性也想知道,那么就用DataExplorer包中的plot_correlation函数。
1plot_correlation(df)
它会把所有因子变量都用one-hot编码转化为数值型变量,然后做一个大的 相关分析矩阵。如果这不是你想要的,可以设置type参数,得到一个专门分析连续变量的图。
1plot_correlation(df,type = "c")
不过,想要同时获得相关性的信息,首推PerformanceAnalytics这个包。
1p_load(PerformanceAnalytics)
2
3df %>%
4 select_if(is.numeric) %>% #这种图只能看数值型变量的相互关系
5 chart.Correlation()
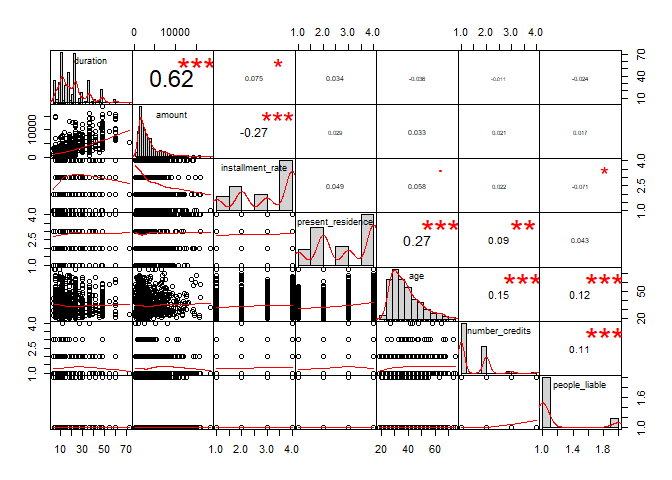
对于数值型变量,这种能够同时观察分布、相关系数和显著性水平的图,非常地有效。
离群值处理
为什么要进行探索性数据分析?一方面是要对自己的数据表格有一个大致的认识,从而增进商务理解和数据理解,为后续的分析奠定基础。另一方面,就是看看数据有没有出问题,如果有缺失值,那么肯定需要插补或者删除;如果有离群值,那么也需要决定究竟是保留还是删掉。 我们这份数据集是案例数据集,因此没有缺失值,不过离群点还是可以进行检测的。如果一个记录的某一数值远离其平均水平,那么认为这个记录是离群点。至于界定“远离平均水平”的标准,要视业务本身数据分布而定。经典的离群点检测法,是箱线图判断离群点的方法(统计学上称为Tukey's fences),这是基于单变量的。这个方法大家可以在维基查询到,网址为。很多R包默认的方法都是基于这个规则的,并可以自动删除、替代、设为缺失值。 发现离群点,要知道离群点背后的意义。比如我们的数据中,年龄这个变量有离群点,因为部分用户年龄过高,与平均值差距很大。但是这不是因为错误导致的,如果直接去除,也是不合适的。这样一来会减少信息的量,二来会忽视一些本来应该注意到的问题。离群点的寻找,一方面是为了想办法消除离群点给数据带来的影响,从而让我们的机器学习方法具有更强的鲁棒性;第二方面,其实可以找到这些离群值,然后对离群值进行一些详细的研究。很多欺诈的案例都是通过寻找离群点找到的,因为存在欺诈行为的用户,他们的行为会跟正常的用户有显著的差异。 在本案例中,我们首先要看哪些变量存在离群值。应该明确的是,分类变量是不会有离群值的,只有数值型变量才有探索离群值的意义。我们用dlookr的diagnose_outliers函数,来查看变量离群值的情况。
1diagnose_outlier(df)
1## # A tibble: 7 x 6
2## variables outliers_cnt outliers_ratio outliers_mean with_mean
3##
4## 1 duration 70 7. 50.5 20.9
5## 2 amount 72 7.2 10940. 3271.
6## 3 installm~ 0 0 NaN 2.97
7## 4 present_~ 0 0 NaN 2.84
8## 5 age 23 2.3 68.5 35.5
9## 6 number_c~ 6 0.6 4 1.41
10## 7 people_l~ 155 15.5 2 1.16
11## # ... with 1 more variable: without_mean
6个列中,第一列为变量名称,第二列是离群值个数,后面分别是离群值比例、离群值均值、包含离群值的全体的均值、去除离群值的全体的均值。因为installment_rate和present_residence变量不存在利群值,因此无法计算离群值的均值。我们看到people_liable是担保人的数量,其实它应该被认定为一个分类变量,因为它的取值只有1和2,所以如果对这个离群值做处理显然是错误的。 回归方法对离群值是敏感的,不过我们可以对变量先进行中心化、标准化,从而减少离群值的影响。如果想要得到整个数据质量报告,可以用dlookr的diagonse_report函数。
1diagnose_report(df)
小结
探索性数据分析的下一步,应该是数据预处理(特征工程)。如果不了解业务和数据,那么预处理就无从谈起。因此我们做探索性数据分析的时候,需要尽可能地观察数据的特点,并思考其背后的原因。一般来说,探索性数据分析需要知道一下几点:
总的来说,探索性数据分析就是对数据特征的挖掘过程,发现它们的特点,一方面加深我们对业务的认识,另一方面也防止明显的错误。以上均为个人对数据进行探索的一些方法,如果有更多探索性的方法,请各位大佬积极补充。希望能够最后迭代出一套较为通用的探索性数据分析方法,从而为广大的数据科学家带来便利。
内容推荐
数据人网:数据人学习,交流和分享的平台,诚邀您创造和分享数据知识,共建和共享数据智库。

发表评论